AI Agents in the Enterprise: What Actually Works in 2026 (and What Is Still Demoware)

Key Takeaways
- A thin slice of enterprise agent deployments are quietly delivering value, and almost all of them share the same shape: narrow task scope, constrained tool and permission access, a real evaluation harness, and a low cost of failure. The open-ended autonomous agent that "does the job" is still demoware in 2026.
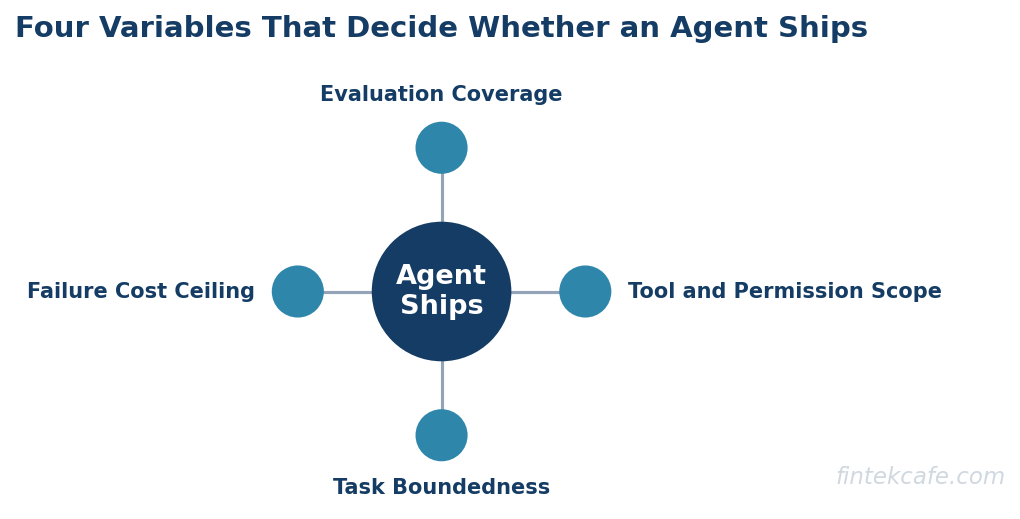
- The four variables that decide whether an agent ships are task boundedness, tool and permission scope, evaluation coverage, and the failure-cost ceiling. An agent that scores well on all four is a product. An agent that scores poorly on any one of them is a demo.
- The working patterns are unglamorous: ticket triage and routing, code review assistance, structured data extraction, and first-draft generation with a human approver. They win because the task has a checkable answer and a human stays in the loop.
- The failing patterns are the ones in the keynote: the autonomous research agent, the self-directed operations agent, the multi-agent "swarm" that plans its own work. They fail on reliability, cost, and auditability, not on intelligence.
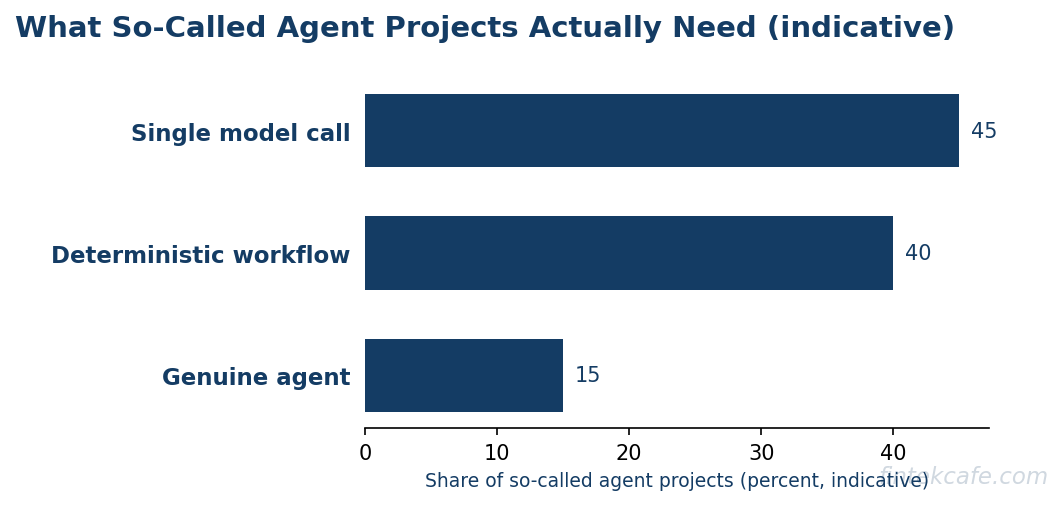
- The first architectural decision is not which agent framework to use. It is whether the task needs an agent at all. A large share of so-called agent projects are better served by a deterministic workflow or a single well-prompted model call, and choosing the heavier pattern is the most common and most expensive mistake.

Agentic AI Is the Most Over-Marketed Phrase of the Year
"Agentic AI" is the phrase that ate the 2026 enterprise software pitch deck. Every vendor has an agent. Every platform is now "agent-native." Every analyst deck forecasts a workforce of digital coworkers. And yet, when organizations look at what is actually running in production and generating measurable value, the picture is far narrower than the marketing implies.
The honest summary is this. A small fraction of agent deployments are working and paying for themselves. A much larger fraction are stuck in pilot, generating impressive demos and inconclusive return on investment. And a meaningful fraction have been quietly cancelled after the pilot revealed that the agent was unreliable, expensive, or impossible to audit when something went wrong.
The gap between the working slice and the stalled majority is not about model quality. The frontier models in 2026 are extraordinary. The gap is about engineering discipline and task selection. The teams that ship agents treat the agent as a constrained system component with a defined job, not as an autonomous intelligence that will figure things out. The teams that stall treat the agent as the latter and then spend six months discovering why that does not survive contact with production.
This article separates the two. It defines what an enterprise AI agent actually is, lays out the four variables that decide whether one ships, walks through the patterns that work and the patterns that are still demoware, and gives a readiness checklist and a decision tree for the question that comes before everything else: should this even be an agent?
What an Enterprise AI Agent Actually Is
An AI agent is a system that uses a language model to decide which actions to take, executes those actions through tools, observes the results, and loops until a goal is met or a stopping condition is hit. The defining feature is the loop. A single model call takes input and returns output. An agent takes input, decides on an action, calls a tool, reads the result, and decides again. That loop is what makes agents powerful and what makes them dangerous.
The three building blocks are the model (the reasoning engine that decides), the tools (the functions the agent can call, from a database query to an email send), and the orchestration layer (the loop that wires decision to action to observation). Vendors sell elaborate versions of all three. The reality is that the orchestration is usually a few hundred lines of control flow, the tools are the part that matters, and the model is a commodity you rent.
The crucial distinction for executives is between an agent and the two simpler patterns it is often confused with. A single LLM call classifies an email or drafts a summary in one shot, with no loop and no tools. A deterministic workflow runs a fixed sequence of steps, some of which may call a model, but the sequence is fixed by the engineer, not chosen by the model at runtime. An agent is only necessary when the path through the task genuinely cannot be predetermined, because the right next step depends on results the system has not seen yet.
That distinction is the whole game. Most tasks that get pitched as agent problems are actually workflow problems wearing an agent costume. Recognizing the difference is the single highest-leverage skill in this space, and it is covered in the decision tree later in this article. For the foundational mechanics of how the underlying models reason and where retrieval fits, the companion explainer on retrieval-augmented generation and how it actually works is the right starting point, because retrieval is the tool most production agents lean on hardest.
The Four Variables That Decide Whether an Agent Ships
After stripping away the framework debates, the question of whether an agent will survive production comes down to four variables. An agent that scores well on all four is shippable. An agent that scores poorly on any single one is a demo, no matter how good the other three look.
Task Boundedness
A bounded task has a clear definition of done and a checkable answer. "Extract the invoice number, date, and total from this document" is bounded. "Manage our vendor relationships" is not. The more bounded the task, the more reliably an agent performs, because the agent has fewer ways to wander off and the output has a verifiable shape.
Boundedness is not about difficulty. A hard but bounded task (parse a messy contract into structured fields) is far more shippable than an easy but unbounded one (keep our knowledge base tidy). The unbounded task has no stopping condition, no clear success metric, and infinite surface area for the agent to do something unexpected.
Tool and Permission Scope
Every tool an agent can call is a capability and a liability. An agent with read-only access to a ticketing system can do limited damage. An agent with write access to production databases, the ability to send external email, and authority to issue refunds is a security and operational risk that grows with every additional permission.
The working pattern is least privilege applied ruthlessly. Give the agent the smallest set of tools that lets it complete the bounded task, scope each tool to read-only where possible, and put a human approval step in front of any action that is hard to reverse. The failing pattern is the broad-access agent justified by flexibility, which is exactly the access profile that turns a model error into an incident.
Evaluation Coverage
You cannot ship what you cannot measure. An evaluation harness is the set of test cases, scoring functions, and regression checks that tell you whether the agent is getting better or worse as you change prompts, models, and tools. Without it, every change is a guess and every deployment is a leap of faith.
The teams that ship build the eval harness before they build the agent. They collect real examples, define what a correct output looks like, and score every version against that set. The teams that stall skip this because the demo looked good, and then discover in production that "looked good on five examples" and "works on the long tail of real inputs" are entirely different claims. The discipline here mirrors the broader practice of AI evaluations as an executive concern, which is the difference between a measurable system and a hopeful one.
Failure-Cost Ceiling
What is the worst thing that happens when the agent is wrong, and how often will it be wrong? An agent that drafts a reply for a human to approve has a low failure-cost ceiling, because the human catches the error. An agent that autonomously sends that reply to a customer, or executes a trade, or modifies a production record, has a high ceiling, because the error reaches the world before anyone sees it.
The decisive move is to design the failure cost down, not to chase the error rate to zero. No model is perfectly reliable. The agents that ship are the ones where being wrong is cheap and recoverable, which usually means a human approves consequential actions and the agent operates inside a sandbox for everything else.
The Patterns That Actually Work
The working deployments in 2026 are not the ones in the keynotes. They are narrow, constrained, and boring, and that is exactly why they ship.
Ticket triage and routing. An agent reads an incoming support ticket, classifies it, enriches it with relevant context from a knowledge base, and routes it to the right queue or drafts a suggested response for an agent to approve. The task is bounded, the tools are read-mostly, the eval set is the historical ticket archive, and the failure cost is low because a human handles the final response. Organizations report meaningful reductions in time-to-resolution from this pattern without the reliability problems of full automation.
Code review assistance. An agent reviews a pull request, flags likely bugs, checks against style and security rules, and posts comments for the human reviewer to accept or dismiss. The agent never merges anything. It augments the reviewer rather than replacing them. The output is checkable (the human sees every comment), the failure cost is low (a bad suggestion is ignored), and the value is real (reviewers catch more, faster).
Structured data extraction. An agent pulls structured fields from unstructured documents, invoices, contracts, forms, and resumes, into a typed schema, with confidence scores and a human review queue for low-confidence cases. This is arguably the highest-return agent pattern in the enterprise right now precisely because the task is so bounded and the output so checkable.
First-draft generation with a human approver. An agent produces a first draft of a report, a summary, a response, or a configuration, and a human edits and approves before it goes anywhere. The agent compresses the time from blank page to good-enough draft. The human owns correctness. This pattern shows up across legal, finance, marketing, and operations, and it works for the same reason as the others: bounded task, low failure cost, human in the loop.
The common thread is unmistakable. Narrow scope, constrained tools, real evaluation, and a human who owns the consequential decision. None of these agents "do the job." They do a well-defined slice of the job and hand the rest to a person.
The Patterns That Are Still Demoware
The agents that demo brilliantly and fail in production share an opposite profile.
The autonomous research agent. Give it a question, and it browses, reads, synthesizes, and returns a report with no human in the loop. The demo is mesmerizing. In production it hallucinates sources, follows tangents, runs up large token bills on dead ends, and produces output that no one can fully trust because no one can fully audit the path it took. The task is unbounded, the eval coverage is thin, and the failure cost (a confident but wrong report informing a real decision) is high.
The self-directed operations agent. It monitors systems, decides what needs doing, and takes action across production infrastructure. This is the agent that violates every one of the four variables at once: unbounded task, broad write permissions, near-impossible to evaluate comprehensively, and a catastrophic failure-cost ceiling. The reason it stays in pilot is not that the model is not smart enough. It is that no responsible operator will hand production write access to a system that is right most of the time.
The multi-agent swarm. Several agents that plan their own work, delegate to each other, and coordinate toward a high-level goal. Each agent multiplies the others' error rates, the cost compounds with every inter-agent message, and the auditability collapses because the path through the system is different every run. There are narrow research uses for multi-agent setups, but as a general enterprise pattern in 2026, the swarm is the purest demoware in the category. The failure modes here are well catalogued in the analysis of why AI agent frameworks break in production.
The pattern across the failures is the inverse of the successes. Unbounded scope, broad permissions, weak evaluation, and high failure cost. The model is not the bottleneck. The system design is.
Working Patterns vs Demoware: A Side-by-Side
| Dimension | Patterns that ship | Patterns that stall |
|---|---|---|
| Task scope | Narrow, one checkable job | Open-ended, "do the job" |
| Tool access | Least-privilege, read-mostly | Broad, including write and external actions |
| Human role | Approves consequential actions | Removed for "full autonomy" |
| Evaluation | Real harness, regression-tested | Demo-tested on a handful of cases |
| Failure cost | Low and recoverable | High and reaches the world directly |
| Cost profile | Predictable per task | Unbounded loops, compounding token spend |
| Auditability | Path is constrained and loggable | Path differs every run |
The table is the article in miniature. The shippable column is constrained on every axis. The stalled column is unconstrained on every axis. Constraint is the feature, not the limitation.
The Readiness Checklist
Before greenlighting an agent project, an organization should be able to answer yes to all of the following. A no on any line is a reason to either redesign the project or choose a simpler pattern.
- The task has a clear definition of done and a checkable output.
- The agent needs the smallest possible set of tools, and the consequential ones are gated behind human approval.
- A real evaluation set of representative inputs exists, with a scoring function, before any build begins.
- The worst-case outcome of a wrong answer is cheap and recoverable.
- There is a per-task cost ceiling and a maximum loop count, so a runaway agent cannot run up an unbounded bill.
- Every action the agent takes is logged in a form a human can audit after the fact.
- A human owns the final decision for anything that touches a customer, a financial transaction, or a production system.
- The team has compared the agent approach against a deterministic workflow and a single model call, and the agent is genuinely necessary.
This last item is the one most often skipped and the one that saves the most money. The economics of getting it wrong are not abstract: the infrastructure, token, and engineering costs of an over-built agent are real and recurring, as laid out in the breakdown of the real cost of AI infrastructure.
The Decision That Comes First: Agent, Workflow, or Single Call
The most expensive mistake in this space is reaching for an agent when a simpler pattern would do. Agents are the heaviest, least predictable, most expensive, and hardest-to-audit option. They should be the last resort, chosen only when the lighter options genuinely cannot do the job.
The decision tree is short:
- Can a single model call do it? If the task is one transformation, classify this, summarize that, extract these fields in one pass, use a single LLM call. No loop, no tools, no agent. This covers far more enterprise tasks than the agent marketing admits.
- If not, is the path through the task fixed? If you can write down the steps in advance, fetch the record, call the model, validate the output, write the result, then build a deterministic workflow. Some steps may call a model. But the engineer controls the sequence, which makes the system predictable, cheap, and auditable. Most "agent" projects are workflow projects.
- Only if the path genuinely cannot be predetermined because the right next step depends on results the system has not seen, do you need an agent. And even then, constrain it on all four variables: bound the task, scope the tools, build the eval harness, and cap the failure cost.
This sequence is a close relative of the customization decision executives already face with language models, where the instinct to reach for the heaviest tool is similarly expensive. The framework in fine-tuning vs RAG vs long-context makes the same core point in a different domain: match the weight of the solution to the actual shape of the problem, and resist the pull of the most impressive option.
The organizations getting real value from AI in 2026 are not the ones with the most agents. They are the ones that correctly identified the small set of tasks that genuinely need an agent, built those few agents with discipline, and used single calls and deterministic workflows for everything else. The discipline of saying no to the agent is what makes the rare yes work.
FAQ
What is the difference between an AI agent and a chatbot?
A chatbot responds to messages in a conversation. An AI agent takes actions through tools to accomplish a goal, looping between deciding, acting, and observing results until the task is done. A chatbot talks. An agent does, by calling functions, querying systems, and executing steps. Many products labelled chatbots are now simple agents, and many products labelled agents are really just chatbots with a tool or two.
Why do most enterprise AI agent projects fail?
They fail on system design, not model intelligence. The common causes are choosing an unbounded task with no checkable definition of done, granting broad tool and write permissions, skipping the evaluation harness, and removing the human from consequential decisions. Agents that fail score poorly on at least one of the four variables: task boundedness, tool scope, evaluation coverage, and failure-cost ceiling. The model is rarely the bottleneck.
When should we build an agent instead of a deterministic workflow?
Build an agent only when the path through the task genuinely cannot be predetermined, because the right next step depends on results the system has not yet seen. If you can write the steps down in advance, build a workflow instead. Workflows are cheaper, more predictable, and easier to audit. Most tasks pitched as agent problems are actually workflow problems.
What are the safest first AI agent use cases for an enterprise?
The lowest-risk, highest-return starting points are ticket triage and routing, code review assistance, structured data extraction from documents, and first-draft generation with a human approver. All four share a bounded task, constrained read-mostly tools, a checkable output, and a human who owns the final decision. They deliver measurable value without the reliability and auditability problems of full autonomy.
How do we control the cost of running AI agents?
Cap the cost at the system level, not just the model level. Set a maximum loop count and a per-task token budget so a runaway agent cannot run up an unbounded bill, log every tool call, and monitor cost per completed task as a first-class metric. The hidden cost in agents is the loop: an agent that retries, branches, and explores can cost many times more than a single call for the same outcome.
Related reading on FinTekCafe
Related Articles
The Total Cost of AI: A Framework for Pricing an AI Initiative End to End
An eight-line total cost of ownership framework for enterprise AI, with a worked example, realistic cost shares, and a build-buy-wait decision table.

AI Governance: How to Build an AI Policy That Actually Gets Followed
Why AI policies fail as documents and work as controls: a three-tier governance model, ownership patterns, EU AI Act duties, and metrics that matter.

Seat Pricing Is Dying: How AI Is Repricing the Software Industry
AI agents break the per-seat model at the root. The pricing ladder replacing it, the failure modes of each rung, and the buyer playbook for the transition.