What Is Retrieval-Augmented Generation (RAG)? Architecture, Costs, and Where It Breaks

Key Takeaways
- Retrieval-augmented generation is three distinct stages bolted together: retrieval, augmentation, and generation. Treating RAG as one component is the first mistake. Each stage has its own failure surface, its own cost curve, and its own owner.
- The reference architecture (chunking, embedding, vector store, retriever, reranker, LLM) is six tunable layers. Vendors sell the pipeline as a product. The reality is that every layer adds latency, hides a bias, and gives the system a new way to be wrong.
- The headline production failure is rarely hallucination. It is retrieval recall collapse on long-tail or rare queries that the embedding model never saw cleanly. The model then generates a confident answer over an empty or wrong context, and the user has no way to tell.
- The cost shape is bimodal. Embedding compute and vector storage scale with corpus size and refresh rate. Per-query retrieval and per-query LLM tokens scale with traffic. Underestimate either curve and the bill compounds in a quarter.
- RAG is not always the right pattern. Fine-tuning wins for stable narrow domains, long-context wins for small static corpora and one-shot tasks, and hybrid wins for most of the interesting middle. The interesting executive question is the choice, not the configuration.
Why RAG Won, and What That Means
Every enterprise AI deployment now includes the letters RAG somewhere in the architecture diagram. The pattern won because the two alternatives lost in specific ways. Fine-tuning a base model on internal data is technically possible but operationally brutal: every content update triggers a retraining run, every retraining run requires evaluation, and the legal team asks new questions about training data lineage every time. Long-context prompting, where the entire corpus is stuffed into the model context window each request, works for tiny corpora but fails the moment the document set grows past a few hundred pages because per-query cost and latency both explode.
Retrieval-augmented generation split the problem differently. Keep the model frozen. Keep the corpus separate. At query time, retrieve the small subset of corpus content relevant to the question, paste it into the prompt as context, and let the model generate from there. The model gets fresh knowledge without retraining. The corpus can be updated continuously. The lawyer is happier because the training set never changes.
The catch is that the pattern is now so familiar that vendors compress all six layers into a single bullet on a slide. That compression is where executive surprises come from. The question worth asking before a RAG program scales is not "are we using RAG." The question is "which of the six layers does our team own, which does the vendor own, and where does the failure mode live."

What RAG Actually Is: The Three Stages
The acronym is its own teaching device. Three letters, three stages, three failure surfaces.
Retrieval. Given a user query, return a ranked set of corpus passages most likely to contain the answer. This stage is dominated by vector search and embeddings, which translate text into numerical representations that capture semantic similarity. The retrieval stage owns recall (did we surface the right passages) and precision (are the surfaced passages actually relevant).
Augmentation. Take the retrieved passages and assemble them into a prompt that the LLM can reason over. This stage looks trivial. It is not. Augmentation owns the decisions about how many passages to include, how to format them, how to handle conflicting sources, what to do when retrieval returns nothing useful, and how to leave room for the user query, system instructions, and the model response.
Generation. The LLM produces an answer conditioned on the augmented prompt. Generation owns hallucination risk, citation behavior, refusal behavior, and tone. It also owns the per-query token bill, which is usually the biggest line item in a mature RAG system.
The temptation is to treat these stages as one box and tune the LLM. The leverage is the other way around. The cheapest improvements come from retrieval and augmentation. The model is rarely the bottleneck once a recent frontier model is in place.
The Reference Architecture
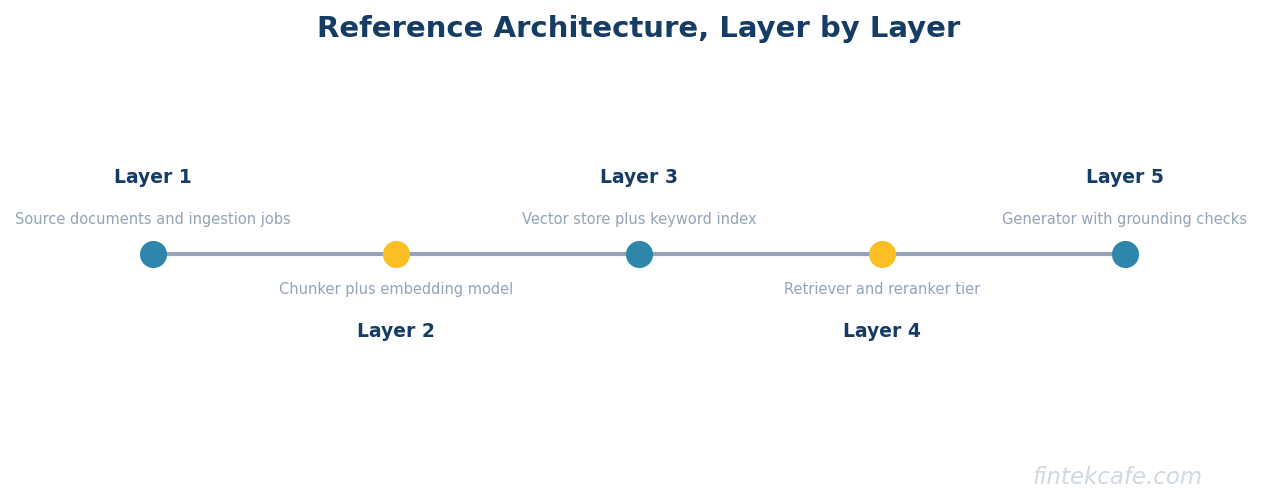
A production RAG system has six layers. Each can be swapped, but the layer above and below have to agree on the interface.
Chunking. Source documents are split into passages of roughly 200 to 1,000 tokens. The chunking strategy matters more than the team usually expects. Splitting on fixed token counts cuts sentences in half. Splitting on paragraphs handles prose well but breaks tables. Splitting semantically (by topic or heading) handles long documents better but requires its own preprocessing step.
Embedding. Each chunk is passed through an embedding model, which turns it into a vector of typically 768 to 3,072 dimensions. The embedding model is the silent foundation of the whole system. A weak embedding model permanently caps retrieval quality. A strong embedding model does not save a bad chunking strategy.
Vector store. The chunk and its vector are persisted into a vector database that supports approximate nearest neighbor search. The vector store owns refresh latency (how long after a document changes does the new version become searchable), scale (millions or billions of chunks), and filtering (can the search be restricted to a tenant, a date range, an access level).
Retriever. At query time, the user query is embedded by the same embedding model. The vector store returns the top K nearest chunks by vector similarity. Most teams set K between 10 and 50 here. The retriever owns query rewriting, query expansion, hybrid retrieval (vector plus keyword), and metadata filters.
Reranker. A second model, usually a cross-encoder, scores each retrieved chunk against the original query and reorders the top K. The reranker is the highest-return optimization in most RAG systems and the most commonly skipped one. Skipping it caps system quality earlier than teams realize.
LLM. The final stage takes the top N reranked chunks (typically 3 to 8), formats them into a prompt, and generates the answer. The LLM owns the final answer quality, latency, and per-query cost.
Every layer has a configuration knob. Every knob interacts with every other knob. A system that performs well in a notebook with a curated test set is not the same system that runs in production against the real query distribution. The gap between the two is where most RAG programs lose six months.
Where Retrieval Quietly Fails
The most overlooked failure mode is not the one vendors warn about. Vendors warn about hallucination, because hallucination is visible. The user reads an answer that contains a fabricated fact, and the failure shows up in a support ticket.
The quiet failure is retrieval recall collapse. The user asks a question. The vector search returns nothing relevant, because the embedding model was never trained on the specific terminology the question uses, or the right passage was chunked in a way that severed the key sentence, or the metadata filter scoped the search too narrowly. The LLM, given context that does not contain the answer, generates a plausible answer from its general training. The user has no way to tell whether the answer came from the corpus or from the model's prior. The answer is sometimes right, sometimes wrong, always confident.
A second failure mode is chunk-boundary truncation. The answer to the question lives across the boundary of two chunks. Each chunk individually looks irrelevant. Neither is retrieved. The system fails in a way that no single document inspection catches.
A third failure mode is context-window bloat. The team, anxious about recall, increases K from 10 to 50. The augmented prompt now runs to tens of thousands of tokens. Per-query cost triples. Latency doubles. Answer quality often gets worse, because the model has to find the needle in a larger haystack.
A fourth failure mode is hallucination from low-confidence retrieval. The reranker scores the top chunk at 0.12 on a scale of 0 to 1. A well-engineered system would refuse to answer, or warn the user that confidence is low. Most production systems do not check the reranker score and answer anyway.
A clean-eyed read of the RAG systems already lying to enterprise users finds all four failure modes in the wild, often in systems that passed acceptance testing.
The Cost Shape
RAG economics are bimodal in a way that surprises finance teams during the second quarter after launch.
Corpus-side costs scale with content. Embedding compute is one-time per chunk, but document refresh, schema migration, or a switch to a better embedding model means re-embedding the corpus. For a corpus of 10 million chunks, a re-embed against a modern embedding model takes hours of GPU time and meaningful spend. Vector storage scales linearly with chunk count and dimension. A corpus of 100 million chunks at 1,536 dimensions occupies hundreds of gigabytes in the vector store, with its own indexing memory overhead on top.
Query-side costs scale with traffic. Each query triggers one embedding call (cheap), one vector search (cheap), one reranker call (moderate), and one LLM call (expensive). A frontier model at typical context lengths can cost a few cents per query. At a million queries per day, the LLM bill alone can run into seven figures per month before the system is mature. Reranker cost is often forgotten in early estimates because the team prototyped without it.
A common pricing trap is the assumption that retrieval is free. It is not. Vector store providers charge for storage, indexing memory, and query volume. Self-hosting moves the cost from a SaaS line item to a Kubernetes line item, not to zero.
The cost picture connects directly to cloud economics for AI workloads and to broader build versus buy decisions in AI infrastructure. Underestimating either curve produces the same outcome: a successful pilot whose unit economics fail at scale.
RAG vs Fine-Tuning vs Long-Context vs Hybrid
The decision tree for which pattern fits a given use case has four branches. The choice is rarely binary.
| Pattern | Best fit | Worst fit |
|---|---|---|
| Fine-tuning | Stable, narrow domain. Specialized terminology or format the base model handles poorly. Latency-sensitive. | Frequently updated corpus. Cross-domain queries. Regulated data lineage. |
| Long-context only | Small static corpus that fits in the context window. One-shot tasks. High-stakes answers where the entire reasoning chain must be in the prompt. | Large corpora. High query volume. Cost sensitivity. |
| RAG | Large or frequently changing corpus. Cross-domain queries. Need to cite sources. | Highly numeric reasoning. Tasks where the answer requires synthesis across thousands of documents. |
| Hybrid (RAG + fine-tune, RAG + long-context) | Most production systems past pilot stage. Mature programs almost always end up here. | Pure research prototypes where simplicity is the priority. |
The pattern most underestimated in 2026 is hybrid. A common configuration uses RAG for retrieval against the corpus, fine-tuning for tone and format, and long-context for a small set of always-relevant policy documents. Each layer does one thing. The system as a whole is harder to reason about, but each component is replaceable.
The fastest way to make the wrong pattern choice is to start with "we are doing RAG" before understanding which problem it solves. The team builds the pipeline, discovers that fine-tuning would have been simpler, then has to defend the existing investment. A useful baseline read is how large language models actually work, because the pattern choice flows from how the underlying model treats context.
Governance: Treating Retrieval as a System of Record
The architectural insight worth internalizing is that the corpus inside a RAG system is now a system of record. It is queried thousands of times a day. Its content shapes decisions. Its access controls leak into model outputs. Every governance question that applies to a database applies to it.
Three governance lines tend to be drawn too late.
Access scoping. The retrieved chunks must respect user permissions. A naive RAG implementation indexes everything and trusts the LLM to filter. The LLM will not filter reliably. Filtering belongs in the retriever, with metadata fields that mirror the source-system permissions.
Lineage and citation. Every generated answer should be traceable to the chunks that produced it. Without citation, the system cannot be audited, the user cannot verify, and the support team cannot diagnose a wrong answer.
Freshness contracts. Each corpus source needs a defined refresh frequency and a defined acceptable staleness window. A pricing document that updates daily but refreshes weekly in the vector store will produce wrong answers in a predictable pattern.
These governance lines are organizational, not technical. The platform team owns the pipeline. The business owner of each source system owns the freshness, the access model, and the canonical answers. RAG without these owners assigned is a successful demo with a slow-motion incident attached.
What This Means for the Next Twelve Months
The pattern has settled. The interesting work has moved up the stack. The teams that will compound through 2026 and into 2027 are the ones treating retrieval as a discipline rather than a feature, building internal evaluation harnesses tuned to their own query distribution, and resisting the temptation to add a seventh layer because a vendor has a new product. The teams that will stall are the ones running the pipeline once, calling it a platform, and waiting for the failure modes to surface in customer-facing systems.
For executives, the right question to ask the AI team is not whether RAG is in the architecture. It is whether the team can name the chunking strategy, the embedding model, the reranker, the access-scoping mechanism, and the per-query cost. If those answers do not come quickly, the system has been operationalized in name only.
FAQ
Is RAG the same as a vector database?
No. A vector database is one component of a RAG system. The vector database stores embeddings and supports nearest-neighbor search. RAG also includes the chunking pipeline that produces the embeddings, the retriever logic that queries them, an optional reranker, and the LLM that generates the final answer. Most teams that say "we are doing RAG" really mean "we have stood up a vector database." The two are not the same project.
How is RAG different from fine-tuning?
Fine-tuning bakes knowledge into the model weights by continuing training on domain-specific data. RAG keeps the model frozen and injects knowledge at query time by retrieving relevant passages. Fine-tuning is faster at inference and better for stable narrow domains. RAG is more flexible for changing corpora and easier to govern, because the knowledge source is a database rather than a model checkpoint.
Do long-context models make RAG obsolete?
Long-context models reduce the cases where RAG is the only option, not the cases where RAG is the right option. Stuffing a million tokens of corpus into every query is technically feasible with modern context windows but produces high latency, high per-query cost, and degraded reasoning. RAG remains the right pattern when the corpus is large, changing, or shared across many queries.
What is the most common reason RAG systems fail in production?
Retrieval recall collapse on long-tail queries. The vector search returns nothing useful, the LLM answers from its prior knowledge anyway, and the user has no way to tell. Systems that monitor reranker confidence scores and refuse to answer below a threshold catch this. Most systems do not monitor confidence and answer anyway.
How much does a production RAG system cost to run?
The cost is bimodal. Corpus-side cost (embedding compute and vector storage) scales with corpus size and refresh frequency, typically a few thousand to a few hundred thousand dollars per year for mid-size corpora. Query-side cost (LLM tokens and reranker calls) scales with traffic and typically runs from a fraction of a cent to a few cents per query. At enterprise traffic levels, the query-side bill dominates, and the LLM is the largest single line item.
Related reading on FinTekCafe
- What Is Vector Search? Embeddings, ANN, and Why Search Got Smart
- Vector Databases: When You Actually Need One
- Your RAG System Is Lying to You (Pro)
- How Large Language Models Actually Work, No Code Required
- Cloud Economics for AI Workloads: What Executives Get Wrong
- Build vs Buy in AI Infrastructure: A Decision Framework
Related Articles

The AI Headcount Illusion: What Agents Actually Do to the Org Chart
Agents rarely shrink payrolls. They convert doing-work into checking-work, and winning org charts are redesigned around that conversion, not headcount.
The Total Cost of AI: A Framework for Pricing an AI Initiative End to End
An eight-line total cost of ownership framework for enterprise AI, with a worked example, realistic cost shares, and a build-buy-wait decision table.

AI Governance: How to Build an AI Policy That Actually Gets Followed
Why AI policies fail as documents and work as controls: a three-tier governance model, ownership patterns, EU AI Act duties, and metrics that matter.