Platform Engineering and Internal Developer Platforms: What Actually Reduces Cognitive Load

Key Takeaways
- Internal developer platforms are the most-hyped operating model in engineering, and most attempts produce a second layer of complexity on top of the first rather than removing it. The platforms that succeed reduce measurable cognitive load. The ones that fail add an abstraction nobody asked for.
- What works is a small, repeatable set of patterns: golden paths, self-service infrastructure, paved roads with explicit escape hatches, and a platform treated as a product with internal customers. What fails is mandatory abstractions, platform teams that build for their own taste, and tooling shipped without an adoption plan.
- The build-versus-buy decision is not Backstage versus a managed platform in the abstract. It is whether the organization has the staffing to operate a platform as a long-lived product. Most organizations under a few hundred engineers should buy or assemble managed components rather than build a bespoke portal.
- Platform return on investment is measurable with established delivery metrics: lead time for changes, change-failure rate, deployment frequency, and developer satisfaction. A platform that does not move these is not paying for itself, regardless of how polished the portal looks.
- The most expensive failure mode is building a platform before there is a paved road to pave. Standardize the underlying workflow first, then make it self-service. A portal over chaos is just chaos with a login screen.
The Promise and the Pattern of Failure
Platform engineering arrived with a clean promise: stop making every team reinvent deployment, infrastructure, and tooling, and instead give them a self-service platform that handles the undifferentiated work so they can focus on shipping product. Stated that way, it is hard to argue against, and the rush of the last few years reflects that. Nearly every engineering organization of meaningful size now has a platform team or intends to start one.
The results have been uneven, and the pattern of failure is consistent enough to name. A platform team forms, picks a developer portal, and begins building abstractions over the existing infrastructure. Months later the organization has a new system that developers must learn, that the platform team must maintain, and that sits between engineers and the tools they already understood. Cognitive load did not go down. It moved, and often it grew, because now there are two systems to reason about instead of one.
The distinction that matters is simple to state and hard to execute. A platform succeeds when it removes decisions and steps that developers should not have to make, and fails when it adds an abstraction they did not ask for and cannot bypass. Everything else in this analysis follows from that line.
What Actually Works
Four patterns separate the platforms that reduce cognitive load from the ones that add a layer.
Golden paths, not golden cages
A golden path is the supported, documented, well-lit way to do a common thing: stand up a new service, ship a change, provision a database. It works because it makes the right way the easy way. It fails the moment it becomes the only way. The organizations that get this right offer a golden path that handles the eighty percent case beautifully and let teams step off it when their case is genuinely different.
Self-service infrastructure
The single highest-leverage capability a platform provides is letting a developer provision what they need without filing a ticket and waiting on another team. Self-service is what converts the platform from a gatekeeper into an accelerator. The test is concrete: can a developer go from intent to provisioned, governed infrastructure in minutes, without a human in the loop, and within guardrails that keep the result compliant and cost-aware? Those cost guardrails matter more than they appear, because self-service without them is how cloud bills balloon, a dynamic the guide to Kubernetes cost optimization in 2026 traces in detail.
Paved roads with explicit escape hatches
The paved-road metaphor is more useful than golden path because it names the escape hatch directly. A paved road is fast and safe for ordinary travel, and you can still drive off it when you must. A platform without escape hatches forces every team with an unusual requirement into a confrontation with the platform team, and those confrontations are where adoption goes to die. The presence of a clean, supported way to opt out is what makes the supported path feel like a service rather than a mandate.
The platform as a product
The platforms that last are run as products with internal customers, a roadmap shaped by those customers, and adoption as the primary success metric. That means user research with developers, a backlog driven by their friction rather than the platform team's preferences, and a recognition that an unused capability is a failed capability no matter how elegant. This single mindset shift, from infrastructure project to internal product, predicts success better than any tooling choice.
What Actually Fails
The failure modes are as repeatable as the successes.
Mandatory abstractions. Any abstraction that developers cannot bypass becomes a tax the moment their need falls outside what it anticipated. Mandatory abstractions also remove the feedback signal: if teams cannot opt out, the platform team never learns which parts of the abstraction are actually wanted versus merely tolerated.
Platform teams that build for themselves. A platform team staffed entirely with infrastructure specialists tends to build the platform those specialists would want, which is not the platform an application developer needs. The symptom is a platform rich in configurability and poor in defaults, powerful for its authors and bewildering for its users.
Tooling without an adoption plan. Shipping a portal and announcing it is not adoption. Without active migration support, documentation, and a reason for teams to move, a new platform competes against the workflows people already know, and the incumbent workflow usually wins. Many platforms are technically complete and practically abandoned for exactly this reason.
A portal over chaos. The most expensive version of failure is building the self-service layer before standardizing the workflow underneath it. If three teams deploy three different ways, a portal that exposes all three does not reduce cognitive load, it documents the sprawl. The standardization has to come first, and the platform makes the standard easy. This is why a service catalog matters in platform engineering: cataloging what exists is the prerequisite to paving a road through it.
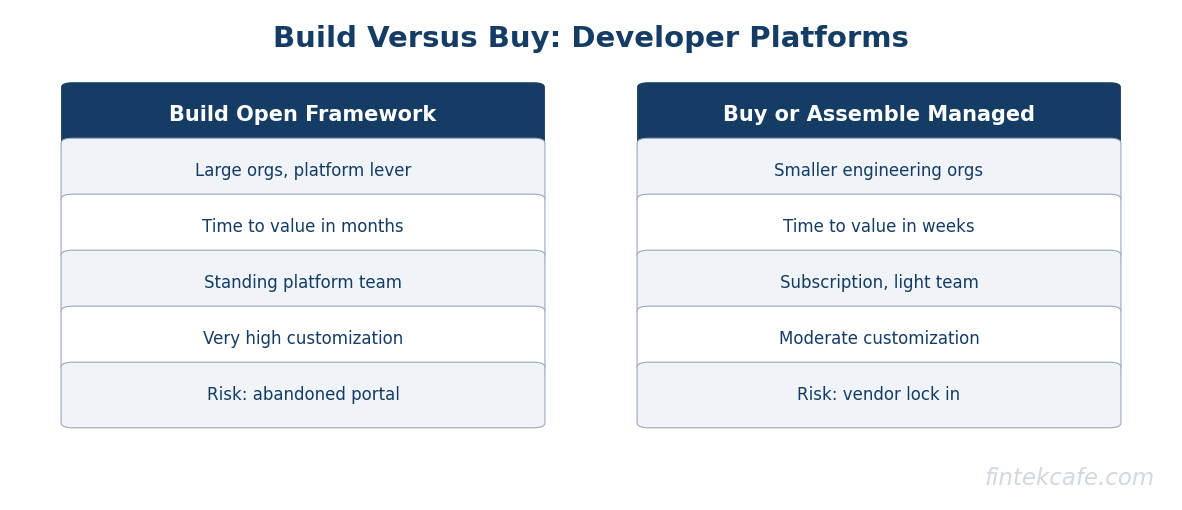
Build Versus Buy
The build-versus-buy question is usually framed as Backstage and its open-source peers against managed internal developer platforms. That framing hides the real variable, which is staffing.
A self-built portal on an open framework is not a project with an end date. It is a long-lived product that needs a standing team to operate, extend, and support it. Building can be the right answer for organizations large enough that the platform's specifics are a genuine competitive lever and that can fund a permanent platform team. For most organizations, the maintenance burden of a bespoke portal outweighs the benefit, and assembling managed components or adopting a managed platform delivers most of the value without the standing cost.
| Dimension | Build (open framework) | Buy or assemble managed |
|---|---|---|
| Best fit | Large orgs, platform as competitive lever | Most orgs under a few hundred engineers |
| Time to first value | Months | Weeks |
| Ongoing cost | Standing platform team required | Subscription plus lighter integration team |
| Customization ceiling | Very high | Moderate to high |
| Risk | Becomes an unfunded internal product | Vendor lock-in and roadmap dependence |
| Failure mode | Maintenance debt, abandoned portal | Outgrowing the managed tool's model |
The decisive question is not which tool is better in a feature matrix. It is whether the organization will fund the platform as a product for its entire life. If the honest answer is no, building a bespoke portal is choosing a maintenance liability, and the managed route is the disciplined choice.
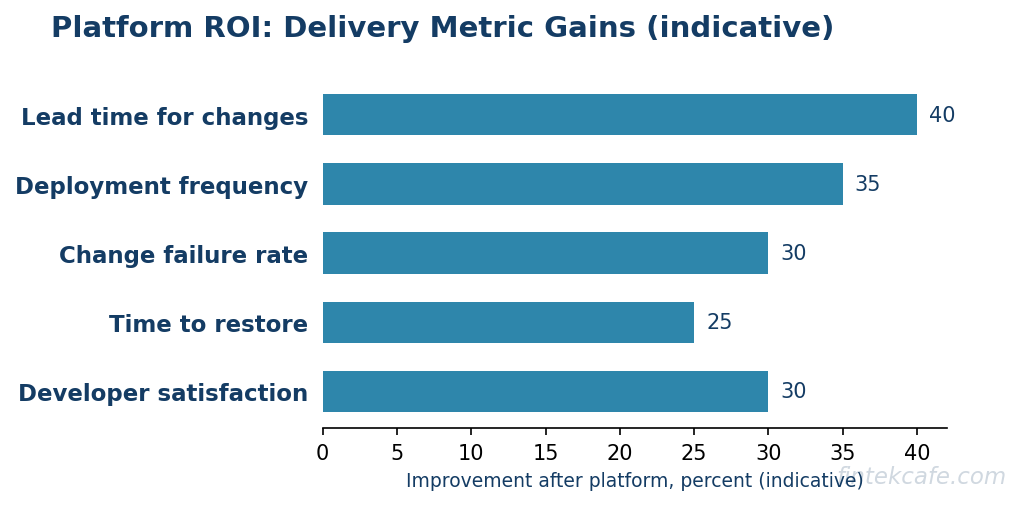
Measuring Platform ROI
A platform that cannot demonstrate impact on delivery is a cost center wearing the costume of an investment. The good news is that platform impact is measurable with established metrics rather than vanity numbers like portal logins.
- Lead time for changes. The time from code committed to code running in production. A platform that works shortens it, because the friction it removes lives mostly in this interval.
- Deployment frequency. How often the organization ships. Self-service and golden paths should raise it, because they lower the cost of each deployment.
- Change-failure rate. The share of changes that cause a failure requiring remediation. Paved roads with sensible defaults should lower it, because the safe path is also the easy path.
- Time to restore. How quickly the organization recovers from a failure. Good platform observability shortens it, though observability itself is a cost center that needs governing, as the analysis of Datadog and Splunk observability spend in 2026 makes clear.
- Developer satisfaction. Surveyed directly. This is the metric that catches the platform that looks good on delivery numbers but is quietly resented, and the one that predicts whether adoption will hold.
The discipline is to baseline these before the platform investment and track them after, attributing change carefully. A platform initiative that does not move lead time, change-failure rate, or developer satisfaction within a few quarters is not earning its staffing. Tying platform spend to these outcomes is the same financial discipline that a FinOps practice brings to cloud cost: the point is to connect the investment to a measurable result rather than to defend it on principle.
A Platform Maturity Model
Organizations rarely arrive at a working platform in one step. The following maturity model describes the progression, and naming the current stage is the first step to advancing.
| Stage | State | Defining characteristic | Primary risk |
|---|---|---|---|
| 0. Ad hoc | Every team does its own thing | No standard workflow exists | Sprawl is invisible and unmeasured |
| 1. Standardized | A common workflow is documented | Teams agree on a paved road | Standard exists but is manual |
| 2. Self-service | The standard workflow is automated | Developers provision without tickets | Guardrails lag behind automation |
| 3. Productized | Platform run as a product | Roadmap driven by developer friction | Platform team becomes a bottleneck |
| 4. Optimized | Platform measured and tuned | Delivery metrics drive investment | Complacency and gradual abstraction creep |
The crucial transition is from stage 0 to stage 1, and it is the one most often skipped. Teams jump to building self-service tooling, stage 2, without first standardizing the workflow, stage 1. The result is automation over inconsistency, which is the portal-over-chaos failure. Standardize first, automate second, productize third, optimize last.
An Adoption Checklist
A platform lives or dies on adoption, and adoption is a deliberate program rather than a launch event. Before declaring a platform capability ready, confirm the following.
- There is a documented paved road for the common case and it genuinely handles the eighty percent without customization.
- There is an explicit, supported escape hatch for teams whose needs fall outside the paved road, so opting out is a feature, not a fight.
- Self-service works end to end without a human in the provisioning loop, inside guardrails that keep results compliant and cost-aware.
- The platform team has named internal customers and a backlog shaped by their friction rather than the team's preferences.
- There is a migration plan, not just a launch, including documentation, support, and a concrete reason for incumbent workflows to move.
- Baseline delivery metrics exist so the platform's impact on lead time, change-failure rate, and developer satisfaction can be measured rather than asserted.
- The underlying workflow was standardized first, so the platform is paving a road rather than papering over sprawl.
A capability that cannot check all seven is not ready for a broad rollout. Shipping it anyway is how platforms accumulate the reputation, fatal and hard to reverse, of being something done to developers rather than for them.
The Staffing Model
The platform-as-a-product framing implies a staffing model that many organizations get wrong. A platform team needs the obvious infrastructure and automation skills, but it also needs people who think like product managers and who have credibility with application developers. A team composed only of deep infrastructure specialists tends to build for its own taste, the second failure mode named above.
The sustainable size is smaller than many fear and the commitment longer than many plan for. A platform does not get built and handed off. It is operated for as long as the organization depends on it, which is the same reason the build-versus-buy decision hinges on staffing. The role of AI tooling is shifting some of this load, and the realistic boundaries of that shift are covered in what actually works for enterprise AI agents in 2026, but it changes the work rather than removing the need for a standing team.
Key Takeaways for Decision-Makers
Platform engineering pays off when it removes work developers should never have had to do, and it backfires when it adds an abstraction they cannot escape. The organizations that succeed standardize the workflow first, make the standard self-service second, run the platform as a product with real internal customers, and measure its impact on delivery metrics rather than on portal logins. The build-versus-buy decision turns on whether the organization will fund the platform as a long-lived product. When the honest answer is no, the disciplined move is to buy or assemble rather than to build a maintenance liability with a login screen.
Frequently Asked Questions
What is an internal developer platform?
An internal developer platform is the self-service layer that lets developers provision infrastructure, deploy services, and follow supported workflows without depending on another team for each step. The goal is to remove undifferentiated work and reduce cognitive load. It succeeds when it makes the right way the easy way and fails when it adds an abstraction developers cannot bypass.
Should we build on Backstage or buy a managed platform?
The decision turns on staffing rather than features. A self-built portal is a long-lived product that needs a standing team to operate and extend. Building fits large organizations where the platform is a genuine competitive lever and a permanent team is funded. Most organizations under a few hundred engineers get most of the value with far less risk by assembling managed components or adopting a managed platform.
How do you measure whether a platform is working?
Use established delivery metrics: lead time for changes, deployment frequency, change-failure rate, time to restore, and surveyed developer satisfaction. Baseline them before the investment and track them after. A platform that does not move these within a few quarters is not earning its staffing, no matter how polished the portal appears.
Why do so many platform initiatives fail?
The most common failure is building self-service tooling before standardizing the underlying workflow, which produces a portal over chaos that documents sprawl instead of removing it. Other frequent failures are mandatory abstractions with no escape hatch, platform teams that build for their own taste, and tooling shipped without an adoption and migration plan.
What is a golden path versus a paved road?
Both name the supported, well-lit way to do a common task. The paved-road framing is more useful because it makes the escape hatch explicit: the supported way is fast and safe for ordinary work, and teams can still step off it when their need is genuinely different. A golden path that becomes the only path turns into a cage and drives adoption away.
Related Articles

Legacy System Modernization: Strategies That Do Not Blow Up
A leader's guide to legacy modernization: the real triggers, the strategy ladder with honest costs, the strangler-fig default, and what AI changes.

Sovereign Cloud: The Compliance Product Hyperscalers Love to Sell
Sovereign cloud is a pricing tier more than a technology. What the offerings deliver versus imply, who needs which layer, and when the premium is worth paying.

Disaster Recovery Planning: What Technology Leaders Actually Need
Disaster recovery for technology leaders: RTO and RPO tiering, the four DR architecture patterns with honest cost multiples, testing, and cloud-era failures.