Kubernetes Cost Optimization in 2026: Where Cloud-Native Spend Actually Goes

Key Takeaways
- Kubernetes promised efficiency and delivered a new category of waste. The dominant driver is the gap between requested capacity and used capacity. Industry FinOps surveys in early 2026 put cluster utilization at many organizations below 40 percent, which means more than half of the compute being paid for is idle reserved headroom.
- The spend lands in five places: the request-versus-usage gap on compute, cross-zone and egress networking, persistent storage and snapshots, observability and other per-node add-ons, and control-plane sprawl from too many small clusters. Most teams only see the first one.
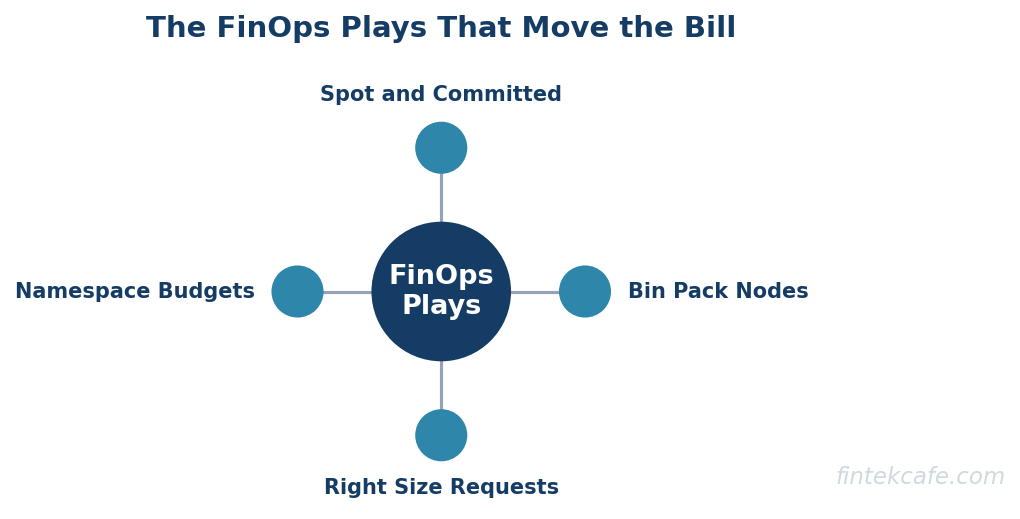
- The FinOps plays that actually move the bill are right-sizing requests and limits from real usage, bin-packing workloads onto fewer nodes, shifting eligible capacity to spot and committed-use discounts, and enforcing namespace budgets with showback so teams see what they spend.
- The tooling landscape splits into open-source cost allocation (OpenCost, the CNCF standard), the commercial layer built on top of it (Kubecost and cloud-native cost tools), and the cloud providers' own billing views. Allocation visibility comes first. Optimization is impossible without it.
- The optimization sequence matters as much as the tactics. Measure and allocate first, right-size second, bin-pack third, then apply commitment and spot discounts last, because discounting waste just locks in the waste at a lower rate.
Kubernetes Promised Efficiency and Delivered a New Kind of Waste
Kubernetes was sold as an efficiency engine. Pack more workloads onto less hardware, scale automatically, stop paying for idle virtual machines. The pitch was sound. The outcome, for a large share of organizations, was the opposite: a new and harder-to-see category of cloud waste that the old cost tools could not even measure.
The reason is structural. In the pre-Kubernetes world, a virtual machine cost what it cost, and you could see it on the bill. In the Kubernetes world, the bill shows nodes, but the spend is driven by pods, requests, and limits, and the mapping between what you are billed for and what your teams actually consume is buried under layers of scheduling abstraction. The cloud provider bills you for nodes. Your engineers think in pods. Nobody owns the gap in between, and the gap is where the money leaks.
The numbers are stark. FinOps surveys through 2025 and into 2026 repeatedly find average cluster CPU utilization well under 40 percent, with memory utilization often lower still. That means an organization running a fleet of clusters is frequently paying for more than twice the compute it uses. The waste is not malicious or even careless. It is the natural result of engineers setting generous resource requests to avoid getting paged, autoscalers provisioning for peaks that rarely arrive, and nobody having a clear, attributable view of the cost.
This article maps where the spend actually goes, names the FinOps plays that move the bill, surveys the tooling that makes the spend visible, and lays out the sequence to attack it in. The framing throughout treats Kubernetes cost not as an engineering hygiene problem but as a cloud cost discipline that happens to live inside a particularly opaque abstraction.
The Anatomy of a Kubernetes Bill
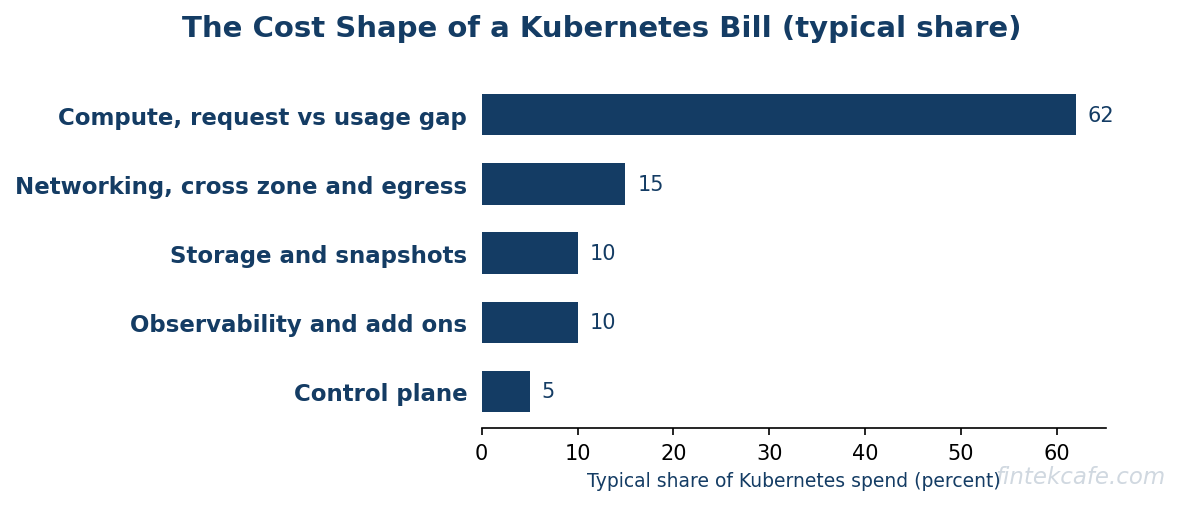
To fix the bill you have to decompose it. Kubernetes spend lands in five distinct buckets, and most teams only have visibility into the first.
The Request-Versus-Usage Gap
This is the big one. In Kubernetes, every container declares a resource request, the amount of CPU and memory the scheduler reserves for it, and optionally a limit, the ceiling it cannot exceed. The scheduler bills your nodes against requests, not usage. A pod that requests four cores and uses one core still consumes four cores of schedulable capacity. The other three are paid-for and idle.
Multiply that across hundreds of services set by dozens of teams who all padded their requests for safety, and you get the sub-40-percent utilization that defines the category. The request-versus-usage gap is typically the single largest line of waste in any Kubernetes estate, and it is invisible on the cloud provider's bill, which only shows nodes.
Networking: Cross-Zone and Egress
The second bucket is data transfer, and it is the one that ambushes finance teams. Traffic between availability zones is billed in both directions. A microservices architecture that chats constantly across zones for high availability can generate a networking bill that rivals compute. Add egress to the internet and to other cloud services, and data transfer becomes a major and poorly understood cost. The architecture decisions that drive it, chatty service meshes, cross-zone replication, are made by engineers who never see the transfer line on the invoice.
Storage and Snapshots
Persistent volumes, the block storage attached to stateful workloads, accumulate quietly. So do the automated snapshots taken for backup. Storage rarely gets cleaned up when a workload is decommissioned, and orphaned volumes and stale snapshots are a classic source of slow, compounding waste. Storage is rarely the biggest bucket, but it is the one that grows unattended.
Observability and Per-Node Add-Ons
Every node in a cluster typically runs a set of agents: a logging collector, a metrics agent, a security scanner, a service mesh sidecar. Each is metered, often per node or per data volume, and each scales with the cluster. The observability add-ons in particular have become a cost category of their own, large enough that they deserve separate treatment, which is exactly what the analysis of the observability cost explosion provides. On a Kubernetes estate, observability cost is partly a Kubernetes cost, because the cluster's dynamism is what multiplies the metered units.
Control-Plane Sprawl
Every cluster has a control plane, and on managed Kubernetes the provider charges a flat fee per cluster on top of the nodes. Organizations that spin up a separate cluster per team, per environment, and per region accumulate dozens of control planes, each with its own fee, its own idle system overhead, and its own minimum node footprint. Cluster sprawl is the quiet tax of decentralized Kubernetes adoption.
The Cost-Shape Breakdown
Putting the buckets together, a representative cloud-native estate tends to distribute its waste along these lines. The exact split varies, but the shape is consistent across organizations.
| Cost bucket | Typical share of spend | Where the waste hides |
|---|---|---|
| Compute (request vs usage gap) | 55 to 70 percent | Over-provisioned requests, idle reserved capacity, peak-sized autoscaling |
| Networking (cross-zone, egress) | 10 to 20 percent | Chatty cross-zone traffic, internet egress, cross-service data transfer |
| Storage and snapshots | 5 to 15 percent | Orphaned volumes, stale snapshots, over-provisioned tiers |
| Observability and add-ons | 5 to 15 percent | Per-node agents, high-cardinality metrics, sidecar overhead |
| Control plane | 2 to 8 percent | One cluster per team or environment, idle system overhead |
The table makes the priority obvious. Compute dominates, so compute is where the first and largest savings live. But the smaller buckets matter because they are often the ones with no owner at all, and unowned cost grows fastest.
The FinOps Plays That Move the Needle
Knowing where the spend goes is half the work. The other half is the set of plays that reduce it, in the order of impact.
Right-Size Requests and Limits From Real Usage
The highest-return play is setting resource requests to match actual usage plus a sensible safety margin, rather than the padded guesses engineers default to. This is not a one-time exercise. It requires observing real consumption over a representative window, including peaks, and then tuning requests down to fit. Done across an estate, right-sizing alone routinely recovers a large fraction of the request-versus-usage gap, which is the largest bucket of waste.
The tooling now automates much of this. Vertical autoscalers and cost platforms recommend right-sized requests from historical usage, and some apply them automatically. The discipline is to act on the recommendations rather than letting them accumulate in a dashboard no one reads.
Bin-Pack Workloads Onto Fewer Nodes
Once requests are right-sized, the next play is bin-packing: scheduling the right-sized pods densely so fewer, more fully utilized nodes carry the load. This is where the recovered headroom from right-sizing turns into an actual smaller bill, because you only save money when you can scale down the node count. Cluster autoscalers, consolidation tools, and node-management systems that actively re-pack workloads onto fewer nodes are the mechanism. Right-sizing without bin-packing is recommendation without realization.
Shift Eligible Capacity to Spot and Committed-Use Discounts
With the cluster right-sized and packed, the remaining steady-state compute is a candidate for committed-use discounts, where you commit to a baseline for one or three years in exchange for a substantial rate cut. Fault-tolerant and batch workloads are candidates for spot capacity, the deeply discounted interruptible instances that can cut compute rates dramatically for the right workloads. The crucial ordering point is that this play comes last, because applying a discount to over-provisioned capacity just locks in the waste at a lower unit price.
Enforce Namespace Budgets and Showback
The structural play that makes the others stick is attribution. Allocate cost by namespace, team, and workload, and show each team what it spends. This is showback: making cost visible to the people who create it. Where the culture supports it, chargeback goes further and bills the cost back to team budgets. Without attribution, optimization is a central team fighting an endless battle against teams who have no reason to care. With it, the teams that create the cost own the cost, which is the only model that scales. This is the same FinOps operating principle covered in the broader guide to FinOps for finance and technology leaders.
The Tooling Landscape
The tools sort into three layers, and the order in which an organization adopts them mirrors the optimization sequence: see the cost first, then act on it.
OpenCost is the open-source, CNCF-backed standard for Kubernetes cost allocation. It maps cloud billing data onto Kubernetes objects, namespaces, deployments, pods, so you can finally answer what each team and workload costs. It is the foundation layer, and much of the commercial tooling is built on or compatible with it.
Kubecost and the commercial cost platforms build on the allocation foundation with richer reporting, automated right-sizing recommendations, savings estimates, alerting, and governance workflows. Kubecost is the best-known, built on OpenCost. The cloud providers also offer their own cost-management views, though these tend to be node-centric and weaker at the pod-level allocation that Kubernetes cost work requires.
The cloud providers' native billing and optimization tools sit underneath everything, providing the raw billing data, committed-use and spot purchasing, and provider-specific recommendations. They are necessary but not sufficient: they see nodes, not pods, which is precisely the visibility gap that the Kubernetes-native layer exists to close.
The sequencing lesson is that visibility is the prerequisite. An organization cannot right-size what it cannot measure, cannot bin-pack what it cannot attribute, and cannot judge a committed-use purchase without knowing its true steady-state baseline. Allocation tooling comes first, always.
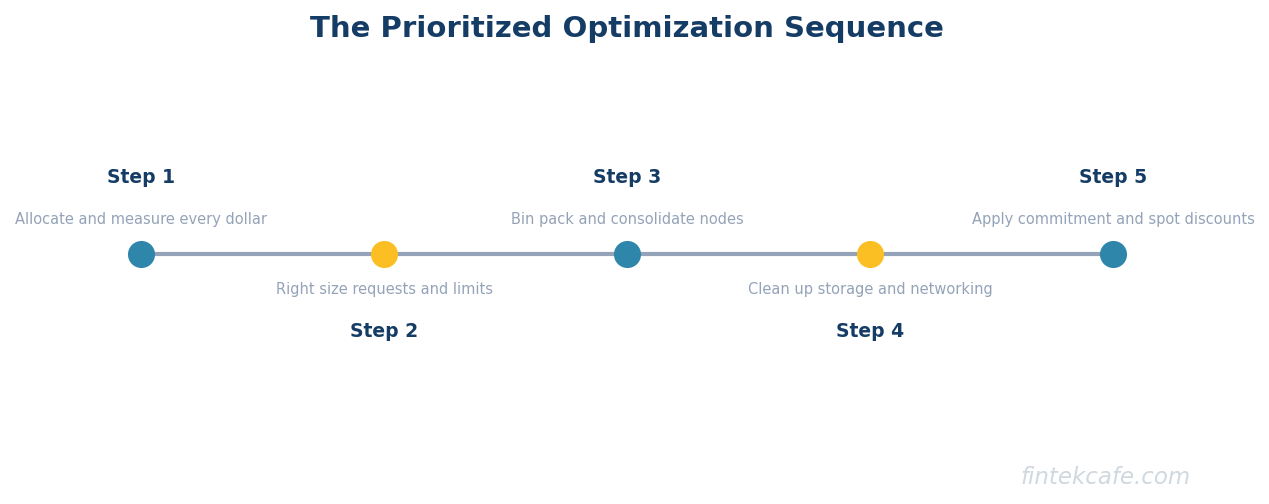
The Prioritized Optimization Sequence
The tactics only work in the right order. Run them out of sequence and you waste effort or lock in the very waste you are trying to remove.
- Allocate and measure. Deploy cost allocation (OpenCost or a platform built on it) so every dollar maps to a namespace, team, and workload. Establish the baseline. Nothing else is reliable without this.
- Right-size requests and limits. Tune resource requests to real usage plus margin across the estate. This recovers the largest bucket of waste, the request-versus-usage gap.
- Bin-pack and consolidate. Schedule the right-sized workloads densely and scale down the node count so the recovered headroom becomes a smaller bill. Address cluster sprawl here too by consolidating under-used clusters.
- Clean up the smaller buckets. Reclaim orphaned storage and stale snapshots, attack cross-zone networking by co-locating chatty services, and review per-node observability agents for cardinality and coverage.
- Apply commitment and spot discounts. Only now, with a clean and accurately sized baseline, commit to discounted capacity for steady-state load and move fault-tolerant workloads to spot. Discounting comes last so you discount real demand, not waste.
- Make it durable with budgets and showback. Set namespace budgets, alert on overruns, and show teams their spend so the optimization holds instead of eroding back to the padded defaults within two quarters.
The first principle running through the whole sequence is that Kubernetes cost is a visibility problem before it is an engineering problem. The same lesson holds across cloud spend generally, as the foundational guide to cloud computing for business leaders lays out, and it holds with particular force here because Kubernetes is the most abstracted, and therefore the most opaque, layer of the modern stack. Make the spend visible, attribute it to the teams that create it, and the optimization follows. Skip the visibility step and you are optimizing in the dark.
FAQ
Why is Kubernetes so expensive compared to plain virtual machines?
Kubernetes itself is not inherently more expensive. The cost comes from low utilization. Engineers set generous resource requests that reserve capacity they do not use, autoscalers provision for rare peaks, and the abstraction hides the gap between what is reserved and what is consumed. Many estates run below 40 percent utilization, so they pay for more than twice the compute they use. The fix is right-sizing and bin-packing, not abandoning Kubernetes.
What is the difference between a resource request and a limit in Kubernetes?
A request is the amount of CPU or memory the scheduler reserves for a container and bills node capacity against. A limit is the ceiling the container cannot exceed at runtime. The request drives cost, because a pod requesting four cores consumes four cores of schedulable capacity even if it uses one. Over-set requests are the largest source of Kubernetes waste, which is why right-sizing requests to real usage is the highest-return optimization.
What is OpenCost and how does it relate to Kubecost?
OpenCost is the open-source, CNCF-backed standard for Kubernetes cost allocation. It maps cloud billing data onto Kubernetes objects so you can see what each namespace, team, and workload costs. Kubecost is the commercial platform built on OpenCost, adding richer reporting, automated right-sizing recommendations, alerting, and governance. Start with allocation visibility, because optimization is impossible without knowing where the spend goes.
Should we use spot instances to cut Kubernetes costs?
Spot capacity can cut compute rates dramatically, but only for fault-tolerant and batch workloads that tolerate interruption, and only after you have right-sized and bin-packed. Applying spot or committed-use discounts to over-provisioned capacity just locks in the waste at a lower rate. The correct order is allocate, right-size, bin-pack, then discount the clean steady-state baseline. Discounting comes last.
How do we stop Kubernetes costs from creeping back up after we optimize?
Durability comes from attribution and governance, not one-time cleanups. Set namespace budgets, alert on overruns, and use showback so each team sees what it spends. Without this, requests drift back to padded defaults within a couple of quarters as new services launch and engineers over-provision for safety. The teams that create the cost have to own the cost, which is the core FinOps operating model.
Related reading on FinTekCafe
- What Is FinOps? A Guide for Finance and Technology Leaders
- The Observability Cost Explosion: Datadog and Splunk in 2026
- The Cloud Cost Crisis: Why Your AWS Bill Is a Strategy Problem
- Cloud Computing Explained: What Every Business Leader Needs to Know
- The Real Cost of AI Infrastructure
- Microservices vs Monoliths: What Executives Need to Know
- DevOps Explained: How Modern Companies Build and Ship Software
Related Articles

Legacy System Modernization: Strategies That Do Not Blow Up
A leader's guide to legacy modernization: the real triggers, the strategy ladder with honest costs, the strangler-fig default, and what AI changes.

Sovereign Cloud: The Compliance Product Hyperscalers Love to Sell
Sovereign cloud is a pricing tier more than a technology. What the offerings deliver versus imply, who needs which layer, and when the premium is worth paying.

Disaster Recovery Planning: What Technology Leaders Actually Need
Disaster recovery for technology leaders: RTO and RPO tiering, the four DR architecture patterns with honest cost multiples, testing, and cloud-era failures.