ai
The Total Cost of AI: A Framework for Pricing an AI Initiative End to End
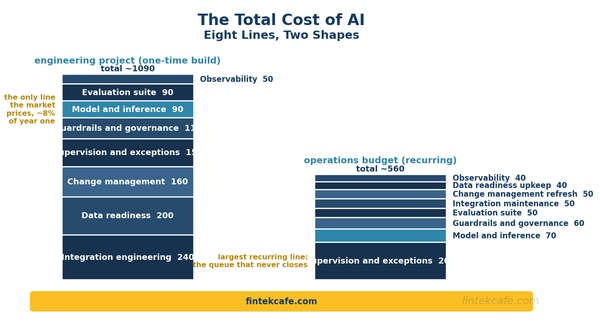
An eight-line total cost of ownership framework for enterprise AI, with a worked example, realistic cost shares, and a build-buy-wait decision table.
An eight-line total cost of ownership framework for enterprise AI, with a worked example, realistic cost shares, and a build-buy-wait decision table.
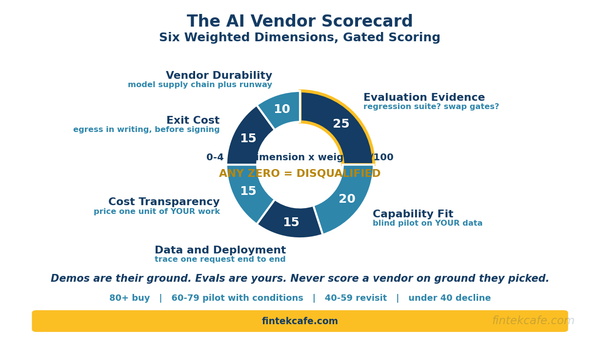
A six-dimension scoring framework for evaluating AI vendors, with weights, pass/fail gate questions, and a matrix a buyer can apply in a live meeting.

A five-level maturity model for enterprise AI agent readiness, with deterministic entry gates and a self-assessment matrix executives can score in minutes.

Most teams ship LLM features with no real evals, then find failures in production. A practical framework for an evaluation harness that scales.

Frontier models do not win every task. A 2026 framework for when small and mid-sized models beat them on cost, latency, privacy, and accuracy.

Most enterprise AI agents stall in pilot. A framework for the narrow, tool-constrained, well-evaluated patterns that ship, and the demoware that does not.

Why most enterprise knowledge graph projects stall at six months: schema, ingestion, and consumer mismatch. The pattern top AI teams actually follow.
Deep analysis across the systems, strategies, and economics that shape modern technology.
Premium Members Get: Exclusive deep-dive research · Architecture playbooks · Executive briefings · Full archive access