Fine-Tuning vs RAG vs Long-Context: A Decision Framework for Enterprise LLM Customization in 2026

Key Takeaways
- Three customization patterns now compete for the same enterprise AI budget: parameter-efficient fine-tuning (LoRA, QLoRA), retrieval-augmented generation, and the new million-token long-context window. The vendor pitch for each obscures the actual decision, which is rarely about which pattern is best in the abstract.
- The cost shapes are not comparable. Fine-tuning has a high training cost amortized over many queries. RAG has a moderate per-query retrieval overhead plus an LLM bill. Long-context has the highest per-query token bill of the three. The pattern that wins depends on traffic volume, refresh frequency, and how often the underlying knowledge changes.
- Latency profiles invert the cost story. Fine-tuned models are the fastest at inference because no retrieval step runs. RAG adds retrieval latency. Long-context adds context-processing latency that scales with how much you stuff into the window. For latency-sensitive flows the order is fine-tune, RAG, long-context.
- Governance and audit are where most enterprise programs trip. Fine-tuned models bury knowledge inside opaque weights. RAG keeps knowledge in a database that can be queried, versioned, and access-scoped. Long-context shows the knowledge in the prompt but offers no persistent record. Regulated industries default to RAG for this reason.
- Hybrid is the right answer more often than executives expect. RAG plus light fine-tuning for tone and format wins for most production deployments past pilot. Long-context augments RAG when a small set of always-relevant policy documents needs to sit in every prompt. Treating the three patterns as exclusive is the single most expensive framing mistake.
Why Three Patterns Coexist
Eighteen months ago the customization conversation was binary. Fine-tune the model on internal data, or build a retrieval-augmented generation pipeline. The arrival of frontier models with million-token context windows added a third option that some teams now treat as the default: skip the customization, stuff the entire knowledge base into the prompt, and let the model do the work.
Each pattern has a vendor with an interest in selling it as the obvious choice. Model labs sell long-context as the simplest path because it locks revenue to the token bill. Embedding and vector-database vendors sell RAG as the only governable pattern because it sells their products. Fine-tuning platforms sell the training run as the high-leverage option because their pricing depends on it. The enterprise buyer hears three confident pitches that each promise to make the others obsolete.
None of the three pitches survive contact with a production workload. The real decision is multi-dimensional and the right answer is often that two of the three patterns operate together. A useful baseline for any customization decision is to understand how large language models actually work, because the pattern choice flows directly from how the underlying model treats parameters versus prompt versus retrieved context.
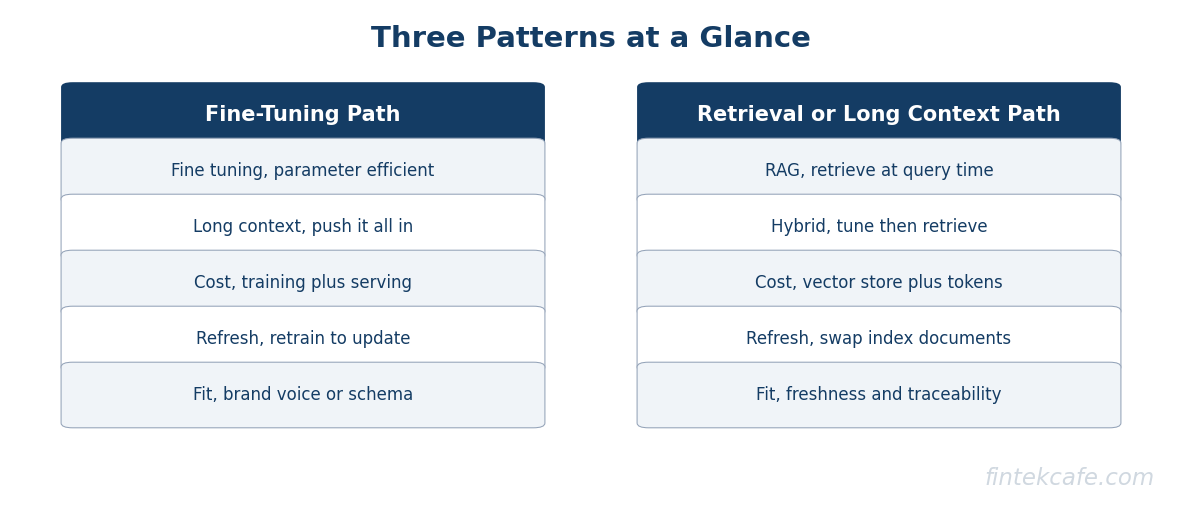
What Each Pattern Actually Is
Fine-Tuning (Parameter-Efficient Variants)
Modern fine-tuning rarely means retraining the full model. The dominant patterns are LoRA (Low-Rank Adaptation) and QLoRA (Quantized LoRA), which freeze the base model weights and train a small set of low-rank adapter matrices on top. The adapter is a few hundred megabytes against a base model of hundreds of gigabytes. Training runs hours on a single GPU rather than weeks on a cluster.
The output is a fine-tuned model that produces text in the style, format, and domain of the training data. The model has not memorized facts the way a database stores them. It has absorbed patterns. Ask a fine-tuned model a question about a policy not in the training set and it will guess plausibly, which is often the failure mode that matters.
Fine-tuning wins when the customization is about how the model communicates rather than what it knows. Format compliance (every response must be valid JSON, every response must end with a citation block, every response must follow a regulatory disclosure template) is the canonical fit.
Retrieval-Augmented Generation
RAG keeps the model frozen and stores the knowledge in a separate database. At query time the system retrieves the relevant passages and inserts them into the prompt. The model reads the retrieved context and generates an answer grounded in it.
The pattern is the workhorse of enterprise AI in 2026 because it solves the freshness problem (update the database, the model sees the new content immediately) and the governance problem (the database is queryable, versioned, and access-scoped) in a way the other two patterns cannot match. The detailed mechanics of retrieval, embeddings, and the six-layer reference architecture are the foundation. The choice of vector database is downstream of that.
RAG wins when the knowledge base is large, changes frequently, or carries access controls that must be enforced at the chunk level.
Long-Context
Frontier models now ship with context windows of one million tokens or more. A million tokens is roughly the size of a 2,000-page book. The pattern is to skip the customization entirely, paste the relevant documents (or all the documents) into the prompt with every query, and let the model find the answer.
The pitch is operational simplicity. No training, no retrieval pipeline, no vector store. The reality is that token bills scale linearly with context size and per-query latency scales worse than linearly with how much the model has to reason over. A one-million-token prompt costs roughly a thousand times more than a one-thousand-token prompt and runs an order of magnitude slower.
Long-context wins for small corpora that fit comfortably below 100,000 tokens, for one-shot tasks where the per-query cost is acceptable, and for workloads where the simplicity of having no pipeline outweighs the per-query bill.
The Real Cost Curves
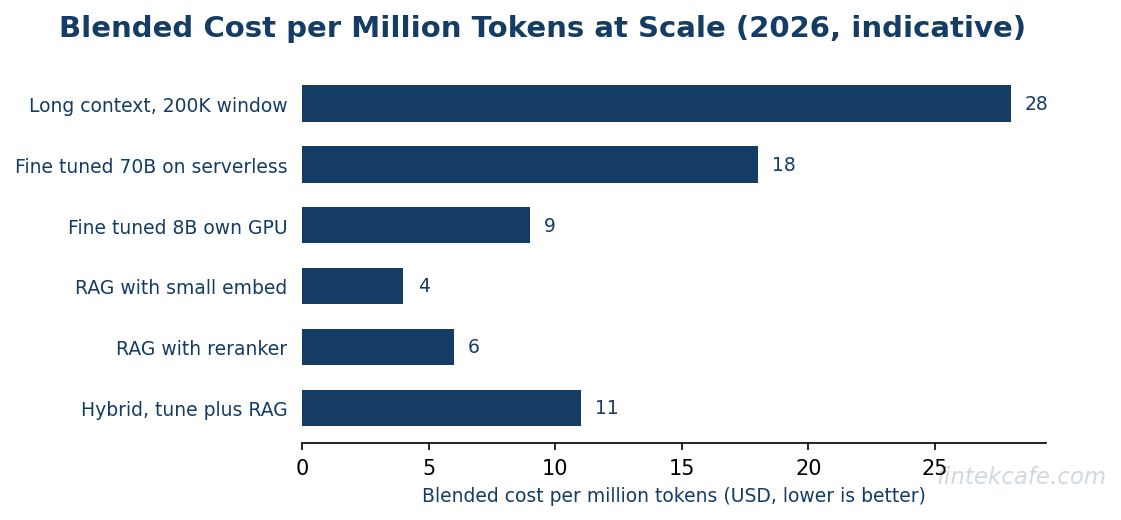
The cost comparison is where the vendor pitches fall apart. Each pattern has a different cost shape, and the shapes intersect at different traffic volumes.
| Pattern | Setup cost | Per-query cost | Cost driver |
|---|---|---|---|
| Fine-tuning (LoRA) | Moderate (training run + eval harness) | Low (inference on a small model) | Training data quality, eval cycle |
| RAG | Moderate (chunking, embedding, vector store) | Moderate (retrieval + LLM tokens) | Corpus size, query volume |
| Long-context | Near-zero | High (token bill scales linearly with prompt size) | Per-query prompt size |
| Hybrid | High (combined setup) | Variable | Configuration choices |
The intersection point matters. For workloads under a few thousand queries per day, long-context can be cheaper than RAG because the setup cost amortization for RAG dominates the per-query savings. For workloads above tens of thousands of queries per day, RAG wins by a wide margin and long-context becomes unaffordable. Fine-tuning sits below both at very high query volumes because the per-query cost is the lowest, but only if the underlying knowledge does not change.
The pattern that surprises finance teams during the second quarter after launch is long-context. A pilot that ran 500 queries per day on a one-million-token prompt looked manageable. The same pattern at 50,000 queries per day produces a token bill that exceeds the salary of the team that built it. The broader cost shape of AI infrastructure and the cloud economics specific to AI workloads are the right framing for the underlying math.
Latency, Refresh, and Governance
Cost is one of four axes. The other three are where most teams discover the pattern they chose does not fit the workload.
Latency Profile
Fine-tuned models are the fastest at inference because no retrieval step runs and the model is often smaller than the frontier API alternative. RAG adds retrieval latency (embedding the query, querying the vector store, reranking) which is usually 100 to 400 milliseconds. Long-context adds context-processing latency that scales with how much sits in the prompt. A one-million-token prompt can take five to fifteen seconds to first token.
For interactive chat workloads where users tolerate two seconds, all three patterns can work. For real-time scoring (fraud, trade surveillance, customer-facing voice) where the budget is sub-200 milliseconds, only fine-tuned models meet the bar, and even then only with careful inference optimization.
Refresh Cadence
How fast does the model need to reflect new knowledge? Fine-tuning is the slowest because every refresh triggers a retraining run, an evaluation cycle, and a deployment. Weekly refresh is achievable; daily refresh is operationally heavy. RAG is the fastest because adding a document to the corpus makes it queryable within minutes. Long-context is intermediate because the documents pasted into the prompt can be updated immediately, but the team has to decide what to paste.
A customer-support agent for a product whose pricing changes weekly should not be a pure fine-tuned model. A legal-research assistant operating against a frozen case-law corpus may not need RAG at all.
Governance and Audit
This is where regulated industries do most of their thinking. Fine-tuned models bury knowledge inside opaque weights. The model knows things, but a compliance team cannot point to where it learned them, cannot revoke a piece of knowledge cleanly, and cannot audit what was used to answer a particular query. RAG stores knowledge in a database. The corpus is versioned, the retrieval is logged, and every generated answer can be traced back to the chunks that produced it. Long-context shows the knowledge in the prompt but produces no persistent record beyond what the inference logs capture.
Regulated industries (banking, healthcare, defense) default to RAG for the audit story alone. Fine-tuning is layered on top for tone and format, never as the sole carrier of regulated knowledge.
Failure Modes
Each pattern hides a specific failure mode that the vendor pitch never mentions.
Fine-tuning fails silently when the production query distribution drifts from the training distribution. The model continues to generate confident answers that are subtly wrong. Detection requires a held-out evaluation set refreshed continuously, which most teams do not maintain.
RAG fails when retrieval recall collapses on long-tail queries. The model generates from its prior knowledge over an empty or wrong context. The user has no way to tell.
Long-context fails when the model loses information in the middle of a very long prompt. The "lost in the middle" effect is well documented. Information at the start and end of a long prompt is recalled reliably; information in the middle is often missed.
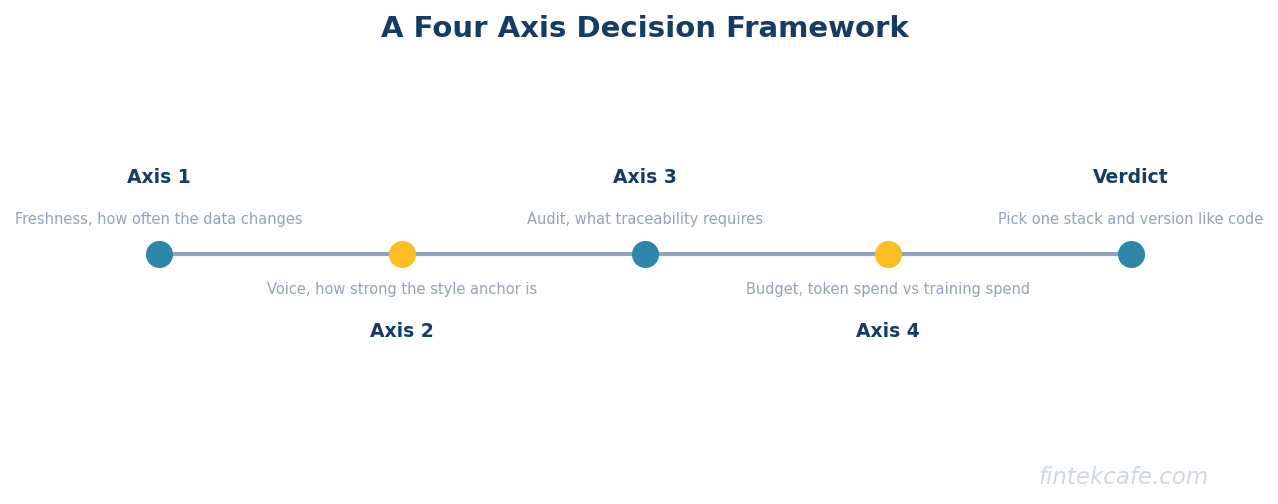
A Decision Framework: Four Axes
The choice between the three patterns reduces to four questions answered in order.
Axis one: How often does the knowledge change? If the answer is "rarely" (stable case law, frozen product catalog, regulatory disclosures that update annually), fine-tuning is in scope. If the answer is "weekly or faster" (pricing, inventory, customer records, support tickets), fine-tuning is out and the choice is between RAG and long-context.
Axis two: How large is the relevant knowledge base? Below roughly 100,000 tokens of always-relevant content, long-context can work. Above that, retrieval becomes mandatory and the choice is RAG. The 100,000-token threshold is not a hard line; it shifts with per-query budget and latency tolerance.
Axis three: What is the query volume? Below a few thousand queries per day, long-context is operationally simpler and not yet ruinous on cost. Above tens of thousands of queries per day, RAG wins decisively. Fine-tuning becomes attractive only at very high query volumes where the per-query inference cost matters more than the training amortization.
Axis four: What does the audit story need to look like? If a compliance team needs to trace every answer back to the source documents, RAG is the only pattern that produces that trace cleanly. If the audit requirement is light, the other patterns are in scope.
The framework rarely produces a single answer. It produces a primary pattern with a secondary pattern layered on top.
A Worked Example: Customer Support for a Regulated Insurer
Consider a customer-support agent for a regulated insurer. The agent must answer questions about policy terms (stable, hundreds of policies, regulated disclosures), claim status (changes hourly, per-customer access), and product offerings (changes weekly).
A pure fine-tuned model fails because the claim status changes too fast and the per-customer scoping cannot be enforced in model weights. A pure long-context approach fails because the cumulative corpus (policy terms plus product catalog plus the relevant subset of customer data) exceeds the budget at scale. A pure RAG approach handles all three knowledge sources well but produces answers in a voice that may not match the brand and a format that may not comply with regulatory disclosure templates.
The right architecture is hybrid. RAG handles retrieval across policy terms, product catalog, and claim status, with access scoping on the claim-status retriever. A light LoRA fine-tune on the base model handles tone, format, and required disclosure templates. A small set of always-relevant policy documents (the regulatory disclosure language, the brand voice guide) sits as fixed long-context in every prompt.
Each layer does one thing. The cost is moderate because the LLM bill stays bounded. The latency is acceptable because the retrieval is small and the fine-tune produces short structured responses. The audit story is clean because every retrieved chunk is logged. This is the shape that mature enterprise programs converge on, regardless of which pattern they started with.
When to Run a Hybrid Architecture
The hybrid pattern is underestimated for one reason: vendors do not sell it. Each vendor sells the one piece they own. Building a hybrid requires the buyer to assemble the architecture deliberately and own the integration.
Hybrid wins in three configurations.
RAG plus fine-tune for tone and format. The most common production shape. RAG carries the knowledge, fine-tuning carries the voice. The fine-tune is small and cheap because it only has to teach format compliance, not domain knowledge.
RAG plus long-context for always-relevant documents. A small set of documents (security policy, brand voice, regulatory disclosure language) sits in every prompt. The rest of the knowledge base is retrieved. The long-context layer pays for itself by guaranteeing certain content is always available.
Fine-tune plus long-context for one-shot tasks. A specialized fine-tune handles the format. A small long-context window carries the per-request document. No retrieval pipeline. This shape fits document-processing workflows (contract review, policy comparison) where each request has a defined input.
The principle is that the three patterns are not competing products. They are three primitives that compose. The teams that internalize this build cheaper, faster, and more auditable systems than the teams that pick one and defend it. The underlying build versus buy decisions in AI infrastructure frame the same question at the platform level.
What This Means for AI Programs in 2026
For an executive sponsor of an AI program, the right question to ask the team is not which pattern they chose. It is whether they considered all three and articulated why the chosen architecture wins on cost, latency, refresh, and governance for the actual workload. A team that defaults to RAG because it is familiar, or to long-context because the vendor pitch is loud, or to fine-tuning because the head of AI used to publish papers on it, has not done the analysis.
The cost gap between a thoughtful architecture and a defaulted architecture compounds. A program that picks the right pattern for the workload stays within budget through scale. A program that picks the wrong pattern discovers in the second quarter that the unit economics never worked.
FAQ
Is fine-tuning still relevant in 2026?
Yes, but the role has narrowed. Fine-tuning is the right tool for tone, format, and stable narrow-domain reasoning. It is the wrong tool for fresh knowledge, large changing corpora, or workloads with strong audit requirements. The dominant fine-tuning pattern is now LoRA or QLoRA layered on a frontier base model, not full-parameter retraining.
Does long-context make RAG obsolete?
No. Long-context reduces the cases where RAG is the only option, not the cases where RAG is the right option. RAG remains the right pattern for large corpora, changing knowledge, fine-grained access control, and audit-heavy workloads. Long-context is a useful tool for small corpora and one-shot tasks.
How much does each pattern cost to run at scale?
The cost shape is different for each. Fine-tuning has a high setup cost (training run plus evaluation harness) amortized over many queries with low per-query inference cost. RAG has a moderate setup cost and a moderate per-query cost driven by retrieval and LLM tokens. Long-context has near-zero setup and a high per-query cost that scales linearly with prompt size. At very high query volumes fine-tuning is cheapest, at moderate volumes RAG wins, at low volumes long-context can be competitive.
Which pattern is best for regulated industries?
RAG, almost always, with fine-tuning layered on for tone and format. The reason is audit: RAG stores knowledge in a versioned database, retrieval is logged, and generated answers can be traced back to the source chunks. Fine-tuned models bury knowledge in opaque weights, which makes the compliance story much harder.
When should we use a hybrid architecture?
Most production deployments past pilot stage end up hybrid. The most common shape is RAG for knowledge plus a small LoRA fine-tune for tone and format. A small long-context layer for always-relevant documents (security policy, brand voice, regulatory disclosure) often joins. Treating the patterns as exclusive is the framing mistake that drives most of the cost overruns.
Related reading on FinTekCafe
- What Is Retrieval-Augmented Generation (RAG)? Architecture, Costs, and Where It Breaks
- What Is Vector Search? Embeddings, ANN, and Why Search Got Smart
- Vector Databases: When You Actually Need One
- How Large Language Models Actually Work, No Code Required
- Build vs Buy in AI Infrastructure: A Decision Framework
- Cloud Economics for AI Workloads: What Executives Get Wrong
Related Articles

The AI Headcount Illusion: What Agents Actually Do to the Org Chart
Agents rarely shrink payrolls. They convert doing-work into checking-work, and winning org charts are redesigned around that conversion, not headcount.
The Total Cost of AI: A Framework for Pricing an AI Initiative End to End
An eight-line total cost of ownership framework for enterprise AI, with a worked example, realistic cost shares, and a build-buy-wait decision table.

AI Governance: How to Build an AI Policy That Actually Gets Followed
Why AI policies fail as documents and work as controls: a three-tier governance model, ownership patterns, EU AI Act duties, and metrics that matter.