How to Evaluate LLM Outputs: Building an Evaluation Harness That Catches Real Failures

Key Takeaways
- An evaluation harness is the test suite for an LLM feature: a versioned golden dataset, a set of scoring functions, and a runner that produces a comparable score every time a prompt, model, or retrieval setting changes. Vibes-based spot checking is not an eval. It is a guess that feels like data.
- The failures that reach production are almost never the ones a few manual prompts in a spreadsheet would catch. They live on the long tail: the rare input shape, the adversarial user, the format drift that breaks a downstream parser. A harness exists to surface that tail before customers do.
- No single eval method covers everything. Deterministic assertions, reference-based scoring, an LLM acting as judge, and human review sampling each catch a different class of failure and miss a different class. The skill is matching the method to the task, not picking a favorite.
- The single most dangerous method is the LLM-as-judge used without calibration. It is fast, cheap, and confidently wrong in ways that correlate with the same biases the model under test has. Treated as a screen with a human-graded calibration set behind it, it is useful. Treated as ground truth, it manufactures false confidence.
- The payoff is regression safety. Once evals run in continuous integration against a frozen dataset, a prompt edit or a model upgrade that quietly degrades quality fails the build instead of shipping. That gate is what separates a measurable AI feature from a hopeful one.
Most Teams Are Flying Blind on LLM Quality
A common pattern repeats across organizations shipping their first language-model feature. The demo works. A handful of test prompts return good answers. The feature ships. Then the support queue fills with outputs that are subtly wrong, occasionally embarrassing, and impossible to reproduce because nobody recorded the inputs. The team patches the prompt, the new prompt fixes the reported cases, and two weeks later a different set of failures appears. There is no way to know whether the second prompt is better than the first, because there is nothing to measure against.
This is what shipping without an evaluation harness looks like. A model that answers ten hand-picked prompts well can fail badly on the eleventh, and the eleventh is the one a real user sends. The gap between "looked good on the cases I tried" and "works on the distribution of cases users actually send" is exactly where production failures live.
The fix is not more careful manual testing, which does not scale, is not reproducible, and gets quietly abandoned under deadline pressure. The fix is an evaluation harness: a system that turns quality from a feeling into a number you can track across every change. This article defines what that harness is, walks through its layers, explains how to build the golden dataset that anchors it, distinguishes offline from online evaluation, and shows how to wire it into continuous integration so quality cannot silently regress.
What an Evaluation Harness Actually Is
An evaluation harness is the automated test suite for an LLM feature. It has three parts: a golden dataset of representative inputs paired with what a good output looks like, a set of scoring functions that grade an output against that standard, and a runner that executes the model over the dataset and reports a single comparable score. When a prompt, a model version, or a retrieval configuration changes, the harness reruns and tells you whether quality went up, down, or sideways.
The word that matters is comparable. The point of the harness is not to prove an output is perfect. It is to let you compare version A against version B on the same inputs with the same scoring, so that "this change made things better" becomes a measurable claim rather than an opinion. Without that, every prompt edit is a coin flip dressed up as engineering.
A harness is not a public benchmark score. Public benchmarks tell you how a model does on someone else's task and say almost nothing about how it does on yours. Your harness measures your task, on your data, with your definition of correct, and that specificity is the whole value. The discipline here is the same one that separates working enterprise AI from stalled pilots, a point developed at length in the analysis of the AI agent patterns that actually ship versus the ones that stall, where a real evaluation harness is one of the four variables that decide whether a system survives production.
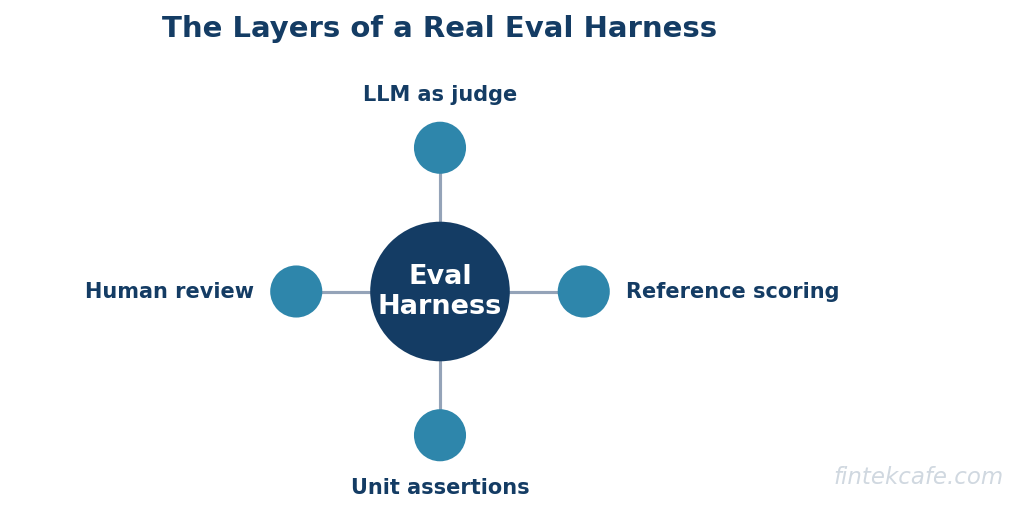
The Layers of a Real Harness
A mature harness is not one test. It is a stack of layers, each catching failures the others miss. The layers run from cheapest and most deterministic to most expensive and most subjective.
Unit-Level Assertions
The bottom layer is deterministic checks that do not need any judgment at all. Did the output parse as valid JSON? Did it contain the required fields? Is it under the length limit? Does it avoid a forbidden phrase? Does the cited identifier actually exist in the source document? These assertions are fast, free, and never flaky, and they catch a surprising share of real production failures, because the most common LLM failure in a structured workflow is not a subtly wrong answer. It is a malformed output that breaks the code downstream of the model.
Write these first. They fire the instant a model upgrade changes output formatting, which upgrades routinely do.
Reference-Based Scoring
The next layer compares the output against a known correct answer. For tasks with a single right answer, classification, extraction, routing, this is straightforward: exact match, field-by-field accuracy, or set overlap. For tasks where wording can vary but meaning should not, semantic similarity against a reference answer gives a softer score. Reference-based scoring is reliable precisely because it has a ground truth to compare against, which is also its limitation: it only works for tasks where you can write down what correct looks like in advance.
LLM-as-Judge
For open-ended tasks, summaries, explanations, drafts, conversations, there is no single reference answer, so the next layer uses a separate language model to score the output against a rubric. The judge is given the input, the output, and a scoring guide, and it returns a grade with a justification. This layer is powerful because it scales subjective evaluation to thousands of cases for very little cost, and it is dangerous for the same reason, which the next section covers in detail.
Human Review Sampling
No automated layer fully replaces human judgment. The top layer is a sampled human review: a person grades a small random slice of production outputs against the same rubric the judge uses. This serves two purposes. It catches failure modes no automated check anticipated, and it calibrates the LLM-as-judge by revealing where the judge and the human disagree. Human review is the most expensive layer, so it is sampled, not exhaustive, and it is targeted at the cases the cheaper layers flag as uncertain.
Regression Suites
Wrapping all of the above is the regression suite: the frozen set of cases that must keep passing. Every confirmed production bug becomes a permanent regression case, so the same failure can never ship twice. This is the layer that compounds in value over time. A harness that is six months old has absorbed six months of real failures, and that accumulated dataset is worth more than any prompt.
The LLM-as-Judge Trap
The LLM-as-judge deserves its own warning, because it is the layer teams reach for first and trust too much. Using one model to grade another feels elegant and scales beautifully. It also fails in specific, well-documented ways that produce confident, wrong scores.
The known failure modes are concrete. Judges show position bias: given two answers to compare, they favor the one shown first, regardless of quality. They show verbosity bias: longer, more elaborate answers score higher even when they are padded or wrong. They show self-preference: a judge tends to rate outputs from its own model family more highly. And they show rubric drift: vague scoring instructions produce scores that wander, so the same output graded twice can get different numbers. Worst of all, a judge often shares the blind spots of the model under test, so a hallucination that the generator produced confidently is one the judge confidently approves.
The fix is not to abandon the method. It is to treat the judge as a screen, not as truth. Calibrate it against a human-graded set and measure agreement before trusting it. Use a tightly specified rubric with concrete scoring anchors rather than "rate this from one to ten." Control for position by randomizing or by scoring each answer in isolation rather than in a pair. And keep a human review sample running permanently so that drift between judge and human is caught early. An LLM-as-judge that agrees with human graders eighty-five percent of the time on your calibration set is a useful tool. One that has never been checked against a human is a number generator. The underlying lesson, that the failure is in the system design rather than the model intelligence, mirrors the broader treatment of why AI agent frameworks break in production.
Building the Golden Dataset
Every harness is only as good as the dataset under it, and the dataset is where teams cut the corner that undermines everything else. A golden dataset is the set of representative inputs, paired with the expected output or the scoring rubric, that the harness runs against. Building a good one is the highest-leverage work in the whole effort.
The first rule is that the dataset must reflect the real input distribution, not a tidy sample of easy cases. The easiest way to build a useless dataset is to write twenty clean prompts that look like the demo. The fastest way to build a valuable one is to pull real inputs from logs, including the weird ones, the empty ones, the adversarial ones, and the ones in the wrong language. The long tail is the point. A dataset that omits the hard cases will give a high score and a false sense of safety.
The second rule is to stratify deliberately. The dataset should oversample the categories that matter most or fail most: edge cases, known-hard inputs, regulated or high-stakes scenarios, and the adversarial prompts that test safety boundaries. A dataset that is ninety percent easy cases will be dominated by the easy cases in its average score, hiding failures on the ten percent that actually carry risk.
The third rule is that the dataset is a living asset, versioned like code. Every production failure becomes a new case. Every model upgrade is a reason to review whether the dataset still represents reality. A dataset of a few hundred well-chosen, well-stratified cases beats a dataset of ten thousand random ones, because curation is what makes a score meaningful. Curating and maintaining this asset needs a defined owner, which is one reason it tends to live with the data and ML function rather than being orphaned across teams, as covered in the guide to how to structure a modern data team.
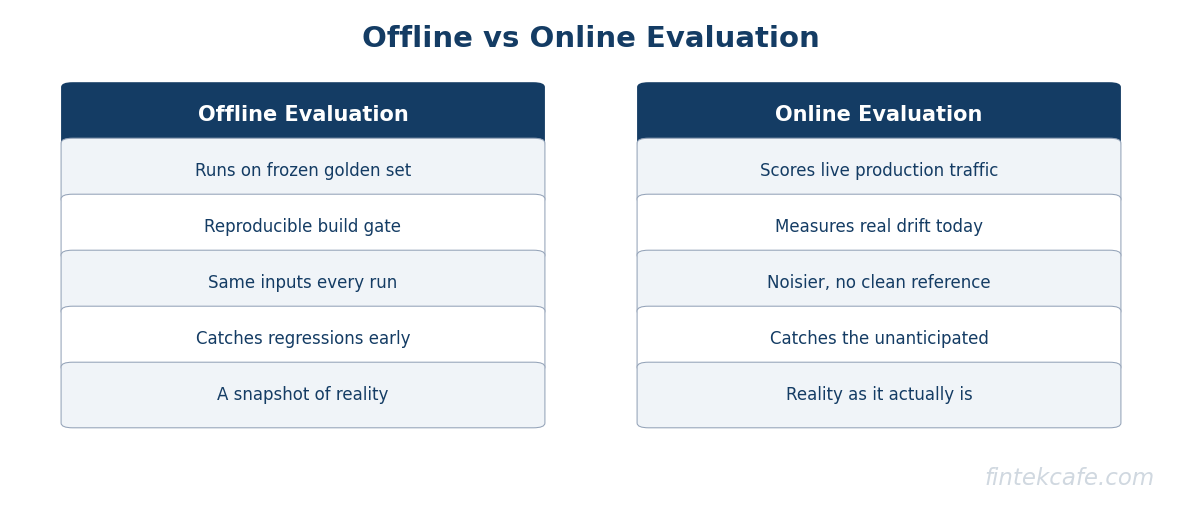
Offline Versus Online Evaluation
Evaluation happens in two settings, and a complete program runs both.
Offline evaluation is the harness run against the frozen golden dataset before anything ships. It is reproducible, it is fast, and it is the gate in development and continuous integration. Its strength is control: the same inputs, the same scoring, every time, so you can attribute a score change to the code change that caused it. Its weakness is that the dataset is a snapshot, and reality drifts away from any snapshot.
Online evaluation measures quality on live production traffic after the feature ships. It includes scoring a sample of real outputs with the same automated layers, tracking user signals like thumbs-up rates, edit distance between a drafted output and what the user actually sent, task-completion rates, and escalation or retry rates. Its strength is that it measures the real distribution as it actually is, today, including the drift that offline misses. Its weakness is that it is noisier and lacks a clean reference answer for most cases.
The two are complementary. Offline catches regressions before they ship; online catches the failures the dataset did not anticipate and feeds them back as new golden cases. A program with only offline evaluation drifts blindly after launch, and one with only online evaluation learns about every regression from its users. You need both.
Which Eval Method Fits Which Task
The methods are not interchangeable. Each fits a task shape and misfits the others.
| Task type | Best primary method | Why | Watch out for |
|---|---|---|---|
| Classification, routing | Reference-based, exact or field match | Single correct label, fully checkable | Label ambiguity in the dataset |
| Structured extraction | Unit assertions plus field-level reference match | Output schema is verifiable field by field | Format drift after model upgrades |
| Summarization | LLM-as-judge with rubric, human-calibrated | No single reference, quality is multidimensional | Verbosity bias, missing-fact errors |
| Open-ended generation, drafts | LLM-as-judge plus human review sampling | Subjective quality at scale, human anchor | Self-preference, rubric drift |
| Retrieval-augmented answers | Reference match on cited facts plus faithfulness judge | Must check both retrieval and grounding | Confident answers from wrong sources |
| Safety and policy compliance | Deterministic rules plus human review | High stakes, low tolerance for misses | Adversarial inputs not in the dataset |
The pattern in the table is that bounded tasks lean on cheap deterministic and reference-based methods, and open-ended tasks lean on judges backed by human calibration. The mistake is using a judge for a task that has a checkable reference answer, which trades a reliable score for an expensive and noisier one, or using exact match for a task where wording legitimately varies, which fails good outputs for trivial differences.
This is the same kind of fit-the-tool-to-the-problem judgment that governs the upstream architecture choice. The decision of whether to fine-tune, retrieve, or extend context, laid out in the framework for fine-tuning versus RAG versus long-context, determines what your system even does, and your eval methods then have to match the failure modes that choice introduces. For retrieval-heavy systems in particular, the faithfulness question, did the answer actually come from the retrieved source, is the failure mode that matters most, and the mechanics of why are covered in the explainer on how retrieval-augmented generation actually works.
Wiring Evals Into Continuous Integration
A harness that runs only when someone remembers to run it is a harness that stops running. The discipline that makes evaluation real is wiring it into continuous integration so that quality is a build gate, not a good intention.
The pattern is straightforward. The golden dataset and scoring functions live in version control alongside the prompts and the application code. A change to a prompt, a model version, or a retrieval setting triggers the harness as part of the test pipeline. The harness produces a score, and the pipeline compares that score against the baseline from the main branch. If the score drops below a defined threshold, the build fails, exactly as it would for a failing unit test. The deterministic assertion layers run on every change because they are fast and free. The expensive layers, the LLM-as-judge passes, run on a schedule or on a sampled basis to control cost.
This gate is what makes model upgrades safe. When a provider releases a new model version, the temptation is to swap it in because it benchmarks higher. Benchmarks are not your task. With evals in continuous integration, the upgrade runs against your golden dataset before it ships, and a model that is better on average but worse on your specific high-stakes cases fails the gate instead of silently degrading the feature. The same gate catches the prompt edit that fixes one reported bug while breaking three unreported behaviors, which is the most common way prompt changes go wrong.
A practical starter sequence keeps the effort proportional: begin with the deterministic assertion layer and a small golden dataset of fifty to one hundred real cases, add reference-based scoring for the checkable parts, introduce an LLM-as-judge only after you have a human-graded calibration set, and add online evaluation once the feature is live. Each step is independently useful, so the program delivers value before it is complete, and its cost stays anchored to the cost it prevents, the same logic that governs spending on the real cost of AI infrastructure.
A Starter Checklist
Before an LLM feature ships, an organization should be able to answer yes to each of these. A no on any line is a known gap, not a detail.
- A golden dataset of representative real inputs exists, including edge cases and adversarial inputs, and it is versioned in source control.
- The dataset is stratified so high-stakes and known-hard cases are not drowned out by easy ones in the average score.
- Deterministic assertion checks run on every change: schema validity, required fields, length limits, forbidden content, citation existence.
- Reference-based scoring covers every part of the task that has a checkable correct answer.
- Any LLM-as-judge has been calibrated against a human-graded set, uses a concrete rubric, and controls for position and verbosity bias.
- A human reviews a sampled slice of outputs on a recurring schedule, and disagreements with the judge are tracked.
- The harness runs in continuous integration and fails the build when the score drops below the baseline threshold.
- Online evaluation tracks live quality signals, and every confirmed production failure becomes a new permanent regression case.
The organizations that get durable value from language models are not the ones with the most sophisticated prompts. They are the ones that can change a prompt, swap a model, or adjust retrieval and know, with a number, whether they made the product better or worse. That capability is the evaluation harness, and it is the difference between an AI feature you can improve on purpose and one you can only hope about.
FAQ
What is an LLM evaluation harness?
An LLM evaluation harness is the automated test suite for a language-model feature. It pairs a versioned golden dataset of representative inputs with scoring functions and a runner that grades the model's outputs and reports a single comparable score. When a prompt, model, or retrieval setting changes, the harness reruns and tells you whether quality improved or regressed, turning quality from a subjective impression into a tracked metric.
How is LLM-as-judge different from human evaluation?
LLM-as-judge uses a separate language model to grade outputs against a rubric, which scales subjective evaluation to thousands of cases cheaply. Human evaluation uses people to grade outputs, which is slower and more expensive but catches failures automated methods miss. The two work together: humans grade a calibration sample, and the judge is trusted only to the degree it agrees with those human grades. A judge that has never been checked against humans should not be treated as ground truth.
What is the difference between offline and online LLM evaluation?
Offline evaluation runs the harness against a frozen golden dataset before shipping, giving reproducible, controlled scores that gate development and continuous integration. Online evaluation measures quality on live production traffic after shipping, using sampled scoring and user signals like edit distance and task-completion rate. Offline catches regressions before release; online catches the real-world failures the dataset did not anticipate. A complete program runs both and feeds online failures back into the offline dataset.
How big does a golden dataset need to be?
A few hundred well-chosen, well-stratified cases usually beat tens of thousands of random ones, because curation is what makes the score meaningful. Start with fifty to one hundred real inputs drawn from logs, including edge cases and adversarial inputs, and grow the set by adding every confirmed production failure as a permanent case. The dataset is a living asset that should reflect the real input distribution and be versioned alongside the code.
How do evals prevent model upgrades from breaking things?
With the harness wired into continuous integration, a new model version runs against your golden dataset before it ships. A model that benchmarks higher in general but performs worse on your specific high-stakes cases fails the build gate instead of silently degrading the feature. The gate compares the new score against the baseline and blocks any change, a prompt edit or a model swap, that drops quality below the threshold.
Related reading on FinTekCafe
Related Articles

The AI Headcount Illusion: What Agents Actually Do to the Org Chart
Agents rarely shrink payrolls. They convert doing-work into checking-work, and winning org charts are redesigned around that conversion, not headcount.
The Total Cost of AI: A Framework for Pricing an AI Initiative End to End
An eight-line total cost of ownership framework for enterprise AI, with a worked example, realistic cost shares, and a build-buy-wait decision table.

AI Governance: How to Build an AI Policy That Actually Gets Followed
Why AI policies fail as documents and work as controls: a three-tier governance model, ownership patterns, EU AI Act duties, and metrics that matter.