What Is a Service Catalog? The Platform Engineering Foundation Most Enterprises Skip

Key Takeaways
- A service catalog is a structured inventory of every service, owner, dependency, and quality signal in the engineering estate. It is the primitive on which every other platform engineering capability stands.
- Most internal developer platforms stall because the organization invests in golden paths, portals, and scorecards before knowing what services exist. Without the catalog, the rest is theater.
- Backstage, Cortex, OpsLevel, and Port have converged on the same data model. The decision between them is mostly about build versus buy, federation, and how aggressive the scorecard practice will be.
- Catalog drift, owner abandonment, and score gaming are the predictable failure modes. Treating the catalog as a system of record (not a wiki) and tying ownership to performance reviews are the only reliable mitigations.
- A credible ninety-day rollout produces a catalog that is incomplete but trusted. Trusted incompleteness beats comprehensive fiction every time.
The Quiet Reason Platform Engineering Stalls
Walk into any large engineering organization and ask three questions. How many production services do we run? Who owns each one? Which of them are critical to revenue? A surprising number of CTOs will not have a single source of truth that answers all three. Most have several partial sources that disagree.
That gap is the quiet reason most platform engineering investments underperform. Organizations buy or build an internal developer platform, design beautiful golden paths, and announce a developer experience initiative. Six months in, the dashboard shows adoption numbers, but the underlying inventory is still managed in a spreadsheet, a wiki, a half-finished Backstage instance, and a Slack channel. Every cross-cutting program (security, cost, reliability, AI readiness) has to rebuild its own inventory from scratch.
The service catalog is the unglamorous primitive that makes every cross-cutting program possible. Skipping it is the architectural equivalent of building a city without addresses.
This piece argues a specific thesis. The catalog is not a feature of the platform. It is the precondition. The teams that treat it that way produce platforms that compound. The teams that treat it as a nice-to-have spend years cycling through platform tools without ever generating leverage.
What a Service Catalog Actually Is
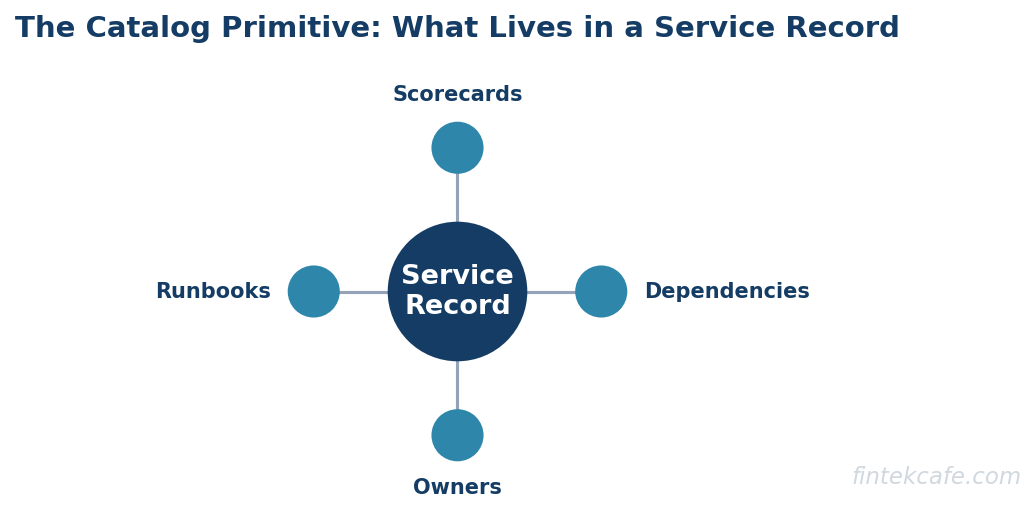
A service catalog is a queryable, governed inventory of the operational units in an organization. The word "service" is shorthand. The catalog typically includes services, libraries, websites, data products, machine learning models, and any other unit that needs an owner.
A useful catalog answers six questions for any entry.
What is it? The name, type, description, and a link to the source of truth (usually a Git repository).
Who owns it? Both a primary team and an accountable individual, with paging information that resolves to a real person on call.
What does it depend on? Upstream services it calls, downstream services it serves, data sources it reads, and infrastructure it runs on.
What is its operational state? SLOs, error budgets, security posture, vulnerability status, deployment cadence, and whether it is in production, staging, or sunset.
What is its business context? The product, line of business, and revenue or risk attribution.
What is its quality signal? Scorecards that measure how well the service meets the organization's standards for reliability, security, documentation, and cost.
Different tools surface these answers differently, but the underlying data model has converged. A mature catalog is essentially a graph database with strong opinions about ownership and quality.
Why the Catalog Comes First
The reason the catalog must come before the rest of the platform is mechanical. Every higher-order capability assumes the catalog exists.
Golden paths assume a service identity to attach templates and policies to. Without that identity, a golden path is just a starter repository.
Scorecards assume a list of services to score and an owner to hold accountable. Without a catalog, scorecards either run against random GitHub repositories or against nothing at all.
Cost attribution assumes services map to teams and to lines of business. Cloud cost tools generate per-resource bills. The catalog is the join key that turns a per-resource bill into a per-team or per-product cost.
Security posture management assumes a known inventory to assess. Vulnerability scanners can find every container image. They cannot tell which image is the production payments service and which is a forgotten side project unless the catalog says so.
Incident management assumes a clear ownership graph. Pagers fire against services. Bridges escalate through ownership chains. Postmortems track action items per service. None of this works without an authoritative catalog.
AI readiness is the newest entrant on the list. Internal AI agents need to know what systems they can act on, who owns them, and what the impact of an action would be. Without a catalog, every AI initiative reinvents service discovery from scratch.
The pattern is the same across every capability. The catalog is the place where ownership, dependencies, and business meaning live. Everything else is a consumer.
The Vendor Landscape: Backstage, Cortex, OpsLevel, Port
Four tools dominate enterprise consideration in 2026. They differ less than the marketing suggests, and more than the feature checklists suggest.
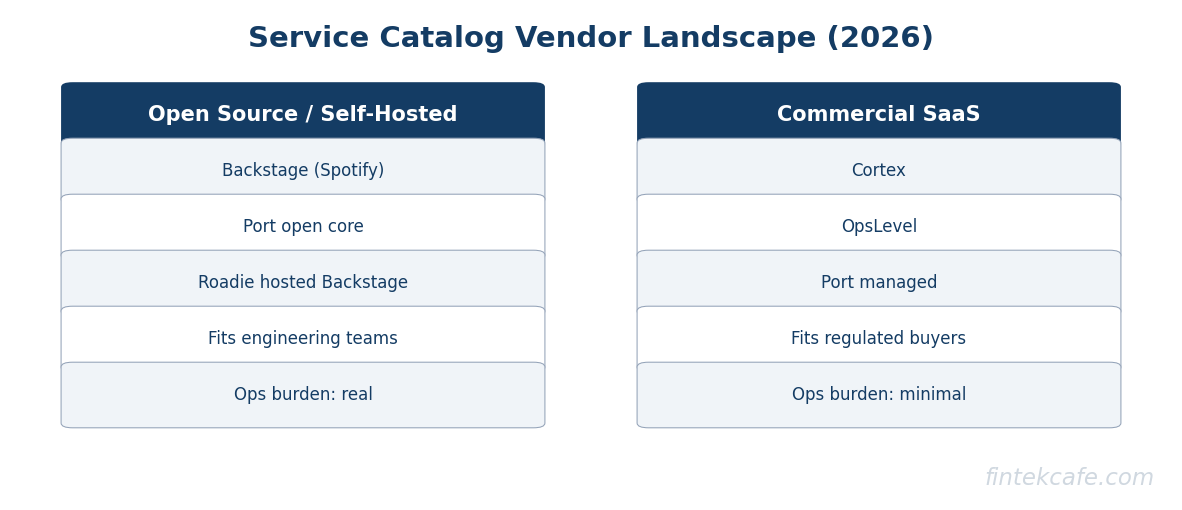
Backstage is the open source developer portal originally built at Spotify and now stewarded by the Cloud Native Computing Foundation. It is a framework for building an internal developer portal, with the catalog as one of its core plugins. The strength of Backstage is its plugin ecosystem and the fact that the organization owns the deployment. The weakness is that "owning the deployment" is a euphemism for staffing a small platform team to keep the portal running, integrated, and current. Most successful Backstage deployments have at least two dedicated engineers behind them. Many enterprises that adopt Backstage end up paying for a commercial distribution (Spotify Portal, Roadie, Backstage on Red Hat OpenShift) to get back the operational support.
Cortex is a commercial service catalog that emphasizes scorecards, initiatives, and quality engineering. Its bet is that the catalog is most valuable when it actively drives engineering behavior, not when it merely describes the estate. Cortex tends to be the choice of engineering organizations that already know what good looks like and want to measure how close they are.
OpsLevel sits in the same commercial neighborhood as Cortex. It emphasizes maturity rubrics, checks, and campaigns. The product experience leans toward engineering leadership use cases (rolling out a security standard, retiring a deprecated framework) rather than developer self-service.
Port is the newest of the four and the one that has gained the most traction in the last two years. Its core insight is that the catalog should be a flexible graph that the organization defines for itself, not a fixed schema imposed by the vendor. Port lets the platform team model whatever entities it cares about (services, environments, regions, data products, AI models) with whatever relationships matter. The trade-off is that more modeling work falls on the platform team.
A defensible decision rule looks like this. Pick Backstage when the organization has a strong platform team that wants full control and is willing to invest in plugin development. Pick Cortex or OpsLevel when scorecards and standards rollout are the most important use cases and time-to-value matters more than customization. Pick Port when the organization needs a flexible graph that goes beyond services (data products, ML models, AI agents) and has the platform engineering capacity to model the schema thoughtfully.
The wrong reasons to pick are equally clear. Do not pick Backstage because it is free. The total cost of operation is rarely lower than the commercial alternatives once the platform team time is counted. Do not pick a commercial tool because the demo is shiny. The demo is the easy part. The hard part is keeping the catalog accurate for three years.
The Buy-versus-Build Decision
A surprising number of organizations still consider building a service catalog from scratch. The argument is usually that the commercial tools do not match the organization's data model or that internal integrations are unique. Both points are usually wrong.
The data model has converged. Services, teams, environments, dependencies, scorecards. Every internal catalog ends up looking like this within two years. The custom data model is almost always a sign that the organization has not yet learned what it actually needs.
The internal integrations are not unique. Every catalog needs to ingest GitHub or GitLab, an identity provider, Kubernetes or another runtime, a cost tool, a CI system, and an observability stack. The commercial tools have already built these integrations. The internal version has not.
A decision tree that has held up well is this.
Build internally only when: the organization has more than two thousand services, has at least five platform engineers already, has strong opinions about the schema that no commercial tool supports, and treats the catalog as a strategic differentiator. This applies to a small number of very large organizations.
Adopt Backstage when: the organization wants control of the platform, is comfortable maintaining open source, and has a platform team of at least three engineers willing to invest in plugins.
Buy a commercial catalog when: time-to-value matters, the platform team is small, or scorecards and standards rollout are the central use case. This is the right answer for the vast majority of organizations and is rarely chosen when the platform team has emotional attachment to building.
The emotional attachment is the variable to watch. Platform engineers like building platforms. The organization needs to use the platform. Aligning those two incentives is a leadership job.
The Failure Modes
A catalog can fail in three predictable ways. Each failure mode is more about culture than tooling.
Catalog drift. The catalog starts complete on day one and decays from there. New services launch without being registered. Old services move owners without updating. Dependencies change. After eighteen months, the catalog reflects an organization that no longer exists. The mitigation is automation: catalog updates must be a side effect of normal engineering work, not a separate manual step. Service creation should require a catalog entry. CI pipelines should fail when a service has no owner. Ownership changes should propagate from the org chart automatically. If the catalog requires human discipline to stay current, it will not stay current.
Owner abandonment. Services are assigned to teams that no longer exist or to individuals who have left. Bridges escalate into the void. Vulnerabilities sit unowned because no one is accountable. The mitigation is enforcing the rule that every catalog entry has a current, on-call owner, and treating an unowned service as a P1 incident. This sounds extreme until the first time an unowned service is the root cause of a major outage.
Score gaming. Once scorecards exist, engineers learn to maximize the score rather than improve the underlying property the score is supposed to measure. A documentation scorecard produces stub README files. A security scorecard produces suppressions. A test coverage scorecard produces tests that test mocks. The mitigation is to score outcomes (mean time to restore, incident count, vulnerability remediation time) rather than activities (documentation present, tests written, dashboard configured). Outcome scorecards are harder to design but harder to game. They also align better with what leadership actually cares about.
The deeper lesson under all three failure modes is the same. A catalog is a social contract, not a technical artifact. The technology decisions matter, but they are easier than the cultural decisions.
The Maturity Ladder
Catalogs evolve through a recognizable progression. Knowing where the organization stands is the first step to knowing what to invest in next.
Level 1: The wiki list. Services are tracked in a Confluence page, a Notion database, or a shared spreadsheet. The list is incomplete and out of date. Useful for new hires, useless for incident response.
Level 2: The portal MVP. The organization stands up Backstage or a commercial alternative, imports the obvious services, and declares a catalog exists. Most fields are empty or stale. Adoption is uneven across the engineering organization.
Level 3: The trusted catalog. Every production service is registered, owned, and tagged. Onboarding new services into the catalog is part of the standard launch process. The catalog is consulted during incidents. Scorecards exist but are descriptive rather than prescriptive.
Level 4: The active catalog. Scorecards drive engineering behavior. Standards rollouts (such as a security framework, a logging library, or a compliance requirement) are tracked as campaigns through the catalog. The catalog is the single answer to questions like "what is my team responsible for" and "how is my team performing."
Level 5: The federated graph. The catalog is one graph among many, with ML models, data products, AI agents, and infrastructure all represented. Cost, compliance, and AI governance tools all consume the same graph. New capabilities can be added without rebuilding the inventory.
Most enterprises today are at Level 1 or Level 2. The gap between Level 2 and Level 3 is where the work is. Getting from a portal MVP to a trusted catalog usually takes six to twelve months of deliberate platform investment.
The Ninety-Day Rollout Checklist
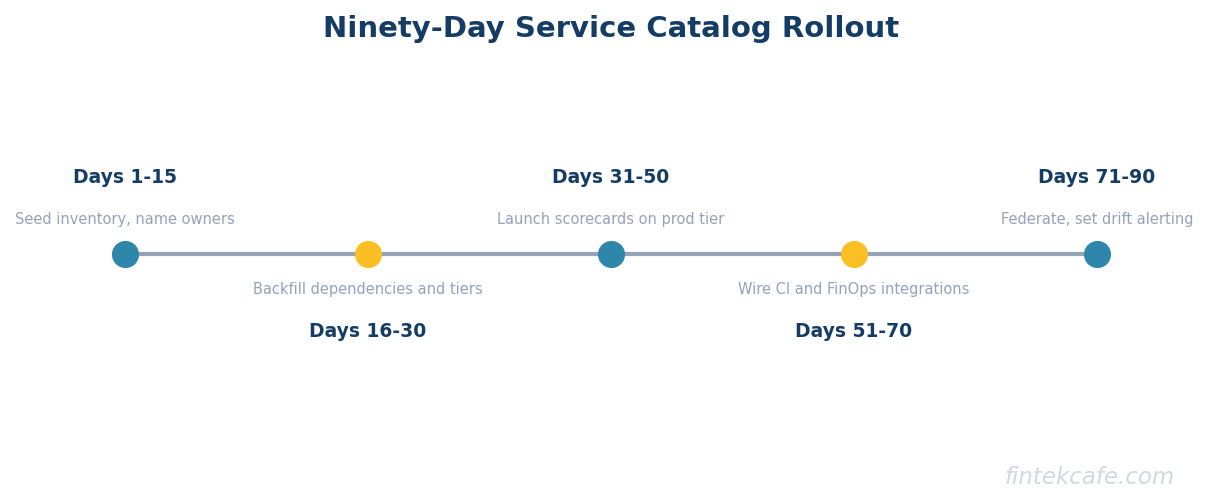
A rollout that produces a trusted, useful catalog within ninety days follows roughly this shape.
Weeks 1 to 2: Decide ownership and tool. Name a single platform team accountable for the catalog. Pick the tool using the criteria above. Do not start the rollout until ownership is unambiguous.
Weeks 3 to 4: Bulk import. Pull service candidates from GitHub or GitLab repositories, Kubernetes namespaces, the cloud account inventory, and any existing partial catalog. Deduplicate. Tag each candidate with confidence. Accept that the first import will be noisy.
Weeks 5 to 6: Assign owners. Match every service to a current team using the org chart. Where the org chart is ambiguous, escalate to engineering leadership for a decision. Where a service has no living owner, mark it as a candidate for sunset and route to the appropriate VP for a decision.
Weeks 7 to 8: Wire ingestion. Connect the source of truth for ownership (HR or identity), the runtime (Kubernetes, cloud accounts), the codebase (Git), and the on-call system (PagerDuty or Opsgenie). The goal is that ownership changes in any source flow into the catalog within hours, not weeks.
Weeks 9 to 10: Define five scorecards. Pick five quality dimensions that matter (such as on-call coverage, security posture, deployment cadence, dependency hygiene, ownership currency). Make them descriptive at first. Avoid the temptation to tie them to performance reviews on day one.
Weeks 11 to 12: Drive one use case end to end. Pick a real cross-cutting initiative (a vulnerability remediation, a logging rollout, a cost reduction) and run it entirely through the catalog. The point is to prove that the catalog is the system of record, not just a portal.
Day 90: Review. The catalog should be trusted by at least three constituencies (engineering leadership, security, and platform). It will not be comprehensive. Trusted incompleteness is a far better starting point than comprehensive fiction.
What Changes for Different Roles
For CTOs, the service catalog is the strategic asset that makes every cross-cutting program tractable. Funding it correctly means treating it as platform investment, not as a tool purchase.
For VPs of engineering, the catalog is the operating system of the engineering organization. It defines what is owned, by whom, to what standard. Operating without one is operating in the dark.
For CISOs, the catalog is the inventory that security tooling has always promised but rarely delivered. Joining vulnerability scanners and posture management to a trusted catalog is the difference between knowing the risk and merely cataloging it.
For CFOs, the catalog is the only credible path to per-service unit economics. Cloud bills become attributable. AI costs become attributable. Engineering productivity investments become measurable.
For engineering managers, the catalog is a tool that answers the question every new manager asks in their first month: what does my team actually run, and how is it doing?
FAQ
Is a service catalog the same as a CMDB? No. A configuration management database is an inventory of infrastructure assets aimed at IT operations. A service catalog is an inventory of operational units aimed at engineering teams and the systems they own. CMDBs typically track machines, network devices, and licenses. Service catalogs track services, ownership, and quality signals. The two can coexist, but they answer different questions.
Backstage versus Cortex: which one is better? The right answer depends on team size and use case. Backstage is the better fit when the platform team has the capacity to maintain an open source portal and wants maximum customization. Cortex is the better fit when scorecards and quality engineering rollouts are the central use case and time-to-value matters more than control. Both can succeed. Both can fail. The tool is a smaller variable than the platform team behind it.
How big does an organization need to be before a service catalog is worth it? The break-even point is usually around fifty production services or one hundred engineers, whichever comes first. Below that, a well-maintained spreadsheet and a clear on-call rotation cover most needs. Above it, the coordination cost of operating without a catalog rises sharply.
What is the most common mistake in adopting a service catalog? Treating the rollout as a tool deployment instead of as a governance change. Buying the tool is the easy part. Establishing the rule that every production service must be in the catalog, every catalog entry must have a current owner, and every cross-cutting program must consume the catalog is the hard part. The organizations that struggle skip that work.
Do scorecards actually change engineering behavior? They do, but only when the metrics measure outcomes that engineers care about and when leadership consistently asks about them. Scorecards that measure activity rather than outcomes get gamed. Scorecards that are published once and never referenced get ignored. Scorecards that drive a weekly review with engineering leadership produce real change within a quarter.
How does the service catalog fit with AI and agent platforms? It is the inventory that AI initiatives have been quietly missing. Internal agents need to know what systems exist, who owns them, what their state is, and what actions are safe. A trusted service catalog feeds that information into the agent platform. Organizations that already have a mature catalog will adopt internal AI agents far faster than those that do not.
Related reading on FinTekCafe
Related Articles

Disaster Recovery Planning: What Technology Leaders Actually Need
Disaster recovery for technology leaders: RTO and RPO tiering, the four DR architecture patterns with honest cost multiples, testing, and cloud-era failures.

The Great SaaS Consolidation: Why Enterprises Are Firing Half Their Vendors
SaaS consolidation is a power transfer to platform vendors, not a cost story. What gets cut, what survives, and how to consolidate without losing leverage.

Technical Due Diligence: How to Evaluate a Company's Technology Before You Buy
What technical due diligence examines, the red flags that kill deals versus reprice them, how AI changes the checklist, and how to scope a rigorous review.