What Is Agentic AI? An Executive's Guide to the Next Generation of AI Systems

Key Takeaways
- Agentic AI is not a smarter chatbot. The defining shift is autonomy across multiple steps, including tool use, planning, and self-correction.
- Three tiers of agents exist in production today, and most enterprise value sits in the middle tier, not in fully autonomous multi-agent systems.
- Four hard problems decide whether an agent project ships or fails: memory, tool reliability, cost runaway, and observability.
- Vendor selection should be driven by evaluation harnesses and production telemetry, not demo videos or benchmark scores.
- A pragmatic maturity model and a buy-versus-build decision tree prevent the two most common failures: over-engineering and vendor lock-in to immature platforms.
The Real Shift From Chatbots to Agents
Most enterprise AI conversations from 2023 and 2024 centered on retrieval-augmented chatbots that answered questions over a fixed knowledge base. That category is now commoditized. The leading edge has moved to systems that take actions, not just produce text. The change in cost structure, risk profile, and operational requirements is significant enough that treating agents as a feature upgrade to existing chatbot deployments is the most common strategic mistake of 2026.
An agent is a system that, given a goal, can plan a sequence of steps, invoke tools or APIs to execute those steps, observe the results, and adjust its plan based on what it learns. The combination of planning plus tool use plus iterative correction defines the category. A model that calls one function and returns a result is not an agent. A model that decides which function to call, in what order, and whether to retry or escalate is an agent.
The reason this distinction matters for executives is that the failure modes change completely. A bad chatbot answers a question incorrectly. A bad agent submits a refund, sends an email, books a meeting, or modifies a record incorrectly. The blast radius is wider, the audit trail is more complex, and the governance requirements look more like robotic process automation than like search.
The Three Tiers of Agentic AI
A framework that has held up across several hundred enterprise deployments distinguishes three tiers based on autonomy and orchestration. The tiers are not a maturity ladder where every organization should aim for tier three. They are different products for different problems.
Tier 1: Single-Step Assistants
A single-step assistant takes a request, optionally calls one or two tools, and returns a result. Most copilots inside productivity software fit this tier. The assistant drafts an email, summarizes a meeting, or answers a question with a calculation pulled from a spreadsheet.
The economics are well understood. Latency is acceptable, cost is predictable, and the human remains in control of every action. This is the safest tier to deploy at scale and the right starting point for organizations new to AI.
Tier 2: Tool-Using Agents
A tool-using agent works toward a goal across multiple steps. It might gather information from three systems, transform it, decide what to do, and either complete the work or escalate to a human. Customer operations triage, code generation against a real repository, and finance reconciliation across multiple ledgers all fit this tier.
This is where the majority of enterprise value sits today. The agent does enough to be useful but operates within a narrow domain with well-understood tools. Production deployments at this tier consistently report cost savings between 25 and 45 percent on the targeted workflow once the system is stable.
Tier 3: Multi-Agent Orchestration
A multi-agent system coordinates several specialized agents under a planner or supervisor. The supervisor decomposes a goal into sub-goals, assigns each to a worker agent, and reconciles the results. Examples include research synthesis pipelines, complex software engineering tasks, and end-to-end procurement workflows.
Tier three is where vendor marketing concentrates and where production reality lags marketing by a wide margin. The coordination overhead, the failure modes when one agent corrupts another's context, and the cost of running multiple long-context inferences in parallel make tier three projects fragile. Organizations should resist the pressure to skip tier two and go directly to tier three. Every successful tier three deployment observed in 2026 started as a stable tier two system that was then decomposed.
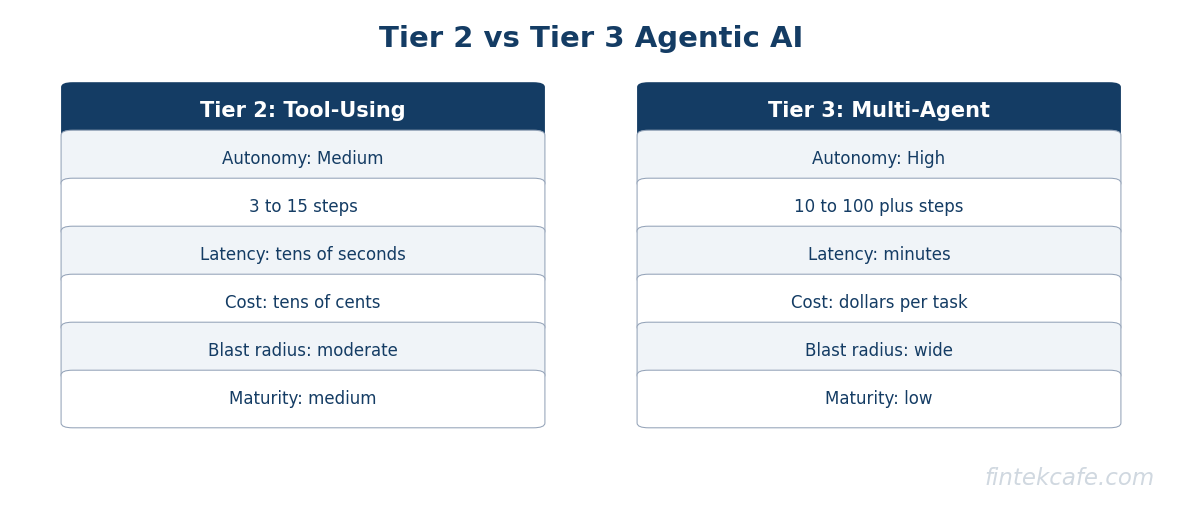
Tier Comparison Table
| Dimension | Tier 1: Single-Step | Tier 2: Tool-Using | Tier 3: Multi-Agent |
|---|---|---|---|
| Autonomy | Low | Medium | High |
| Typical steps per task | 1 to 2 | 3 to 15 | 10 to 100 plus |
| Latency | Seconds | Tens of seconds | Minutes |
| Cost per task | Cents | Tens of cents | Dollars |
| Failure blast radius | Narrow | Moderate | Wide |
| Human approval | Per response | Per workflow | Per outcome |
| Production maturity | High | Medium | Low |
| Recommended for | Most teams | Most operational workflows | Specialized R and D |
Enterprise Use Cases That Are Working
The hype cycle has produced a long list of speculative applications. The use cases below are the ones with consistent production evidence across multiple industries as of early 2026.
Customer Operations Triage
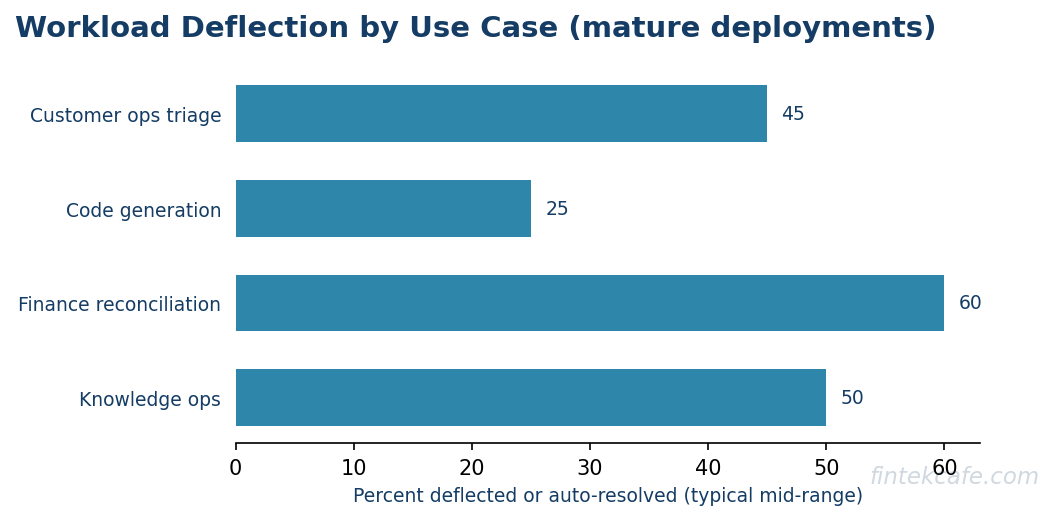
Tier two agents that read inbound tickets, fetch context from CRM and order systems, classify intent, draft a response, and either send the response or route to a human handle between 30 and 60 percent of inbound volume in mature deployments. The crucial design choice is the escalation path. Agents that default to human review for any uncertain case outperform agents tuned for full automation.
Code Generation Against Real Repositories
Software engineering agents that operate inside a real repository, run tests, and iterate on failures have moved from research demos to daily production tools. The honest measurement is not lines of code generated but pull requests merged after human review. Across multiple enterprise pilots, code agents close between 15 and 35 percent of well-scoped engineering tickets without intervention. The economic value is real but the productivity claims of 10x improvement are not supported by the data.
Finance Reconciliation
Reconciliation across general ledgers, sub-ledgers, and external statements is repetitive, rules-based, and tolerant of latency. Agents in this category surface anomalies, propose journal entries for human approval, and generate audit-ready trails. The combination of structured data and clear correctness criteria makes finance reconciliation one of the highest-confidence applications for tier two agents.
Internal Knowledge Operations
Agents that answer employee questions about benefits, policies, expense rules, and procurement deflect a large portion of routine HR and IT support tickets. The deployment pattern that works combines a strong retrieval system with narrow tool use, such as the ability to file a ticket or look up a status.
Research and Competitive Intelligence
Tier three multi-agent systems that gather, summarize, and synthesize external research deliver value when scoped narrowly. The systems that work best avoid open-ended research goals and instead target specific recurring questions, such as weekly competitor pricing changes or earnings call summaries.
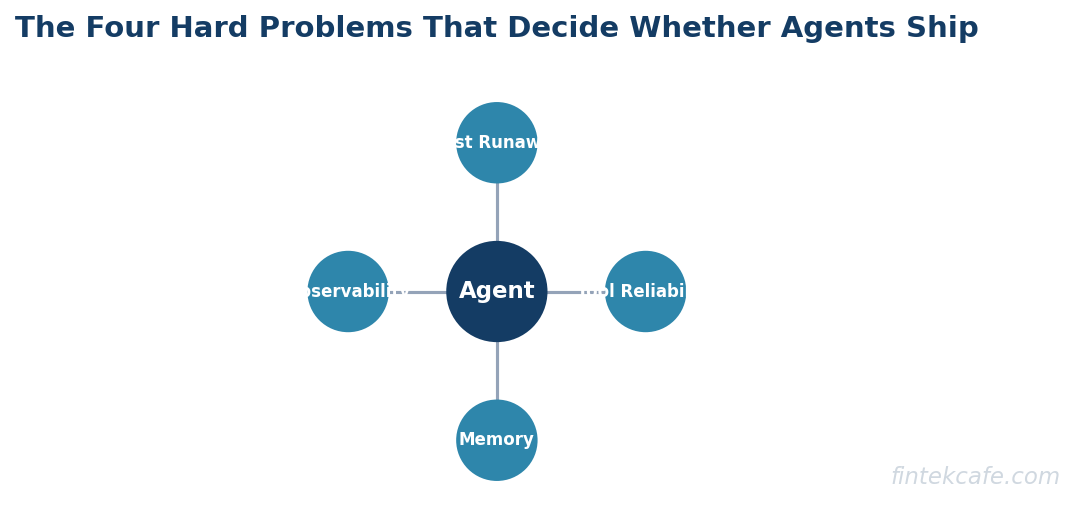
The Four Hard Problems
The gap between a working demo and a production system at scale comes down to four engineering problems. Every executive funding an agent program should ask the team how each problem is being addressed.
Memory
Agents need to remember context across a single task, across a session, and sometimes across users. Naive approaches put everything in the context window and pay the cost in latency and bills. Sophisticated approaches use a tiered memory system: working memory in context, episodic memory in a vector store, and structured memory in a database. The choice of memory architecture is the single largest determinant of whether the system can scale beyond demos.
Tool Reliability
Agents call tools that fail. APIs return errors, rate limits trigger, schemas change. A production agent needs retry logic, fallback paths, and graceful degradation. The rule of thumb is that an agent calling ten tools with 99 percent reliability each has roughly a 90 percent chance of completing successfully. At 95 percent reliability per tool, the success rate drops to 60 percent. Tool reliability compounds.
Cost Runaway
Long-context, multi-step agents are expensive. A single complex agent task can cost between fifty cents and several dollars. Without budget controls, a runaway agent in a loop can generate hundreds of dollars in costs in minutes. Production systems require hard budget caps per task, alerting on cost anomalies, and the ability to kill long-running tasks. Treat agent cost like cloud infrastructure cost: tagged, monitored, and governed.
Observability
When an agent makes a wrong decision, the team needs to understand why. This requires structured logging of every decision, every tool call, every model output, and every state transition. Generic application logging does not capture this. Purpose-built agent observability platforms have emerged in 2025 and 2026, and any serious production deployment should adopt one rather than reinventing the tooling internally.
Hard Problems Compared
| Problem | Symptom | Solution Pattern |
|---|---|---|
| Memory | Forgets context, repeats work | Tiered memory: working, episodic, structured |
| Tool reliability | Random failures, partial outputs | Retries, fallbacks, circuit breakers |
| Cost runaway | Surprise cloud bills | Per-task budget caps, real-time cost telemetry |
| Observability | Cannot diagnose failures | Structured trace logs, agent-specific tooling |
How to Evaluate Vendors
The agentic AI vendor landscape in 2026 includes hyperscaler platforms, specialized agent frameworks, vertical applications, and traditional enterprise software vendors retrofitting agent capabilities. The evaluation process that holds up across this diversity focuses on four questions.
First, can the vendor produce an evaluation harness for your use case? A vendor that cannot run a structured eval against your data, with your tools, and report quantitative results is not ready for an enterprise deployment. Demos are not evidence.
Second, what does the vendor's production telemetry look like? The team should be able to show you, on a real customer deployment, what their observability stack reports for cost per task, success rates, and failure modes. If the vendor cannot answer these questions for an existing customer, they cannot answer them for you either.
Third, how does the vendor handle the hard problems? Ask specifically about memory architecture, tool reliability patterns, cost controls, and observability tooling. Vague answers indicate the vendor is selling demos, not production systems.
Fourth, what is the exit cost? Agent platforms create lock-in through prompt libraries, tool integrations, memory schemas, and observability data. A vendor that does not offer a clean export path is selling a long-term dependency. The right time to negotiate exit terms is before signing.
Maturity Model for Enterprise Agentic AI
Five stages capture how organizations actually mature agentic AI capabilities. Most enterprises in 2026 sit between stage one and stage two.
Stage 1: Experimentation
Individual teams run pilots, often without coordination. Spending is small, governance is minimal, and most pilots do not reach production. The right action at this stage is to allow the experimentation to continue while quietly cataloging which patterns are working.
Stage 2: First Production Agent
One or two tier-two agents move into production with clear ownership and budget. Observability, cost controls, and governance start to take shape. This stage typically lasts six to nine months and produces the first measurable business outcomes.
Stage 3: Platform Foundation
The organization recognizes that every team is rebuilding the same infrastructure. A platform team forms to provide shared memory, tool catalogs, evaluation infrastructure, and observability. Without this stage, costs scale linearly with the number of agents and reliability remains brittle.
Stage 4: Portfolio of Agents
Multiple production agents operate across business units. The platform supports them, governance is mature, and the focus shifts from building agents to managing the portfolio: which agents to retire, which to expand, where to invest next.
Stage 5: Multi-Agent Systems
Only at stage five do multi-agent systems start to appear, and only for problems where the additional complexity is justified. Most organizations should not aim for stage five. Stage four is the durable competitive position.
Buy-Versus-Build Decision Framework
The buy-versus-build question is more nuanced for agents than for traditional enterprise software. The framework below cuts through the marketing.
Is the use case core to your competitive differentiation?
Yes -> Build on a foundation model and a thin agent framework
No -> Continue
Is there a specialized vendor with production references in your industry?
Yes -> Buy the specialized vendor
No -> Continue
Is the use case a horizontal capability (customer ops, IT support, reconciliation)?
Yes -> Buy a horizontal agent platform
No -> Build with a foundation model and a thin agent framework
The instinct to build everything internally is usually wrong. The instinct to buy a single platform that does everything is also usually wrong. The right answer for most organizations is a small number of specialized purchases for horizontal use cases combined with internal builds for differentiating workflows, all running on shared platform infrastructure managed by a central team.
Buy-Versus-Build Tradeoffs
| Approach | Speed to Production | Differentiation | Lock-In Risk | Total Cost |
|---|---|---|---|---|
| Build on foundation model | Slow | High | Low | High initially, low at scale |
| Specialized vendor | Fast | Low | Medium | Medium |
| Horizontal platform | Medium | Low | High | Low initially, high at scale |
| Hybrid (recommended) | Medium | High where it matters | Medium | Optimized |
What to Do in the Next 90 Days
Three actions separate organizations that capture value from agentic AI from those that produce slide decks about it.
First, stand up a single tier two agent in production. Pick a workflow with clear success metrics, well-understood data, and a willing business sponsor. Customer operations triage and finance reconciliation are the two strongest starting points across industries.
Second, fund the platform foundation. Even before there are three agents to support, the platform team should be hiring. Memory architecture, tool catalogs, and observability tooling take six to twelve months to mature. Starting late is the most expensive mistake at stage three.
Third, write a one-page governance charter. It should specify how agent decisions are reviewed, who approves new tools, how incidents are handled, and how cost is governed. The charter is short on purpose. Long governance documents become shelf-ware.
Frequently Asked Questions
How is agentic AI different from generative AI?
Generative AI produces content in response to a prompt. Agentic AI takes a goal, plans steps to achieve it, calls tools, and adjusts based on results. Generative AI is a component inside an agent, but the agent is the system that takes action over time.
Are multi-agent systems worth the complexity?
For most organizations, no. A well-designed tier two agent solves the majority of business problems with a fraction of the operational risk. Multi-agent systems become valuable only after the platform foundation supports them and only for problems where decomposition genuinely helps.
What is a realistic ROI timeline for an agent project?
A scoped tier two agent in customer operations or finance reconciliation typically reaches break-even between nine and fifteen months from kickoff. Projects targeting tier three or open-ended research goals often do not reach break-even at all and should be funded as research, not as production initiatives.
How should governance work for agent decisions?
Governance should look more like change management than like model governance. Every tool an agent can call is reviewed before it is added. Every workflow has a defined escalation path. Every action is logged with sufficient detail for audit. The model itself is one component among many; the system is what is governed.
What internal skills are needed to build agents?
A working agent team needs at least one applied AI engineer who understands prompting and evaluation, one platform engineer who understands distributed systems and observability, and one domain expert from the business unit. Organizations that try to build agents with only data scientists consistently underinvest in the engineering side and produce fragile systems.
When does it make sense to wait rather than act?
Almost never. The cost of building tier one and tier two capabilities is small compared to the organizational learning produced. Waiting for the technology to settle is the most expensive form of caution available in 2026.
Internal Reading
Related Articles
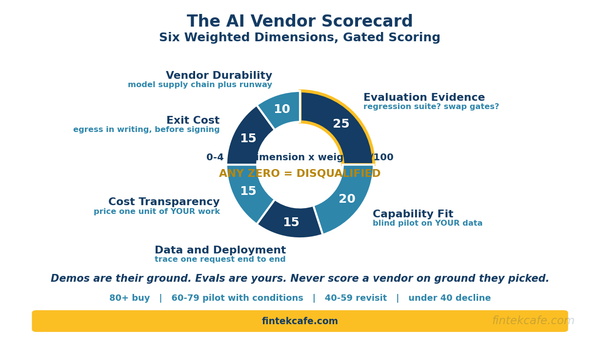
The AI Vendor Evaluation Framework: How to Score AI Products Before You Buy
A six-dimension scoring framework for evaluating AI vendors, with weights, pass/fail gate questions, and a matrix a buyer can apply in a live meeting.

LLM Observability: How to Monitor AI Systems in Production
Why classic APM misses LLM failures, the four signal layers of LLM observability, what to alert on, and how production traces feed the evaluation loop.

Evals Are the Moat: Why AI Products Defend on Evaluation, Not Models
The durable moat in applied AI is not the model. It is the eval suite: the one asset competitors cannot rent, and the one due diligence should price.