Data Lakehouse vs Data Warehouse: Choosing the Right Analytics Foundation

Key Takeaways
- The lakehouse-versus-warehouse debate is mostly vendor positioning layered on top of a genuine architecture decision. The real questions are who needs to query the data, how structured it is, how strict the governance must be, and whether avoiding engine lock-in is worth added operational complexity. Strip away the marketing and those four questions decide it.
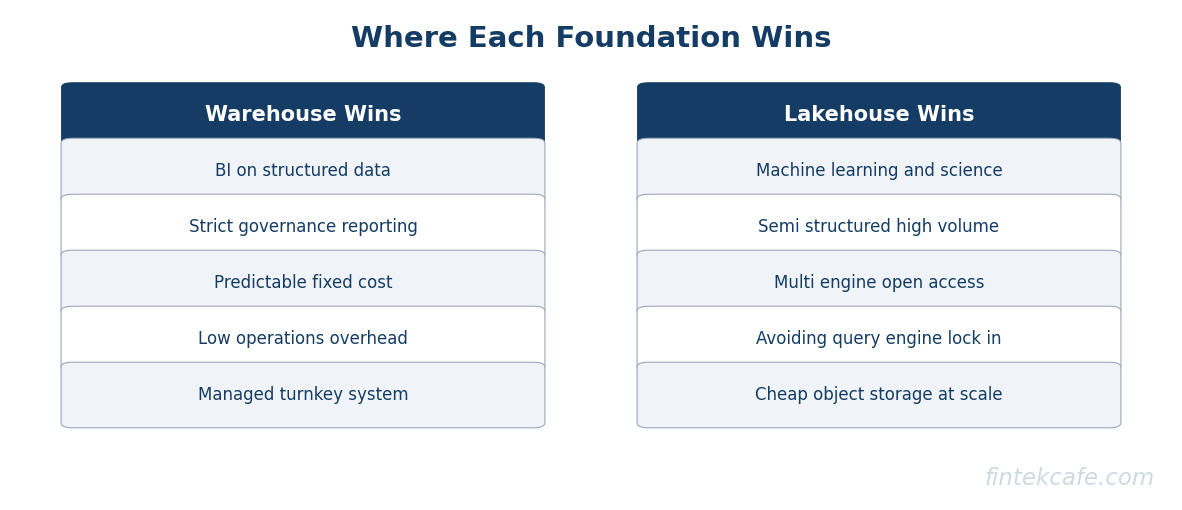
- A classic data warehouse still wins for business-intelligence reporting on structured data, strict governance, and predictable cost. It is the right default when the workload is dashboards and finance-grade reporting and the organization values a managed, low-operations system over flexibility.
- A lakehouse wins when machine learning, semi-structured data, and multi-engine access matter, or when avoiding lock-in to a single query engine is a strategic priority. It trades the warehouse's turnkey simplicity for openness and reach.
- The decision that matters more than the engine is the open table format. Apache Iceberg and Delta Lake, not the compute engine on top, determine whether your data is portable, whether multiple engines can read it safely, and whether you are locked in. Choose the format deliberately; the engine is replaceable, the format is sticky.
- The expensive failure mode is doing both badly: a half-migrated estate with a warehouse and a lakehouse running in parallel, data duplicated across them, two governance models, and double the cost. The goal is one foundation with a clear reason, not a hedge that pays for two.
The Debate Is Mostly Noise Hiding a Real Decision
Few topics in enterprise data generate more confident slideware and less clarity than the choice between a data warehouse and a data lakehouse. Every vendor has a position, and every position is conveniently aligned with what that vendor sells. The warehouse camp says lakehouses are immature and ungoverned. The lakehouse camp says warehouses are closed, expensive, and obsolete. Both are selling, and both are partly right and mostly noise.
Underneath the noise is a real architecture decision with real consequences for cost, governance, and what your organization can actually do with its data. The decision is not religious. It is situational, and it turns on the shape of your workloads rather than on which camp has the better marketing. A company whose data work is finance dashboards and regulated reporting has a different right answer than a company whose data work is training models on clickstream and document data, and pretending one architecture is universally superior is how organizations end up with the wrong foundation and a multi-year cleanup.
This article separates substance from positioning. It defines both architectures in plain terms, identifies where each genuinely wins, explains why the open table format matters more than the query engine that gets all the attention, names the migration trap that wastes the most money, and provides a decision matrix and a cost-shape comparison so the choice can be made on workload reality rather than vendor narrative.
What These Words Actually Mean
A data warehouse is a system that stores structured, modeled data optimized for fast analytical queries, with storage and compute managed together as one tightly integrated product. Data is cleaned, structured, and loaded into defined schemas before it is queried. The warehouse owns the storage format, which is proprietary and optimized for its own query engine. This integration is the source of both its strengths, speed and simplicity, and its weakness, lock-in. The data lives in the vendor's format and is queryable mainly through the vendor's engine.
A data lake is raw storage: files of any type, structured or not, sitting in cheap object storage with no imposed schema. A lake is flexible and cheap and, on its own, ungoverned and slow to query, which is why the raw lake fell out of favor as a primary analytics foundation. It became the place data went to be forgotten.
A data lakehouse is a lake with a structured table layer on top, so that raw object storage can be queried with the reliability and governance of a warehouse. The defining move is the open table format, software such as Apache Iceberg or Delta Lake, that adds transactions, schema enforcement, and versioning to plain files in object storage. The result aims to combine the lake's cheap, open, any-format storage with the warehouse's structured, governed, fast querying. The key architectural property is the separation of storage from compute: the data sits in open formats in object storage, and any compatible engine can query it, rather than the data being trapped inside one vendor's engine.
That separation is the heart of the difference. A warehouse couples storage and compute. A lakehouse decouples them. Everything else, the cost shapes, the governance trade-offs, the lock-in question, flows from that single architectural fact.
Where the Classic Warehouse Still Wins
The warehouse is not obsolete, and treating it as legacy is a marketing claim, not an engineering one. There are workloads where the warehouse remains the better foundation, and they are common ones.
Business intelligence on structured data is the warehouse's home turf. When the work is dashboards, finance reporting, and analyst queries over well-modeled tabular data, the warehouse's tight storage-compute integration delivers fast, consistent query performance with little tuning. The data is structured, the queries are predictable, and the integrated system is built precisely for this.
Strict governance and compliance favor the warehouse. A mature warehouse offers fine-grained access control, column and row-level security, auditing, and lineage as built-in, battle-tested features. In a regulated environment where every query against sensitive data must be controlled and logged, the warehouse's integrated governance is simpler to operate and easier to prove to an auditor than a lakehouse governance layer that is younger and assembled from more parts.
Predictable cost and low operational overhead favor the warehouse for teams that value that. A managed warehouse is close to turnkey. There are fewer moving parts, fewer format decisions, and less platform engineering required to keep it running. For an organization without a deep data-platform team, the warehouse's simplicity is a real and underrated advantage, because the alternative carries an operational tax that someone has to pay. Who pays that tax, and whether the organization has that capacity, is a staffing question as much as a technical one, which is why the foundation decision is inseparable from how the data team is structured.
The honest summary is that the warehouse wins when the data is structured, the workload is reporting and BI, governance is strict, and the organization prefers a managed system over maximum flexibility. That describes a large share of real enterprise analytics.
Where the Lakehouse Wins
The lakehouse wins where the warehouse's strengths turn into constraints.
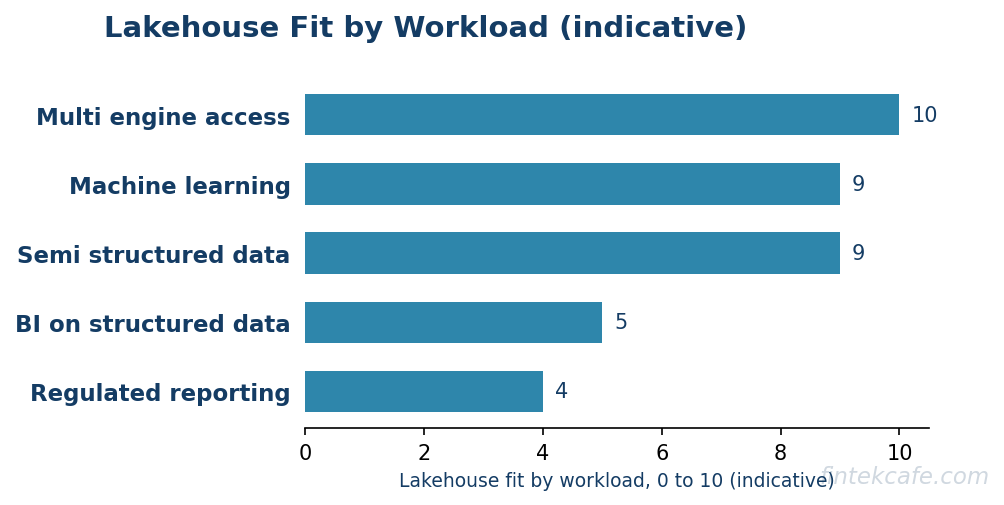
Machine learning and data science favor the lakehouse decisively. Model training needs access to raw and semi-structured data, needs to run non-SQL workloads such as Python and Spark directly against the data, and needs the cheap storage that lets you keep everything rather than only the modeled subset. Forcing this through a warehouse means exporting data out of it, which is slow, expensive, and creates copies that drift. The lakehouse lets the model training run against the same governed data the analysts query.
Semi-structured and high-volume data favor the lakehouse. Logs, events, clickstream, JSON documents, and sensor data do not fit neatly into warehouse schemas and are expensive to store in warehouse formats at scale. The lakehouse stores them cheaply in object storage and imposes structure at query time, which is both cheaper and more flexible for this class of data.
Multi-engine access favors the lakehouse by design. Because the data sits in open formats, a SQL engine, a Spark job, a streaming processor, and a data-science notebook can all read the same tables without copying the data into separate systems. This is the property a warehouse fundamentally cannot match, because the warehouse owns the format. The same decoupling that lets multiple engines share storage also lets compute scale independently of storage, which is the cost lever that makes elastic, usage-priced analytics possible, the same separation principle that drives cost optimization in Kubernetes environments where compute and storage are scaled and billed apart.
Avoiding lock-in favors the lakehouse as a strategic choice. When the data lives in an open table format in object storage you control, the query engine becomes a replaceable component rather than a permanent dependency. You can change engines without migrating the data, which preserves negotiating leverage and reduces the risk of being trapped by a single vendor's pricing. For organizations that have been burned by lock-in before, this is often the deciding factor on its own.
The honest summary is the mirror of the warehouse case. The lakehouse wins when machine learning matters, when the data is semi-structured or high-volume, when multiple engines need the same data, or when avoiding engine lock-in is a priority worth paying operational complexity for.
The Real Decision Is the Table Format, Not the Engine
Here is the point the vendor debate works hardest to obscure: the query engine gets all the attention, and the open table format is what actually matters. The engine is the part marketing fights over because engines are what vendors sell. The format is what determines whether your data is portable, whether multiple engines can safely share it, and whether you are locked in. The engine is replaceable. The format is sticky.
An open table format is a software layer that adds database guarantees, transactions, schema enforcement, and time-travel versioning, to plain data files sitting in object storage. It is what turns a directory of files into a table that multiple engines can read and write safely and concurrently. The two formats that matter are Apache Iceberg and Delta Lake. Iceberg originated to solve correctness and scale problems with very large tables and has broad multi-vendor engine support, which makes it the more neutral, engine-agnostic choice. Delta Lake originated tightly coupled to one ecosystem and has since opened up, and it is the natural choice where that ecosystem is already the center of gravity.
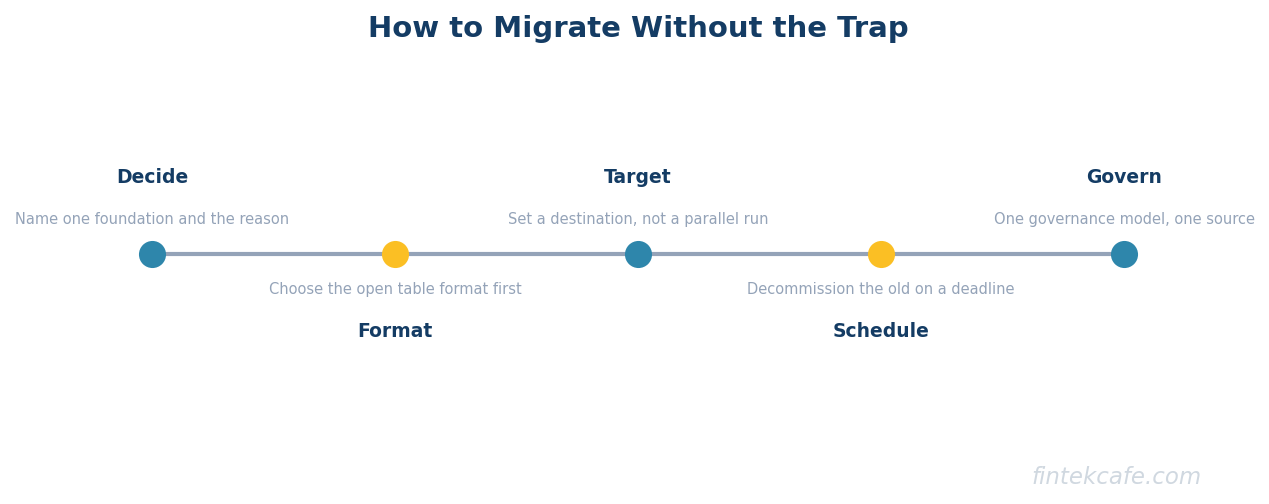
The reason the format war matters more than the engine war is durability of the decision. If you choose an engine and later want to switch, and your data is in an open format, you switch the engine and leave the data where it is. If you chose a format that only one engine reads well, switching engines means migrating the data, which is the expensive, risky project everyone wants to avoid. So the format choice is the lock-in choice, and it should be made deliberately and early, weighing the breadth of engine support against the gravity of any ecosystem you are already committed to. Choosing the engine first and inheriting whatever format it prefers is choosing lock-in by default.
This is the same pattern visible elsewhere in the modern stack, where the durable, standards-based layer outlasts the product on top of it. The argument that Postgres is quietly eating the database stack rests on the same logic: open, portable foundations win the long game against integrated products precisely because they survive the churn of the layer above them.
The Migration Trap: Doing Both Badly
The most expensive outcome is not choosing the wrong architecture. It is failing to choose and ending up with both, run badly, at the same time.
The trap unfolds predictably. An organization with a warehouse decides it needs a lakehouse for machine learning, stands one up, and starts moving workloads. The migration stalls, as migrations do, and the organization settles into a steady state nobody designed: the warehouse still runs the BI workloads, the lakehouse runs the ML workloads, and large amounts of data are copied into both. Now there are two storage bills, two compute bills, two governance models that must be kept in sync, and two sources of truth that inevitably drift apart. The data duplicated across them means a number on a dashboard and the same number in a model can disagree, and reconciling them becomes a permanent tax. The complexity of operating two platforms also pulls scarce platform-engineering effort away from delivering value, the same operational drag that makes runaway tool sprawl so costly in the observability spend on Datadog and Splunk.
Avoiding the trap does not mean migration is wrong. It means a migration needs a destination and a deadline, not an open-ended parallel run. Either commit to the lakehouse as the single foundation and decommission the warehouse workloads on a schedule, or keep the warehouse as the foundation and use the lake narrowly for the specific workloads that genuinely need it, with one governance model spanning both and no duplicated sources of truth. The failure is the indefinite hedge, paying for two foundations to avoid deciding between them.
Decision Matrix by Workload
The choice resolves cleanly once it is framed by workload rather than by vendor camp.
| Workload or priority | Warehouse | Lakehouse |
|---|---|---|
| BI and dashboards on structured data | Strong fit, default choice | Workable, less turnkey |
| Finance-grade and regulated reporting | Strong fit, mature governance | Improving, more to assemble |
| Machine learning and data science | Weak, requires data export | Strong fit, native access |
| Semi-structured and high-volume data | Expensive at scale | Strong fit, cheap storage |
| Multi-engine access to one dataset | Not possible, owns the format | Strong fit, open formats |
| Avoiding query-engine lock-in | Low, by design coupled | High, format is portable |
| Low operational overhead | Strong fit, managed system | Weak, needs platform engineering |
| Predictable, fixed-cost budgeting | Easier to predict | Variable, usage-shaped |
The pattern is symmetric. The warehouse column is strong on structured BI, governance, and simplicity. The lakehouse column is strong on machine learning, flexibility, openness, and avoiding lock-in. An organization that reads its own dominant workloads off the left column has its answer without needing to resolve the marketing debate at all.
How the Cost Shapes Differ
Cost is where the architectures differ in kind, not just in amount, and the difference is the shape of the bill rather than the size.
A warehouse tends toward a more predictable, integrated cost. Storage and compute are billed together or in tightly coupled units, and for a steady BI workload the bill is relatively stable and easy to forecast. The risk is paying for coupled capacity you do not fully use, and paying a premium for the proprietary storage format at high volumes.
A lakehouse tends toward a variable, decoupled cost that follows usage. Storage is cheap object storage billed separately from compute, and compute is spun up per workload, so a quiet period costs little and a heavy machine-learning run costs a lot. This is efficient when usage is genuinely variable and wasteful when an unmanaged team leaves compute running, which is the same elastic-cost discipline problem that dominates Kubernetes cost optimization: the separation of storage and compute that enables efficiency also enables runaway spend without governance.
The honest framing is that neither is cheaper in the abstract. The warehouse is cheaper to predict and to operate with a small team. The lakehouse is cheaper to scale and to run variable workloads on, if the organization has the discipline to manage decoupled compute. The cost question is therefore really a question about workload variability and operational maturity, which loops back to the same staffing reality that runs through the whole decision.
FAQ
What is the difference between a data lake, a data warehouse, and a data lakehouse?
A data warehouse stores structured, modeled data with storage and compute tightly integrated, optimized for fast BI queries but coupled to one vendor's format. A data lake is raw, cheap, any-format storage with no imposed structure, flexible but ungoverned and slow to query. A data lakehouse adds an open table layer on top of a lake so raw object storage can be queried with warehouse-like reliability and governance, combining cheap open storage with structured querying.
Is Iceberg or Delta Lake the better open table format?
Neither is universally better; the right choice depends on engine support and ecosystem gravity. Apache Iceberg is the more engine-agnostic option with broad multi-vendor support, which favors organizations prioritizing neutrality and portability. Delta Lake is the natural fit where its originating ecosystem is already the center of the data stack. The format decision matters more than the engine decision because the format determines lock-in: the engine is replaceable, the format is sticky.
When should we stay on a data warehouse instead of moving to a lakehouse?
Stay on a warehouse when your dominant workloads are BI and finance-grade reporting on structured data, when governance and compliance requirements are strict, and when you value a managed, low-operations system over maximum flexibility. The warehouse is also the better choice for teams without deep data-platform engineering capacity, because the lakehouse carries an operational tax that someone has to pay. Moving to a lakehouse is justified by machine learning, semi-structured data, multi-engine access, or avoiding engine lock-in.
Why is running both a warehouse and a lakehouse a problem?
Running both indefinitely means two storage bills, two compute bills, two governance models to keep in sync, and data duplicated across systems that drift into disagreeing sources of truth. It doubles cost and complexity while pulling platform engineering away from delivering value. A migration is fine when it has a destination and a deadline; the failure is the open-ended parallel run that hedges instead of deciding.
Does a lakehouse actually cost less than a warehouse?
Not in the abstract. A lakehouse decouples cheap object storage from per-workload compute, which is cost-efficient for variable workloads but can run away without governance on idle compute. A warehouse has a more predictable, integrated cost that is easier to forecast and to operate with a small team. The lakehouse is cheaper to scale; the warehouse is cheaper to predict. The right answer depends on workload variability and operational maturity.
Related reading on FinTekCafe
Related Articles

Disaster Recovery Planning: What Technology Leaders Actually Need
Disaster recovery for technology leaders: RTO and RPO tiering, the four DR architecture patterns with honest cost multiples, testing, and cloud-era failures.

The Great SaaS Consolidation: Why Enterprises Are Firing Half Their Vendors
SaaS consolidation is a power transfer to platform vendors, not a cost story. What gets cut, what survives, and how to consolidate without losing leverage.

Technical Due Diligence: How to Evaluate a Company's Technology Before You Buy
What technical due diligence examines, the red flags that kill deals versus reprice them, how AI changes the checklist, and how to scope a rigorous review.