Real-Time Fraud Detection: How Payments Risk Moved to Milliseconds
Key Takeaways
- Instant payments removed the float that fraud teams quietly depended on. When settlement is irreversible and clears in seconds, the window to investigate, hold, or claw back a suspicious transaction collapses, and batch or rules-only fraud systems stop working.
- The burden has shifted to sub-second scoring at authorization time. A fraud decision now has to happen inside the payment, not after it, which changes the architecture from overnight batch jobs to a real-time scoring path measured in tens of milliseconds.
- The modern model stack combines graph features, device and behavioral signals, and consortium or shared intelligence. No single signal is sufficient, because sophisticated fraud is designed to look normal on any one dimension.
- The dominant cost is no longer only fraud losses. It is false positives. Every legitimate transaction wrongly blocked is lost revenue, a frustrated customer, and a support cost, and at instant-payment speed there is no human review step to soften the error.
- Machine learning helps most where it scores known patterns at speed and scale, and adds risk where its decisions are opaque and unexplainable to regulators. The defensible architecture layers deterministic rules, interpretable models, and shared intelligence rather than betting everything on one opaque model.
The Float Is Gone, and With It the Old Playbook
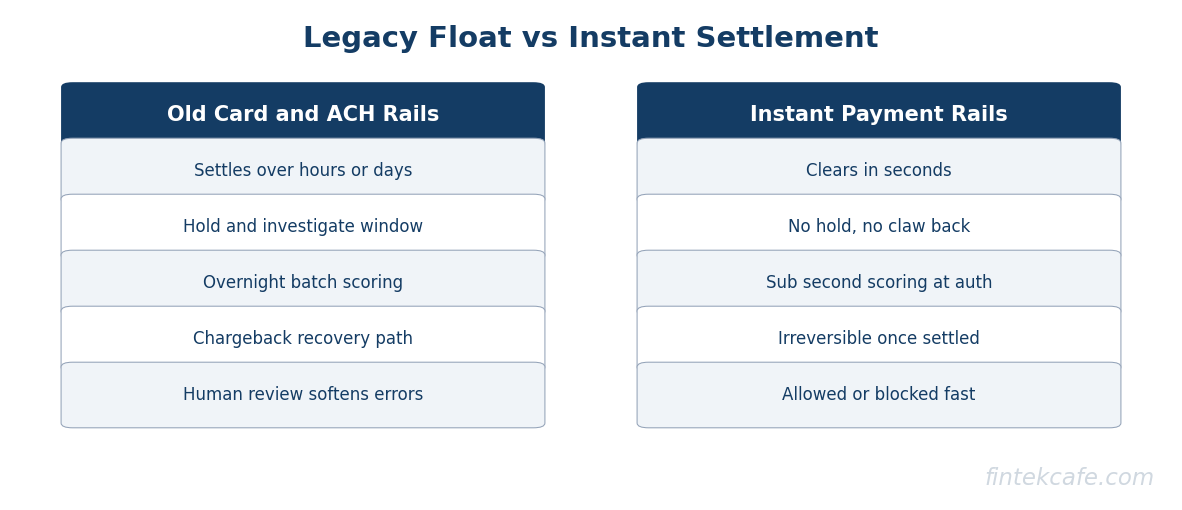
For decades, fraud operations ran on a hidden asset: time. Card and ACH systems settled over hours or days, which gave fraud teams a window. A suspicious transaction could be flagged, held for review, investigated, and reversed before money truly left the institution. Batch fraud jobs that ran overnight were adequate because the money had not gone anywhere yet. That window, the float between authorization and irreversible settlement, was the foundation the entire playbook rested on.
Instant payment rails removed it. When a payment clears in seconds and cannot be reversed, the float is zero. There is no overnight batch to catch the fraud, no hold-and-investigate step, no claw-back. The decision to allow or block has to be made before the money moves, which in practice means inside a window of tens of milliseconds at authorization. The launch and growth of real-time rails, covered in the explainer on what FedNow and real-time payments are, is what forced this change from a nice-to-have into a requirement.
The strategic consequence is blunt. Any institution moving onto instant rails with a batch or rules-only fraud system is exposed, because the system was designed around a float that no longer exists. The fraud function has to move from after-the-fact investigation to in-the-moment scoring, and that is an architectural change, not a tuning exercise.
What Changed With Real-Time Rails
Three things changed at once when instant payments scaled, and each one breaks a different assumption in legacy fraud systems.
Irreversibility. Once an instant payment settles, it is gone. There is no chargeback mechanism comparable to cards. This shifts the entire burden of fraud prevention to the moment before authorization, because there is no recovery path after it. The institution either catches the fraud in real time or eats the loss.
Speed. The payment clears in seconds, often under twenty. The fraud decision therefore has to fit inside the authorization path without making the payment feel slow. A scoring system that takes two seconds is not an option when the whole payment is expected to complete in a handful. This is why real-time fraud detection is as much a latency engineering problem as a data-science problem.
New fraud patterns. Irreversible, instant settlement is exactly what authorized-push-payment fraud and scams exploit. The fraudster does not need to steal credentials if they can convince the legitimate account holder to send the money themselves, because once sent it cannot be recovered. This shifts the detection target from compromised accounts toward manipulated-but-legitimate users, a far harder signal to read. The friction this creates for institutions adopting the rails is examined in the analysis of why mid-sized banks hesitate on FedNow adoption, and fraud exposure is high on that list.
The Modern Model Stack
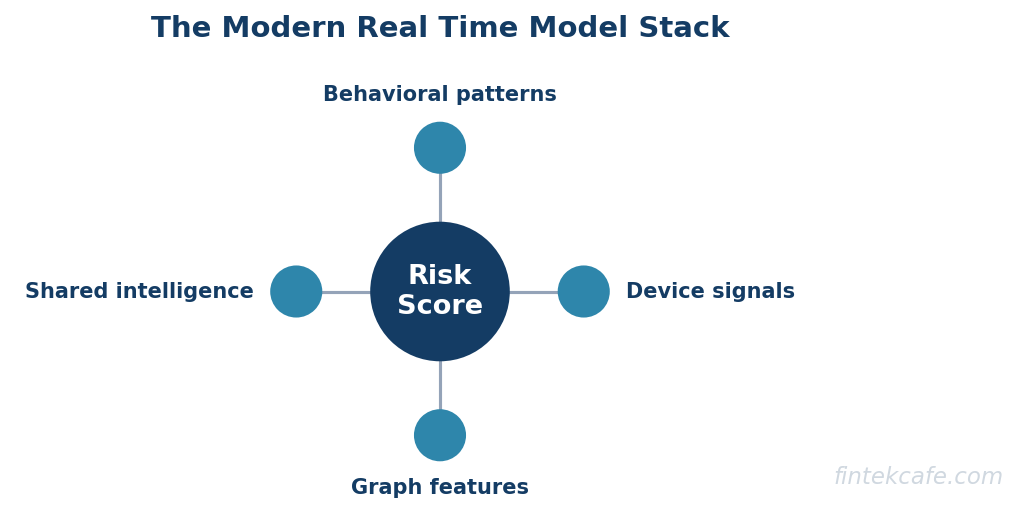
Real-time fraud detection in 2026 is not one model. It is a stack of complementary signals, each catching what the others miss, combined into a single score inside the authorization window.
Graph features
Fraud is rarely a single isolated event. It happens in rings, networks of accounts, devices, and counterparties that share structure. Graph features capture that structure: how many accounts a device has touched, how tightly a cluster of accounts transacts among themselves, whether a new payee is connected to known-bad nodes. A transaction that looks ordinary in isolation often looks alarming in its graph context, and graph features are how that context enters the score.
Device and behavioral signals
Who is initiating the payment, and does the way they are doing it match how they normally behave? Device fingerprinting, session behavior, typing and navigation patterns, and the physical and logical context of the request all feed a behavioral profile. A login from a known device behaving normally is low risk. The same account, on the same credentials, behaving in a way that does not match its own history is the signal that catches account takeover and, increasingly, scam-induced payments where the user is being coached in real time.
Consortium and shared intelligence
No single institution sees enough fraud to recognize every pattern, especially new ones. Consortium data, shared intelligence about known-bad accounts, devices, and payees across institutions, lets a bank benefit from fraud another bank already saw. A payee freshly reported as fraudulent at one institution can be scored as high risk at another before it ever does damage there. Shared intelligence is one of the few mechanisms that lets defense move at something approaching the speed of organized fraud.
The deeper architecture of how these signals are engineered, served, and combined is the subject of the machine-learning fraud-detection system architecture walkthrough, which covers the feature stores and serving paths that make sub-second scoring feasible.
The False-Positive Cost Problem
The instinct under pressure is to tighten the system until fraud losses fall, but that instinct is dangerous, because the dominant cost in a real-time system is usually not fraud losses. It is false positives.
Every legitimate transaction the system blocks is three costs at once: lost revenue from the transaction, a customer whose trust and convenience were damaged, and a support interaction to resolve the block. At scale, the aggregate cost of false positives frequently exceeds the fraud losses they were meant to prevent. And at instant-payment speed there is no graceful human-review step to soften a wrong decision, the payment is either allowed or it is not, in milliseconds.
This reframes the objective. The goal is not to minimize fraud at any cost. It is to optimize the trade-off between fraud caught and legitimate activity blocked, expressed in money rather than in detection rates. A model that catches two percent more fraud while doubling false positives is usually a worse model in business terms, even though its fraud-detection metric improved. Stating that trade-off in financial terms, and owning it at the executive level, is what keeps a fraud program from quietly destroying more value than it protects.
A Layered-Defense Framework
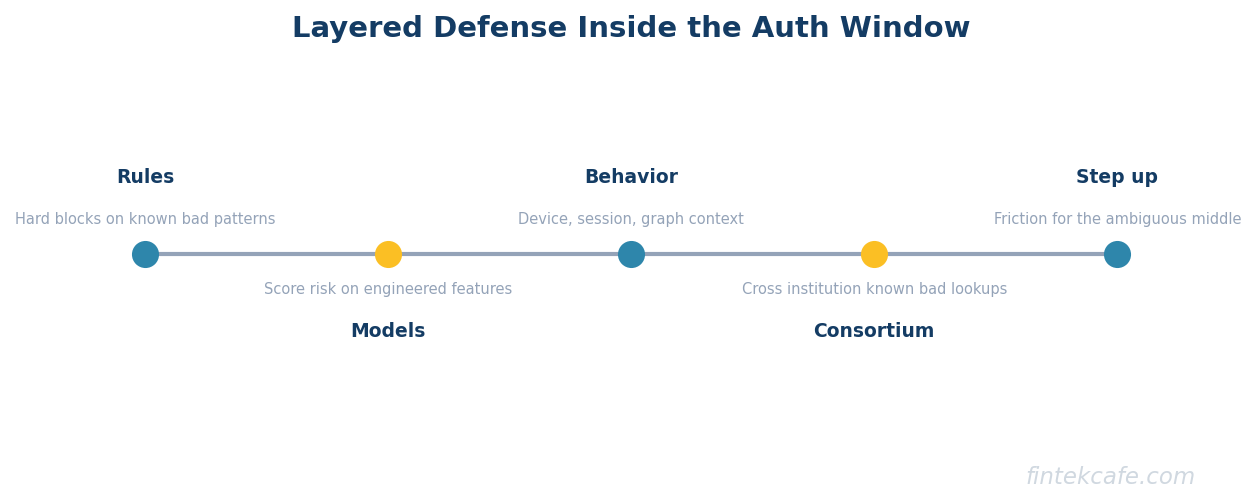
The defensible architecture does not bet everything on one model. It layers defenses so that each layer handles what it is best at and the failure of any single layer is not catastrophic. The layers run in sequence inside the authorization window, cheapest and fastest first.
| Layer | What it does | Why it sits here | Primary limit |
|---|---|---|---|
| 1. Deterministic rules | Hard blocks on known-bad patterns and policy limits | Fast, explainable, zero ambiguity | Brittle, cannot generalize to new fraud |
| 2. Interpretable models | Score risk on engineered features with explainable output | Catches patterns rules miss, stays auditable | Needs feature engineering and retraining |
| 3. Behavioral and graph signals | Add context: device, session, network structure | Catches takeover and scam patterns | Data-intensive, latency-sensitive |
| 4. Consortium intelligence | Cross-institution known-bad lookups | Catches fraud first seen elsewhere | Depends on data-sharing participation |
| 5. Step-up and human escalation | Friction or review for the ambiguous middle | Reduces false positives on borderline cases | Adds latency, limited at instant speed |
The sequencing matters. Deterministic rules sit first because they are cheap, fast, and fully explainable, which means the easy decisions never reach the expensive layers. The models and behavioral signals handle the ambiguous middle. Consortium lookups add intelligence the institution could not generate alone. The final layer, step-up authentication or escalation, is reserved for the genuinely ambiguous cases, and it is deliberately thin because instant payments leave little room for it.
The principle underneath the framework is defense in depth. Each layer compensates for the weaknesses of the others, so that the brittleness of rules is covered by models, the opacity of models is bounded by interpretable scoring and rules, and the blind spots of any single institution are covered by shared intelligence.
Where AI Helps and Where It Adds Opaque Risk
Machine learning is essential to modern fraud detection, but the honest framing names both sides.
AI helps most where it scores well-understood risk at a speed and scale no human or static rule can match. Pattern recognition across millions of transactions, anomaly detection against an account's own history, and ranking the riskiness of a new payee are all tasks where models clearly outperform rules. The throughput and latency requirements of instant payments make automation not just helpful but mandatory.
AI adds risk where its decisions are opaque and cannot be explained. A fraud decision that blocks a customer or, worse, that contributes to a pattern of decisions a regulator deems discriminatory, has to be defensible. A model that cannot explain why it scored a transaction as fraudulent is a liability in a regulated function, regardless of its accuracy. This is why interpretable models sit as their own layer in the framework and why the most opaque techniques are best used as one input among many rather than as the final authority.
The discipline that keeps this safe is the same one that governs any high-stakes automated decision: a real evaluation regime, explainability requirements proportional to the decision's impact, and a human-owned policy for the cases the model is not trusted to decide alone. The broader case for narrowing where automated systems are trusted to act, and where a human stays in the loop, is laid out in the enterprise guide to what AI agents actually do reliably in 2026.
Build Versus Buy for Mid-Sized Banks and Fintechs
For a large bank with a standing data-science organization, building a bespoke real-time fraud platform can be justified. For mid-sized banks and most fintechs, the calculus is different, and buying or assembling is frequently the disciplined choice.
The reason is the same one that governs most platform decisions: a real-time fraud system is not a project that ends, it is a product that must be operated, retrained, and defended for as long as the institution processes payments. Fraud patterns evolve continuously, which means the models decay continuously, which means the system needs a standing team to keep it current. Vendors that specialize in fraud detection spread that operating cost and, crucially, see fraud across many institutions, which feeds the consortium intelligence layer that a single mid-sized institution cannot build alone.
| Factor | Build in-house | Buy or assemble |
|---|---|---|
| Best fit | Large banks with standing data-science teams | Mid-sized banks and most fintechs |
| Consortium data | Limited to own footprint | Vendor sees cross-institution fraud |
| Time to protection | Long, with model bootstrapping risk | Fast, with pretrained models |
| Ongoing burden | Permanent retraining and ops team | Shared across vendor's customers |
| Explainability control | Full, if built for it | Depends on vendor transparency |
| Risk | Model decay, talent dependence | Vendor lock-in, opaque vendor models |
The deciding questions are whether the institution can fund a permanent fraud-modeling team and whether it has enough transaction volume to train models that generalize. When the answer to either is no, assembling specialized vendors with strong consortium data and acceptable explainability is the move that protects customers fastest. The same real-time, irreversible dynamics are reshaping cross-border flows as well, a shift traced in the analysis of real-time cross-border payments across SWIFT, Wise, and Ripple in 2026, and fraud exposure travels with the speed.
Key Takeaways for Decision-Makers
Instant payments removed the float that the old fraud playbook depended on, and with it the option to investigate after the fact. The fraud decision now lives inside the payment, in a window of tens of milliseconds, which makes real-time fraud detection a latency and architecture problem as much as a modeling one. The defensible design layers deterministic rules, interpretable models, behavioral and graph signals, and consortium intelligence rather than betting on a single opaque model, and it optimizes the trade-off between fraud caught and legitimate activity blocked in financial terms. For mid-sized banks and fintechs, the operating burden and the value of shared intelligence usually tilt the build-versus-buy decision toward buying.
Frequently Asked Questions
Why do instant payments make fraud harder to stop?
Instant payments clear in seconds and are irreversible, which removes the settlement float that fraud teams used to investigate, hold, and reverse suspicious transactions. With no float, there is no after-the-fact recovery, so the fraud decision has to be made before the money moves, inside a window of tens of milliseconds at authorization. Batch and rules-only systems built around the old float no longer work.
What signals does real-time fraud detection use?
The modern stack combines several complementary signals: graph features that capture the network structure of fraud rings, device and behavioral signals that detect when an account is being used unusually, and consortium or shared intelligence that flags accounts and payees already reported as fraudulent elsewhere. No single signal is sufficient, because sophisticated fraud is engineered to look normal on any one dimension.
Why are false positives such a big problem?
Every legitimate transaction wrongly blocked is lost revenue, a damaged customer relationship, and a support cost. At scale, the aggregate cost of false positives often exceeds the fraud losses they were meant to prevent, and at instant-payment speed there is no human-review step to soften a wrong decision. The right objective is to optimize the trade-off between fraud caught and legitimate activity blocked in financial terms, not to minimize fraud at any cost.
Where does AI help and where does it add risk in fraud detection?
AI helps most where it scores well-understood risk at a speed and scale that static rules and humans cannot match, such as anomaly detection and payee risk ranking. It adds risk where its decisions are opaque and cannot be explained to regulators or customers. The safe approach keeps interpretable models and deterministic rules as distinct layers and uses the most opaque techniques as one input among many rather than as the final authority.
Should a mid-sized bank build or buy a real-time fraud system?
For most mid-sized banks and fintechs, buying or assembling specialized vendors is the disciplined choice. A real-time fraud system is a product that must be retrained and operated permanently because fraud patterns decay models continuously, and most mid-sized institutions cannot fund a standing fraud-modeling team or generate the cross-institution data that powers consortium intelligence. Large banks with established data-science organizations are the main exception.
Related Articles

Payment Orchestration: Why Merchants Route Across Multiple Processors
At scale, single-processor checkout is a point of failure and a margin leak. How payment orchestration routes across processors to lift authorization rates.

Banking-as-a-Service Economics: Who Actually Makes Money
The BaaS pitch sells embedded banking as free margin. The economics are thinner and the profit pools somewhere founders rarely look. Here is where.

Real-Time Treasury: How Instant Settlement Rewires Corporate Cash Management
Instant rails do not just speed treasury up. They remove the delay it was built on. Here is what breaks and what CFOs should ask their banks.