The Enterprise AI Stack: A Reference Architecture for Production AI
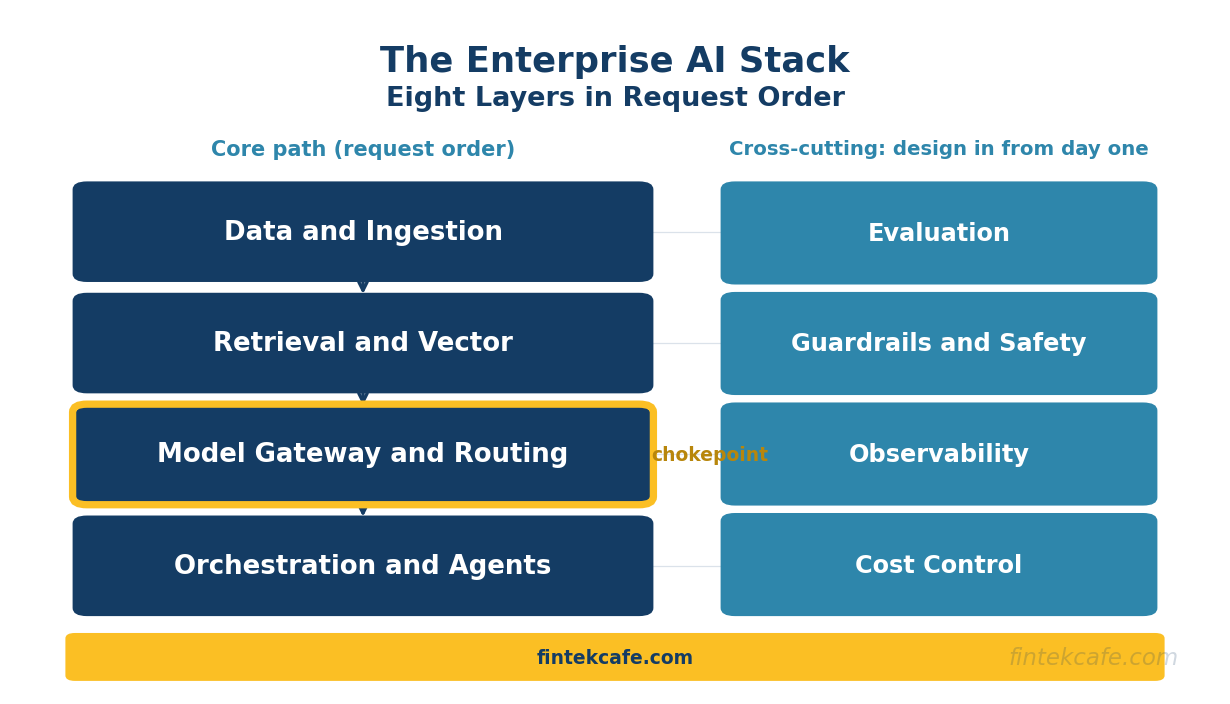
The enterprise AI stack that survives production is eight layers, and they run in the order a request travels through them: a data and ingestion layer that prepares and chunks source content, a retrieval and vector layer that finds the relevant slice of it per query, a model gateway and routing layer that sends each request to the right model under one interface, an orchestration and agent layer that sequences multi-step work and tool calls, an evaluation layer that scores quality before and after every change, a guardrails and safety layer that filters inputs and validates outputs in the request path, an observability layer that traces every call end to end, and a cost-control layer that meters and caps spend at the gateway. Everything below is an expansion of that one paragraph: what each layer does, the named categories of tooling that fill it, and a deterministic rule for choosing at each layer rather than a list of vendors to compare. This reference is current as of the week of June 29, 2026, and it is written to be the thing a team reads before it builds, not after it has already wired together a stack it cannot evaluate.

Key Takeaways
- Production AI is a stack of eight layers, not a model behind an API: data and ingestion, retrieval and vector, model gateway and routing, orchestration and agents, evaluation, guardrails and safety, observability, and cost control. A system missing any of the last four works in the demo and fails in production.
- The single most common architectural mistake is treating the model as the system. The model is one layer. The other seven are where reliability, cost, and safety are actually decided, and they are where the durable engineering work lives.
- Each layer has a deterministic "how to choose" rule that depends on measurable properties of the workload, not on vendor preference. Skip a layer only when the rule says the workload does not need it, never by default.
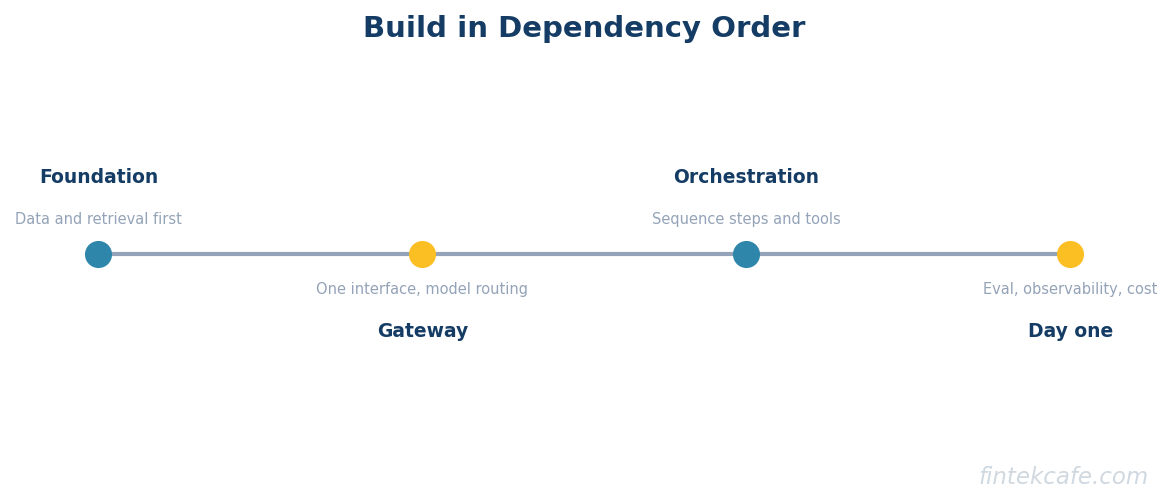
- Build the layers in dependency order but instrument evaluation, observability, and cost control from the first day, because retrofitting them after launch means flying blind through the exact period when failures concentrate.
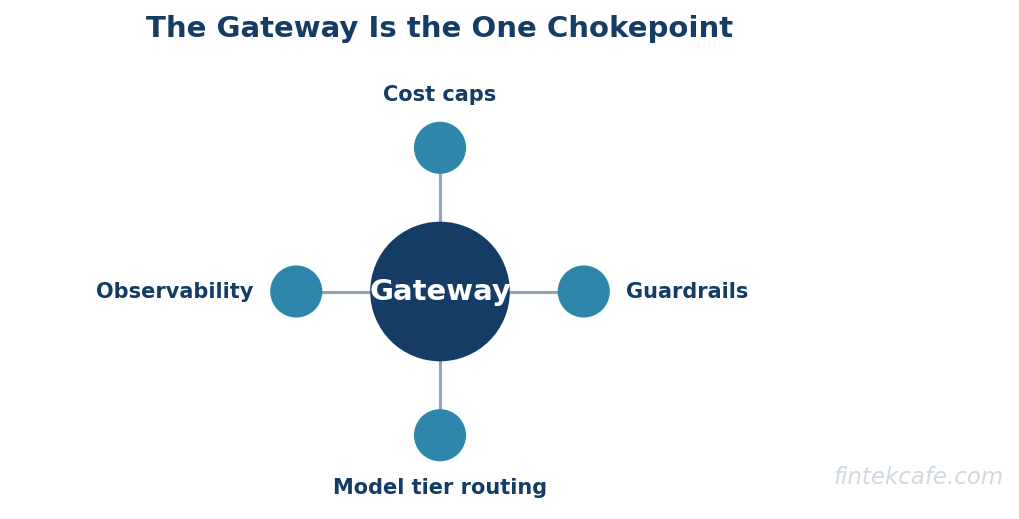
- The gateway is the highest-leverage layer: it is the single chokepoint where routing, guardrails enforcement, cost caps, and observability all attach, which is why a thin internal gateway pays for itself even in a single-model system.
Why the Stack, Not the Model, Is the System
A common failure pattern repeats across organizations shipping their first AI feature. A prototype calls a frontier model directly, the demo is convincing, leadership greenlights production, and the team discovers that the model was the easy ten percent. The hard ninety percent is everything around it: getting the right context to the model, keeping it from answering off-policy, knowing when its quality degrades, attributing its cost, and debugging it when a user reports an answer nobody can reproduce. Those are not model problems. They are stack problems, and the stack is what separates a feature that survives contact with real users from one that quietly accumulates incidents until it is switched off.
The reference below is model-agnostic and vendor-neutral: it names categories of tooling and the decision that selects within each, because specific products turn over faster than the architecture does, and a team that understands the layers can evaluate any product against the job that layer has to do. The layers run in request order, roughly dependency order, but the cross-cutting layers attach to every other layer and must be designed in from the start rather than bolted on.
Layer One: Data and Ingestion
The data and ingestion layer is everything that happens before a query is ever asked: collecting source content from documents, databases, and applications; cleaning and normalizing it; splitting it into chunks of a size the retrieval layer can work with; enriching each chunk with metadata such as source, date, and access permissions; and computing the embeddings that the vector layer will search. The quality ceiling of the entire system is set here, because retrieval cannot surface what ingestion never captured correctly, and a model cannot ground an answer in a chunk that was split through the middle of the relevant sentence.
The categories that fill this layer are document parsers and extractors, chunking strategies, embedding models, and the pipeline orchestration that runs them on a schedule or in response to source changes. The decisions that matter most are chunk size and boundary strategy, the choice of embedding model, and whether ingestion is batch or incremental. Chunking by fixed token count is the naive default and frequently the wrong one, because it severs semantic units; chunking on document structure, by section or paragraph, preserves meaning and measurably improves retrieval.
How to choose: size the chunk to the semantic unit of the source, not to a round token number, and verify the choice by measuring retrieval quality rather than guessing. Use incremental ingestion when source content changes faster than a full reindex can keep up, and batch when it is stable. Pick the embedding model by evaluating retrieval accuracy on your own queries, because public embedding benchmarks rank models on someone else's task and the ranking does not transfer reliably to yours.
| Ingestion decision | Choose this | When |
|---|---|---|
| Chunk boundary | Structure-aware (section, paragraph) | Source has clear structure; default for documents |
| Chunk boundary | Fixed-size with overlap | Source is unstructured free text |
| Refresh mode | Incremental | Content changes faster than a full reindex cycle |
| Refresh mode | Batch reindex | Content is stable or changes in large infrequent batches |
| Embedding model | Smaller, faster model | Retrieval accuracy holds on your eval set; cost and latency matter |
Layer Two: Retrieval and Vector
The retrieval layer answers one question per request: given this query, which slices of the corpus are relevant enough to put in front of the model? It is the layer that makes a model answer from your data rather than from its training, and it is the foundation of retrieval-augmented generation, the pattern that dominates enterprise AI because it grounds answers in current, owned, access-controlled knowledge without retraining the model. The core component is a vector index that finds chunks by semantic similarity, usually combined with keyword search in a hybrid retriever, and increasingly followed by a re-ranking step that reorders the top candidates for precision.
The first decision is whether a dedicated vector database is warranted at all. Many teams reach for one reflexively when a vector extension on the database they already run would serve the workload, and the analysis of vector databases and when you actually need one lays out the threshold: the dedicated system earns its operational cost at high vector counts, high query throughput, and demanding latency targets, and below those thresholds an extension on an existing store is simpler and cheaper. The second decision is retrieval strategy: pure vector search is rarely optimal, and hybrid retrieval that combines semantic and keyword matching, with a re-ranker on top, consistently outperforms vector-only retrieval on enterprise corpora where exact terms and identifiers matter.
How to choose: start with a vector extension on your existing database and graduate to a dedicated vector store only when measured query volume, corpus size, or latency targets exceed what the extension can hold. Use hybrid retrieval by default rather than vector-only, and add a re-ranker when retrieval precision is the bottleneck your evaluation layer identifies. Retrieval is also where the choice between retrieval, long-context loading, and fine-tuning is made, and the framework in the fine-tuning versus RAG versus long-context decision is the deterministic guide: retrieval for changing knowledge, fine-tuning for stable behavior, long context for the working set of a single task.
| Retrieval need | Choose | Threshold or signal |
|---|---|---|
| Vector store | Extension on existing database | Below roughly a few million vectors and modest query throughput |
| Vector store | Dedicated vector database | High vector count, high throughput, or strict latency targets |
| Retrieval strategy | Hybrid (semantic plus keyword) | Default for enterprise corpora with identifiers and exact terms |
| Retrieval strategy | Vector-only | Purely semantic content with no exact-match requirement |
| Precision boost | Add a re-ranker | Evaluation shows relevant chunks retrieved but ranked too low |
Layer Three: Model Gateway and Routing
The model gateway is a thin internal service that every model call passes through, presenting one interface to the application while routing each request to the appropriate model behind it. It is the highest-leverage layer in the stack, because it is the single chokepoint where four other concerns attach: routing logic that sends cheap requests to a small model and hard ones to a frontier model, guardrails enforcement, cost metering and caps, and observability instrumentation. A team that calls model providers directly from application code has no place to put any of these, which is why even a single-model system benefits from a gateway from the start.
Routing is the gateway's distinctive job. Model-tier routing sends each request to the cheapest model that meets the quality bar for that request, reserving the expensive frontier model for the requests that genuinely need it, and it is one of the largest cost levers in the entire stack. The gateway is also the layer that contains provider lock-in: a clean internal interface means switching or adding a provider is a gateway change rather than an application rewrite, though the abstraction carries a lowest-common-denominator tax that has to be managed deliberately. The connective standard for how models reach tools and data, described in the analysis of the Model Context Protocol for enterprises, increasingly anchors how the gateway exposes capabilities to the orchestration layer above it.
How to choose: build a thin gateway even for one model, because the chokepoint is worth more than the abstraction costs. Implement model-tier routing as soon as the workload has a mix of easy and hard requests, which is almost immediately. Keep the gateway interface narrow and resist leaking provider-specific features through it, accepting that the portability it buys is worth a measured constraint on the capabilities it exposes.
| Gateway capability | Implement when | Primary payoff |
|---|---|---|
| Single internal interface | From day one | Provider portability; one place to attach everything else |
| Model-tier routing | Workload mixes easy and hard requests | Largest single cost lever in the stack |
| Provider failover | Availability target exceeds one provider's SLA | Resilience to provider outages |
| Capability exposure | Always, narrowly | Portability; managed lowest-common-denominator tax |
Layer Four: Orchestration and Agents
The orchestration layer sequences the steps of work that a single model call cannot complete: chaining retrieval into generation, calling tools and feeding results back, looping until a condition is met, and coordinating multiple model calls into one outcome. At its simplest it is a fixed chain. At its most complex it is an agent that decides its own next step, calls tools, and iterates. The complexity of this layer should track the complexity of the task and no further, because the failure modes grow faster than the capability does.
This is the layer where teams most often over-engineer, reaching for autonomous multi-step agents on tasks a deterministic chain would handle more reliably and more cheaply. The evidence on production agent systems is sobering, and the catalogue of failure modes is consistent: compounding errors across steps, runaway tool-call loops, and non-determinism that makes incidents impossible to reproduce. The practical guidance is to use the least agentic pattern that solves the task: a fixed chain when the steps are known, a constrained tool-use loop when the model needs to choose among a small set of actions, and full autonomy only when the task genuinely cannot be decomposed in advance.
How to choose: match the orchestration pattern to how much of the workflow is knowable ahead of time. Known steps call for a deterministic chain; a bounded choice among known tools calls for a constrained agent with hard loop limits; open-ended tasks call for full autonomy with aggressive guardrails and cost caps, and only after the simpler patterns have been ruled out by evidence rather than ambition.
| Orchestration pattern | Use when | Main risk to control |
|---|---|---|
| Fixed chain | Steps are known and ordered in advance | Low; prefer this whenever it fits |
| Constrained tool-use loop | Model picks among a small, known set of tools | Runaway loops; enforce hard step limits |
| Autonomous agent | Task cannot be decomposed ahead of time | Compounding errors, cost blowout, non-reproducibility |
Layer Five: Evaluation
The evaluation layer turns AI quality from a feeling into a number that is comparable across every change to a prompt, a model, or a retrieval setting. It is a versioned golden dataset of representative inputs paired with what a good output looks like, a set of scoring functions, and a runner that produces a comparable score on demand. Without it, every change to the system is a coin flip dressed up as engineering, because there is no way to know whether the new version is better than the old one. The full construction of this layer is the subject of the guide to building an LLM evaluation harness that catches real failures, and the central discipline it teaches is that the failures reaching production live on the long tail that manual spot-checking never reaches.
Evaluation is a cross-cutting layer: it scores not just the final answer but the components beneath it, retrieval quality separately from generation, so that when an answer is wrong the team knows which layer failed. The methods stack from cheap and deterministic to expensive and subjective: assertion checks on format and content, reference-based scoring against known-good answers, an LLM acting as a calibrated judge, and human review on a sample. The most dangerous method is the LLM-as-judge used without a human-graded calibration set behind it, because it is confidently wrong in ways that correlate with the biases of the model under test.
How to choose: build the golden dataset before the feature ships, not after, and instrument component-level scoring so retrieval and generation are graded separately. Use deterministic assertions wherever the property is checkable, reference-based scoring where good answers are known, and an LLM judge only as a screen with a calibration set behind it. Wire the harness into continuous integration so a quality regression fails the build instead of reaching users.
Layer Six: Guardrails and Safety
The guardrails layer is the control layer that sits between the user, the model, and your systems, filtering what goes in and validating what comes out. It exists because users will jailbreak a feature, leak sensitive data into it, and trick it into off-policy answers, and a clever prompt is not a safety mechanism. The companion guide to keeping LLM features safe in production with guardrails details the techniques and where each belongs in the request path: input filtering and prompt-injection defense before the model, output validation and grounding checks after it, PII redaction on both sides, and topic and tool-use restrictions throughout.
Guardrails carry a latency and cost tax, because each check is itself work in the request path, and the characteristic failure mode is over-blocking that makes the feature useless by refusing legitimate requests. The layer therefore has to be tuned, not maximized, and the tuning is driven by the evaluation layer measuring both the unsafe outputs that slip through and the safe ones that get wrongly blocked.
How to choose: map each risk the feature actually faces to the specific guardrail technique that addresses it, and implement only those, because a guardrail for a risk the workload does not have is pure latency cost. Place input-side checks before the model and output-side checks after it, budget the latency tax explicitly, and tune the aggressiveness against an evaluation set that measures over-blocking as a first-class failure alongside unsafe output.
| Risk | Guardrail technique | Where in the request path |
|---|---|---|
| Prompt injection or jailbreak | Input filtering and instruction-hierarchy defense | Before the model |
| Sensitive data leakage | PII detection and redaction | Both input and output |
| Off-policy or off-topic answers | Topic restriction and output validation | After the model |
| Ungrounded or fabricated claims | Grounding and citation checks | After the model |
| Unauthorized actions | Tool-use restriction and permission checks | Around tool calls |
Layer Seven: Observability
The observability layer makes every AI request inspectable after the fact: a full trace of what the user asked, what the retrieval layer returned, what context was assembled, what the model received, what it produced, which guardrails fired, and what it cost. Without it, an AI incident is a report of a bad answer with no way to reproduce the inputs that caused it, and the team patches blind. With it, a single feature invocation is a trace and each model and tool call is a span, which is the same distributed-tracing model that mature software systems already use, applied to the AI request path.
AI observability extends ordinary observability with AI-specific signals: token counts and cost per request, retrieval relevance, guardrail activations, and quality scores from the evaluation layer attached to live traffic. It is the layer that closes the loop, because the production traces it captures become the long-tail cases that feed back into the evaluation layer's golden dataset. Building it on the same telemetry pipeline as the rest of the system rather than a separate AI-only tool keeps the operational surface manageable.
How to choose: instrument tracing from the first day rather than retrofitting it, because the period right after launch is when failures concentrate and when traces are most valuable. Capture the full request path as spans, attach AI-specific signals to each, and route the telemetry through the pipeline the rest of the organization already operates rather than standing up a parallel AI-only stack.
Layer Eight: Cost Control
The cost-control layer meters, attributes, and caps AI spend, and it is a distinct layer because AI cost behaves unlike traditional infrastructure cost: it attaches to ephemeral per-request, per-model events rather than to taggable durable resources, which defeats the instance-level tooling that classic cloud cost management relies on. The full treatment of why this breaks and what replaces it is the analysis of why AI workloads break traditional cloud cost control, and its conclusion drives the design of this layer: cost visibility is an application-layer instrumentation problem, attribution must be stamped in the request path, and the governing metric is cost per outcome rather than cost per token.
The layer attaches to the gateway, because the gateway is where every billable model call passes and therefore the only place that can meter and cap spend in real time. Its three working mechanisms are per-feature attribution carried as request metadata into the telemetry, model-tier routing as the primary cost lever, and budget guardrails at the gateway that enforce token, rate, and cost ceilings per feature so a runaway loop or a cost-driven attack is capped in the moment rather than discovered on next month's invoice.
How to choose: stamp every model call with the feature and team it serves, so cost can be attributed per outcome rather than reported as an undifferentiated total. Enforce budget ceilings at the gateway in real time, and treat model-tier routing as the first cost lever to pull, because choosing the cheapest model that clears the quality bar for each request moves the bill more than any negotiation on headline token price.
How to Use This Reference
The eight layers are built in dependency order, data and retrieval first, then the gateway, then orchestration on top, but the three cross-cutting layers must be designed in from the first commit rather than added after launch. All three are instruments, and instruments installed after the failures begin cannot see the failures that already happened. A team that ships the first six layers and promises to add evaluation, observability, and cost control later is choosing to fly blind through precisely the window when AI systems fail most.
The deterministic rule that runs through every layer is the same: implement the layer to the degree the measured properties of the workload require, and skip it only when the workload genuinely does not need it, never by default. A reference architecture is not a shopping list to buy in full; it is a map of the decisions that production AI forces, made on evidence from your own workload rather than on the vendor pitch or the prototype that worked. The teams that treat the stack as the system, rather than the model as the system, are the ones whose AI features are still running a year after launch.
Related Articles
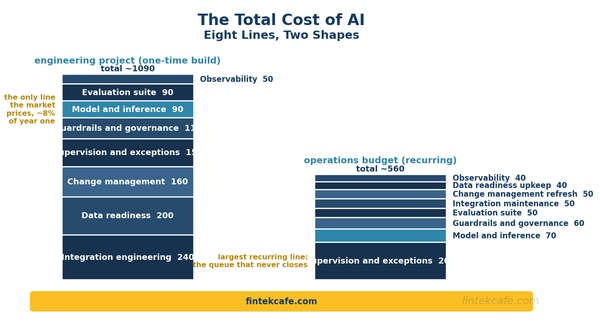
The Total Cost of AI: A Framework for Pricing an AI Initiative End to End
An eight-line total cost of ownership framework for enterprise AI, with a worked example, realistic cost shares, and a build-buy-wait decision table.

AI Governance: How to Build an AI Policy That Actually Gets Followed
Why AI policies fail as documents and work as controls: a three-tier governance model, ownership patterns, EU AI Act duties, and metrics that matter.

Seat Pricing Is Dying: How AI Is Repricing the Software Industry
AI agents break the per-seat model at the root. The pricing ladder replacing it, the failure modes of each rung, and the buyer playbook for the transition.