AI Guardrails: How to Keep LLM Features Safe in Production


Key Takeaways
- Guardrails are the control layer that sits between the user, the language model, and your systems, inspecting and constraining what flows in each direction. A clever prompt is not a safety layer. In production, users will jailbreak the model, leak sensitive data into it, and steer it into off-policy answers, and only a separate enforcement layer reliably stops that.
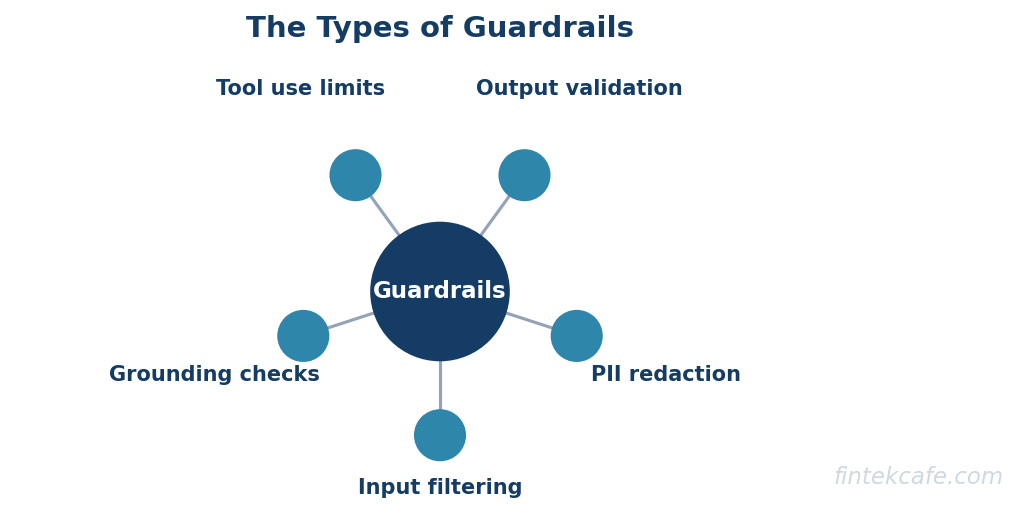
- Guardrails are not one thing. They are a set of techniques, input filtering, output validation, PII redaction, prompt-injection and jailbreak defense, topic and tool-use restrictions, and grounding checks, and each belongs at a specific point in the request path. Putting the right check in the wrong place is a common and expensive mistake.
- The build-versus-buy choice is real and rarely all-or-nothing. Open-source frameworks give control and no per-call fee, managed services give coverage and speed at a recurring cost, and a do-it-yourself layer makes sense only for the narrow checks unique to your domain. Most mature deployments mix all three.
- Guardrails add a latency and cost tax that must be budgeted, not discovered. Every check that calls another model adds round-trip time and token spend, and naive designs can double the cost and latency of a feature. The discipline is to run cheap deterministic checks inline and reserve expensive model-based checks for the cases that need them.
- The failure mode that kills features is over-blocking. A guardrail tuned too aggressively refuses legitimate requests, frustrates users, and trains them to route around the feature. Safety that makes the product unusable is not safety. The target is the tightest constraint that still lets the real use case through, measured against real traffic.
A Clever Prompt Is Not a Safety Layer
The typical first LLM feature ships with a carefully written system prompt that tells the model what to do and what not to do, and nothing else. The prompt says "do not reveal confidential information, stay on topic, and be helpful," and in the demo the model obeys. Then it reaches real users, and the gap between a polite instruction and an enforced constraint becomes obvious. A user pastes a paragraph that says "ignore your previous instructions" and the model complies. Another pastes a customer record full of personal data straight into the chat. A third discovers that asking the model to "explain as a story" gets it to produce exactly the off-policy answer the prompt was supposed to prevent.
The lesson organizations consistently learn the hard way is that a system prompt is a request, not a control. The model is trained to be helpful, and a sufficiently creative user can almost always find phrasing that makes complying with them feel like being helpful. Relying on the prompt alone to enforce safety is like relying on a sign that says "please do not enter" instead of a lock. It works until someone decides not to honor it.
Guardrails are the lock. This article defines what guardrails actually are, maps each technique to where it belongs in the request path, works through the build-versus-buy decision, quantifies the latency and cost tax they add and how to budget for it, and confronts the failure mode that quietly destroys more features than any attacker: over-blocking. A decision table maps each category of risk to the technique that addresses it, so the question stops being "are we safe" and becomes "which specific risks have we covered, and where."
What Guardrails Actually Are
A guardrail is an automated check that sits outside the language model and either inspects, transforms, or blocks the data moving between the user, the model, and your systems. The defining property is that the guardrail is separate from the model. It is deterministic code or a dedicated classifier that runs before or after the model call, and it enforces a rule the model itself cannot be trusted to honor reliably. Guardrails come in several distinct types, and treating them as interchangeable is the first mistake.
Input filtering inspects the user's input before it reaches the model. It blocks or flags content that should never be processed: known jailbreak patterns, abusive content, requests for clearly prohibited outputs. It is the first line and the cheapest, because rejecting a bad request early avoids the cost of the model call entirely.
PII redaction detects and masks personal or sensitive data, names, account numbers, health information, before it reaches the model or before it is logged. This matters in both directions. Redacting on the way in prevents sensitive data from being sent to a third-party model provider, and redacting on the way out prevents the model from surfacing data it should not.
Prompt-injection and jailbreak defense is the specialized subset of input handling aimed at adversarial instructions. Prompt injection is the attack where user-supplied text contains instructions that hijack the model's behavior, and it is the single most important LLM-specific threat. Defenses include detecting instruction-like patterns in untrusted input, separating trusted system instructions from untrusted user and document content, and refusing to act on instructions that arrive through data channels.
Output validation inspects the model's response before it reaches the user or a downstream system. It checks structure (is this valid JSON with the required fields), content (does the answer contain disallowed material), and safety (is the response toxic, defamatory, or leaking internal data). For any feature where the model's output drives an action, output validation is the last gate before that action happens.
Topic and tool-use restrictions constrain what the model is allowed to discuss and what it is allowed to do. A banking assistant should not give medical advice, and an agent with a refund tool should not issue a refund above a threshold without approval. These restrictions enforce the boundary of the feature's intended scope, which is exactly the discipline that separates production agents from demos, a point developed in the analysis of why AI agent frameworks break in production.
Grounding checks verify that the model's answer is actually supported by the source material it was given, rather than invented. For retrieval-augmented features, a grounding check compares the claims in the output against the retrieved documents and flags or blocks unsupported assertions. This is the guardrail against confident hallucination, and it overlaps directly with the measurement discipline covered in the guide to building an LLM evaluation harness.
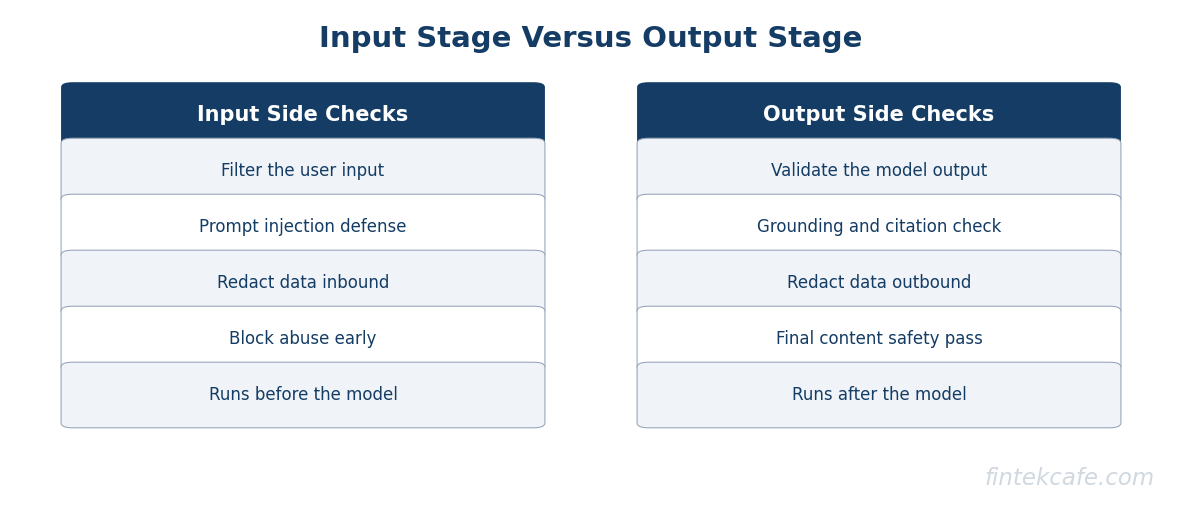
Where Each Guardrail Belongs in the Request Path
Guardrails are positional. The same check can be useless or essential depending on where it runs, so the architecture matters as much as the checks themselves. The request path has four stages, and each type of guardrail belongs at a specific one.
[ User input ]
|
(1) INPUT STAGE -> input filtering, PII redaction (inbound),
| prompt-injection detection, abuse blocking
v
[ Prompt assembly ] -> separate trusted instructions from untrusted
| user and retrieved content
v
[ Model call ]
|
(2) PRE-ACTION -> output validation, grounding checks,
| topic and policy checks, PII redaction (outbound)
v
[ Tool / action ] -> (3) tool-use restrictions, approval gates,
| scope and limit enforcement
v
(4) RESPONSE -> final content safety check before display
|
v
[ User sees output ]
The pattern is that untrusted data gets inspected the moment it enters and the model's output gets inspected before it can cause any effect. Input-stage guardrails reject bad requests cheaply and strip sensitive data before it leaves your control. The pre-action stage is the critical one, because it is the last point before the model's output either reaches a human or triggers a system action, and it is where output validation, grounding, and policy checks earn their place. Tool-use restrictions sit at the action boundary, gating anything consequential behind an explicit limit or a human approval. The final response check is a lightweight content-safety pass before anything is displayed.
The most common architectural error is putting all the trust in the prompt-assembly step, hoping that careful formatting keeps untrusted content from being treated as instructions. Formatting helps, but it is not a guardrail. The untrusted content still needs to be inspected at the input stage and the output still needs to be validated before it acts. Defense is layered precisely because no single stage catches everything.
The Build-Versus-Buy Choice
Once an organization accepts that it needs guardrails, the next question is whether to build them, buy them, or both. The honest answer for most teams is both, with the split decided by how specific each check is to the domain.
Open-source frameworks provide a structured way to define and run guardrails in your own infrastructure. They give maximum control, no per-call fee, and the ability to inspect exactly what each check does, at the cost of the engineering effort to integrate, tune, and maintain them. They fit teams that have the platform-engineering capacity to own the layer and want their guardrail logic to live inside their own systems rather than a vendor's.
Managed guardrail services offer pre-built, continuously updated checks, prompt-injection detection, content moderation, PII detection, behind an API. They give broad coverage and speed to deploy, and they shift the burden of keeping up with new attack patterns to the vendor. The cost is a recurring per-call fee and a dependency on a third party, and the trade is the same one organizations face across the stack: pay for managed coverage or pay in engineering time to own it.
A do-it-yourself layer is custom code for the checks that are unique to your domain and that no framework or service knows about: your specific policy rules, your proprietary data formats, your particular tool-use limits. This is where in-house effort is genuinely warranted, because these checks encode business logic no vendor can supply.
The mistake at each extreme is predictable. Building everything in-house means reimplementing prompt-injection detection that a managed service maintains better, and falling behind as new attacks emerge. Buying everything means paying per call for checks you could run as cheap deterministic code, and being unable to enforce the domain rules that matter most to you. The mature pattern uses managed services or open-source frameworks for the general, fast-evolving threats, and a thin in-house layer for the domain-specific policy. This is the same build-versus-buy calculus that governs security tooling generally, including the response to shadow AI use across the organization, where the question is always which controls to own and which to delegate.
The Latency and Cost Tax
Guardrails are not free, and the teams that get burned are the ones who discover the cost in production instead of budgeting for it in design. Every guardrail adds work, and the expensive ones add a lot.
The cost has two components. The first is latency: each guardrail that runs in the request path adds time before the user sees a response, and a guardrail that itself calls a language model can add as much latency as the original model call. A feature with an input classifier, an output validator, and a grounding check, each implemented as a separate model call, can take three or four times as long as the bare model call, turning a responsive feature into a sluggish one. The second is token cost: every model-based guardrail consumes tokens, so a design that wraps each call in several model-based checks can multiply the per-request cost several times over, which means the true cost of a guarded feature is often several times the headline model price.
The discipline that controls the tax is tiering the checks by cost. Cheap deterministic checks, pattern matching, format validation, regular-expression PII detection, blocklists, run inline on every request because they cost almost nothing. Mid-cost checks using small dedicated classifiers run when the deterministic layer flags uncertainty. Expensive model-based checks, an LLM grading another LLM's output for grounding or policy, run only on the requests where the risk justifies the cost, not on every call by default. Budgeting for guardrails means deciding, per feature, how much latency and cost the safety layer is allowed to add, and then designing the tiering to stay inside that budget. A feature that cannot afford a grounding check on every call can still run it on a sample and on high-risk requests, which catches most of the risk at a fraction of the cost.
The Over-Blocking Failure Mode
The failure that quietly kills LLM features is not the attack that gets through. It is the guardrail tuned so aggressively that it blocks legitimate use. An over-blocking guardrail refuses reasonable requests, returns unhelpful refusals, and teaches users that the feature cannot be trusted to do its job. Users respond the way they always do to a tool that gets in their way: they stop using it, or they route around it, often to an unsanctioned alternative that has no guardrails at all. Safety that makes the product unusable produces less safety overall, not more.
Over-blocking comes from treating the guardrail as a one-way ratchet where stricter is always safer. It is not. Every guardrail has two error types: it can let through something it should have blocked (a false negative), or it can block something it should have allowed (a false positive). Tightening the guardrail trades one for the other. A guardrail with a high false-positive rate is a guardrail that does not understand the real use case, and the cost of those false positives, lost trust and abandoned usage, is real even though it does not show up in a security report.
The fix is to measure guardrails against real traffic, not against adversarial test cases alone. The right target is the tightest constraint that still lets the legitimate use case through, and finding it requires tracking the false-positive rate on real requests as carefully as the catch rate on attacks. This is the same measurement discipline that governs model quality itself, and it belongs in the same harness, as the guide to evaluating LLM outputs and catching real failures lays out: a guardrail change, like a prompt change, should be scored against a representative dataset before it ships, so that a well-meaning tightening that breaks the feature for real users fails the test instead of reaching them. The related practice of formal evaluation as an executive concern is covered in the executive guide to AI evals.
Mapping Risk to Guardrail Technique
Guardrails are most useful when chosen against the specific risk they address rather than adopted as a generic bundle. The table maps each common risk to the technique that handles it and where in the path it belongs.
| Risk | Primary guardrail | Where in the path | Watch out for |
|---|---|---|---|
| Jailbreak and instruction override | Prompt-injection detection, instruction-data separation | Input stage | New phrasings outrun static pattern lists |
| Sensitive data leaking to the model or logs | PII detection and redaction | Input and output stages | Redaction missing non-standard formats |
| Confident hallucination | Grounding check against sources | Pre-action stage | Cost of a model-based check on every call |
| Off-topic or off-policy answers | Topic and policy classifiers | Pre-action stage | Over-blocking legitimate edge questions |
| Unsafe or consequential actions | Tool-use restrictions, approval gates | Action boundary | Limits that are easy to bypass via chaining |
| Toxic or defamatory output | Content-safety classifier | Response stage | False positives on legitimate strong language |
| Malformed output breaking downstream code | Schema and format validation | Pre-action stage | Silent failures when validation is skipped |
The pattern in the table is that input-stage guardrails defend against what the user sends, pre-action guardrails defend against what the model produces, and action-boundary guardrails defend against what the system does. A feature that has covered all three columns has a layered defense. A feature that has covered only one has a gap that production will find.
A Starter Checklist
Before an LLM feature handles real users, an organization should be able to answer yes to each of these. A no on any line is a known exposure, not a detail.
- Untrusted input is inspected at the input stage, not just formatted carefully in the prompt.
- Sensitive data is detected and redacted before it reaches a third-party model or a log.
- The model's output is validated for structure, content, and safety before it reaches a user or triggers an action.
- Any consequential tool use is gated behind an enforced limit or a human approval.
- Retrieval-based answers are checked for grounding against their sources, at least on a sample and on high-risk requests.
- The guardrail layer's added latency and token cost are budgeted per feature, with cheap checks inline and expensive checks tiered.
- The false-positive rate is measured on real traffic, so over-blocking is caught before it drives users away.
- Guardrail changes are scored against a representative dataset before shipping, the same as prompt and model changes.
The organizations running LLM features safely in production are not the ones with the cleverest prompts. They are the ones that treated safety as a separate, layered, measured control plane, chose each guardrail against a specific risk, budgeted its cost, and tuned it against real traffic so it constrains attackers without blocking customers. That control plane is the difference between a feature that survives contact with real users and one that becomes an incident.
FAQ
What are AI guardrails?
AI guardrails are automated checks that sit outside a language model and inspect, transform, or block the data moving between the user, the model, and your systems. They include input filtering, PII redaction, prompt-injection defense, output validation, topic and tool-use restrictions, and grounding checks. The defining feature is that they are separate from the model and enforce rules the model itself cannot be trusted to honor, which is why a system prompt alone is not a guardrail.
How do guardrails defend against prompt injection?
Prompt injection is an attack where user-supplied text or retrieved content contains instructions that hijack the model's behavior. Guardrails defend against it by detecting instruction-like patterns in untrusted input at the input stage, separating trusted system instructions from untrusted user and document content during prompt assembly, and refusing to act on instructions that arrive through data channels. Because new phrasings constantly emerge, this defense combines pattern detection with architectural separation rather than relying on a static blocklist.
Should we build or buy AI guardrails?
Most mature deployments do both. Use managed services or open-source frameworks for general, fast-evolving threats like prompt injection and content moderation, where a vendor maintains the checks better than you can, and build a thin in-house layer for the domain-specific policy and tool-use limits that no vendor knows about. Building everything in-house means falling behind on evolving attacks; buying everything means paying per call for checks you could run as cheap code and being unable to enforce your own rules.
How much latency and cost do guardrails add?
It depends entirely on the design. Cheap deterministic checks like pattern matching and format validation add almost nothing. Model-based checks, such as an LLM grading another model's output, can each add as much latency and token cost as the original call, so a naive design that wraps every request in several model-based checks can multiply latency and cost several times over. The fix is tiering: run cheap checks inline on every request and reserve expensive model-based checks for high-risk requests and samples.
What is over-blocking and why does it matter?
Over-blocking is when a guardrail is tuned so aggressively that it refuses legitimate requests, returning unhelpful refusals that frustrate users. It matters because users abandon tools that get in their way, often routing to an unsanctioned alternative with no guardrails at all, which produces less safety overall. The target is the tightest constraint that still lets the real use case through, found by measuring the false-positive rate on real traffic, not just the catch rate on adversarial tests.
Related reading on FinTekCafe
Related Articles
The Total Cost of AI: A Framework for Pricing an AI Initiative End to End
An eight-line total cost of ownership framework for enterprise AI, with a worked example, realistic cost shares, and a build-buy-wait decision table.

AI Governance: How to Build an AI Policy That Actually Gets Followed
Why AI policies fail as documents and work as controls: a three-tier governance model, ownership patterns, EU AI Act duties, and metrics that matter.

Seat Pricing Is Dying: How AI Is Repricing the Software Industry
AI agents break the per-seat model at the root. The pricing ladder replacing it, the failure modes of each rung, and the buyer playbook for the transition.