Small Language Models in the Enterprise: When Smaller Beats Bigger

Key Takeaways
- The default assumption that the largest frontier model always produces the best business outcome is breaking down for a large class of enterprise work. On narrow, well-defined tasks, small and mid-sized models now reach competitive accuracy at a fraction of the cost and latency, with privacy and data-residency properties that hosted frontier APIs cannot match.
- The decision is not about which model is smartest in the abstract. It turns on five concrete axes: task complexity, latency budget, cost per query at production volume, data sensitivity, and deployment surface. A model that scores well across those axes for a given task is the right model, regardless of parameter count.
- Small language models already win on classification, extraction, routing, and on-device assistance. Frontier models stay necessary for open-ended reasoning, long-context synthesis, and tasks where the input distribution is genuinely unpredictable.
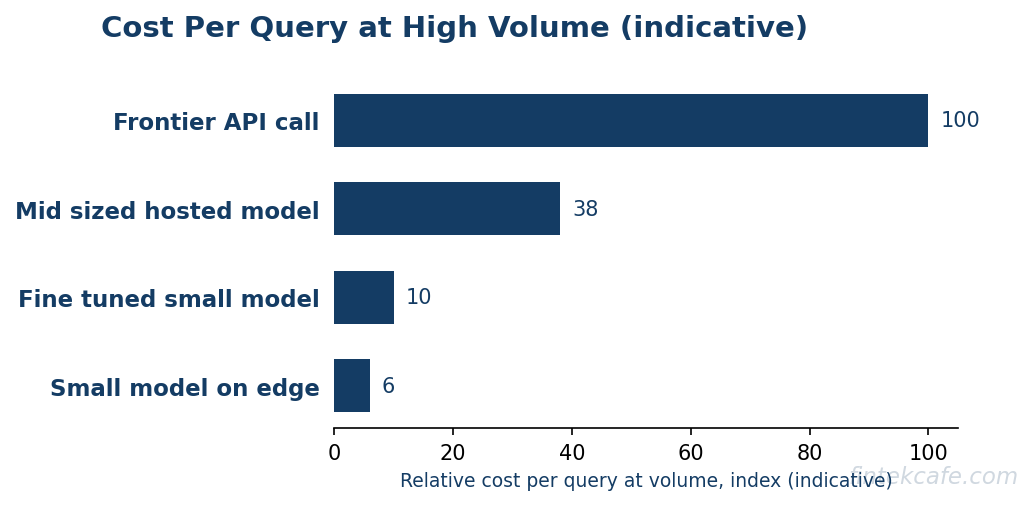
- Cost compounds at volume. A workload running millions of calls per month is where the gap between a frontier API and a fine-tuned small model becomes the difference between a viable unit economic model and an unviable one.
- The most common and most expensive mistake is reaching for a frontier model by reflex. The cheaper, faster, more private option is often good enough, and the only way to know is to measure both against a real evaluation set rather than a vendor benchmark.
The Bigger-Is-Better Assumption Is Quietly Failing
For three years the prevailing enterprise instinct was simple: pick the largest, most capable frontier model available, route everything through it, and absorb the cost as the price of quality. That instinct made sense when the capability gap between large and small models was wide and when most teams were still learning what the technology could do.
In 2026 that instinct is increasingly wrong, and it is wrong in a way that shows up directly on the income statement. A growing share of production AI workloads consists of narrow, repetitive, well-defined tasks: classifying a support ticket, extracting fields from an invoice, routing a request to the correct queue, summarizing a single document, drafting a templated reply. For tasks like these, the marginal accuracy a frontier model adds over a competently fine-tuned small model is often negligible, while the cost and latency it adds are not.
The term small language model has no formal boundary, but the working definition that matters to a decision-maker is this: a small language model is a model small enough to run cost-effectively on a single accelerator, a CPU, or an edge device, while still handling a defined business task at acceptable accuracy. In practice that covers models from a few hundred million to roughly fifteen billion parameters, whether they are open-weight models fine-tuned on internal data or compact hosted models offered as a cheaper tier by the same vendors that sell frontier access.
The strategic point is that model selection has become a portfolio decision rather than a single choice. Organizations that get this right run a mix: frontier models for the hard, open-ended work, and a fleet of smaller models for the high-volume, narrow work that makes up most of the request traffic.
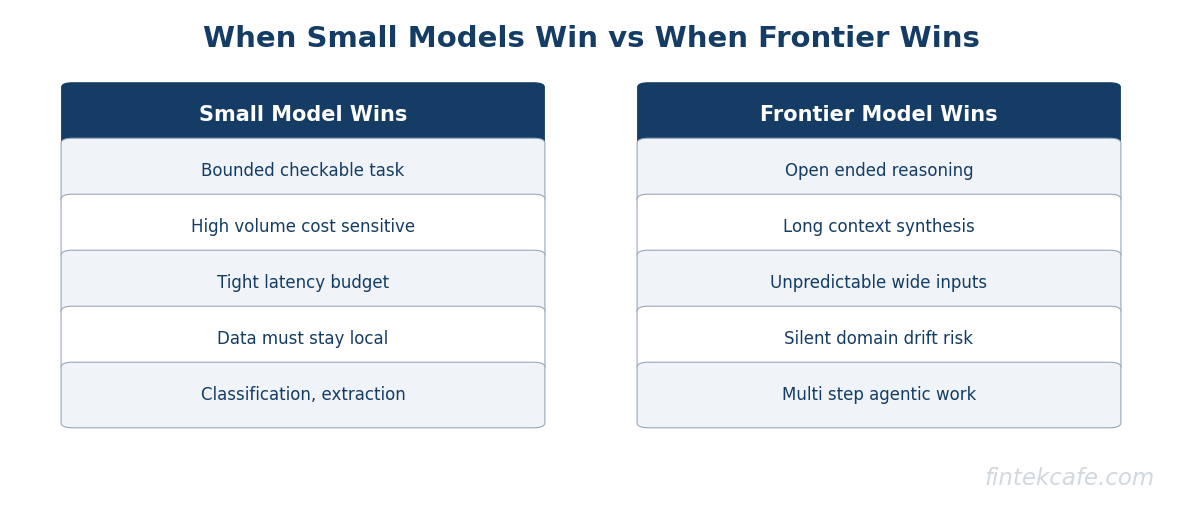
The Five Axes That Actually Decide the Choice
Most model-selection debates stall because they argue about intelligence in the abstract. The productive framing is to score a specific task against five axes and let the answer fall out.
Task complexity
The first question is whether the task has a checkable, bounded answer or whether it is genuinely open-ended. Classifying a ticket into one of twenty categories is bounded. Synthesizing a regulatory filing from forty source documents is not. Bounded tasks with a narrow output space are exactly where small models, especially fine-tuned ones, close the gap with frontier models. Open-ended reasoning over unpredictable inputs is where frontier capability still earns its cost.
Latency budget
A model that answers in eighty milliseconds and a model that answers in four seconds are not substitutes, even at identical accuracy. Anything in a user-facing interactive loop, an on-device assistant, a real-time routing decision, a fraud check, has a latency budget that frontier API round trips often cannot meet. Smaller models running close to the request, sometimes on the device itself, win on latency by construction.
Cost per query at volume
This is the axis that surprises teams. A frontier API call may cost a fraction of a cent, which feels free in a prototype. Multiply it by ten million calls a month and it becomes a material line item. A fine-tuned small model running on owned or reserved infrastructure can cut the per-query cost by an order of magnitude or more at that volume. The hidden components of inference cost, throughput, batching efficiency, and idle capacity, deserve the same scrutiny a CFO would apply to any per-unit cost, and the article on the hidden costs of LLM inference and token pricing lays out where those costs actually accumulate.
Data sensitivity
If the input contains regulated data, customer financial records, health information, material non-public information, or anything bound by data-residency rules, the question is not only accuracy but where the data is allowed to go. A self-hosted small model keeps the data inside the organization's trust boundary. A hosted frontier API, however well governed, moves it across one. For many regulated workloads, that single fact decides the architecture before accuracy is even discussed.
Deployment surface
Finally, where does the model need to run? A model embedded in a mobile app, a point-of-sale terminal, an industrial sensor, or an air-gapped environment cannot depend on a frontier API at all. The deployment surface can rule out the hosted option entirely and make a compact model the only viable choice.
A Model-Tier Decision Table
The following table maps common enterprise workloads to a recommended model tier. The tiers are defined by capability and deployment, not by any single vendor.
| Workload | Task type | Latency need | Data sensitivity | Recommended tier |
|---|---|---|---|---|
| Support ticket classification | Bounded, high volume | Sub-second | Often regulated | Fine-tuned small model |
| Invoice and document field extraction | Bounded, structured output | Seconds acceptable | Frequently sensitive | Fine-tuned small or mid model |
| Request routing and intent detection | Bounded, very high volume | Sub-second | Mixed | Small model, often on-device |
| On-device assistant and autocomplete | Bounded, interactive | Tens of milliseconds | High, stays local | On-device small model |
| Single-document summarization | Semi-bounded | Seconds acceptable | Variable | Mid-sized model |
| Multi-document synthesis and analysis | Open-ended, long context | Seconds to minutes | Variable | Frontier model |
| Open-ended research and planning | Unbounded reasoning | Tolerant | Variable | Frontier model |
| Agentic tool use over unpredictable inputs | Open-ended, multi-step | Tolerant | Variable | Frontier model, narrowed scope |
The pattern is consistent. As tasks move from bounded to open-ended, from predictable inputs to unpredictable ones, and from short context to long context, the case for a frontier model strengthens. As tasks move toward high volume, tight latency, and sensitive or local data, the case for a smaller model strengthens.
Where Small Models Already Win
Four workload families are now firmly in small-model territory for most organizations.
Classification. Routing a message into a fixed set of categories is the canonical bounded task. A small model fine-tuned on a few thousand labeled examples routinely matches frontier accuracy on the organization's own category scheme, because the task rewards fit to the specific label distribution rather than general world knowledge.
Extraction. Pulling structured fields out of documents, invoices, contracts, forms, statements, is high volume, latency-sensitive, and often touches regulated data. All three properties favor a smaller, self-hosted model. The output space is constrained, which means a fine-tuned model can be evaluated precisely and improved deterministically.
Routing. Deciding which downstream system, queue, or model should handle a request is a meta-task that itself runs on every inbound request. It has to be fast and cheap by definition, because it sits in front of everything else. This is a natural home for a compact model, and increasingly for one running on the device or at the edge.
On-device assistance. Autocomplete, local summarization, smart replies, and similar interactive features need tens-of-milliseconds latency and frequently must work without sending user data anywhere. A model running on the device is the only design that satisfies both constraints, and 2026-era compact models are capable enough to make that experience genuinely useful rather than a degraded fallback.
What unites these is that the task has a checkable answer, a constrained output, and a volume or latency or privacy profile that punishes the frontier option. Evaluation is tractable, which is what makes the smaller model safe to deploy. Building that evaluation discipline is its own competency, covered in the executive guide to AI evals.
Where Frontier Models Stay Necessary
The honest version of this argument names the limits. Small models lose, sometimes badly, in three situations.
The first is open-ended reasoning over unpredictable inputs. When the input distribution is genuinely wide and the task requires connecting facts the model was never fine-tuned on, frontier capability is not a luxury. A small model fine-tuned for a narrow domain degrades sharply the moment the input leaves that domain, and it often degrades silently, returning a confident wrong answer rather than an obvious failure.
The second is long-context synthesis. Reading dozens of documents and producing a coherent analysis that respects all of them is a workload where frontier models, with their larger effective context and stronger reasoning, still lead by a wide margin. Compressing that work onto a small model usually means losing fidelity in ways that are expensive to detect.
The third is multi-step agentic work over tasks that cannot be tightly scoped. The reliability of an agent degrades with the unpredictability of its environment, and a frontier model's broader competence buys margin against that unpredictability. The discipline of narrowing agent scope so that even a capable model stays reliable is the subject of what actually works for enterprise AI agents in 2026.
A useful rule: if you cannot write an evaluation set that captures what success looks like, you are probably in frontier-model territory, because the absence of a checkable answer is exactly the condition under which raw capability matters most.
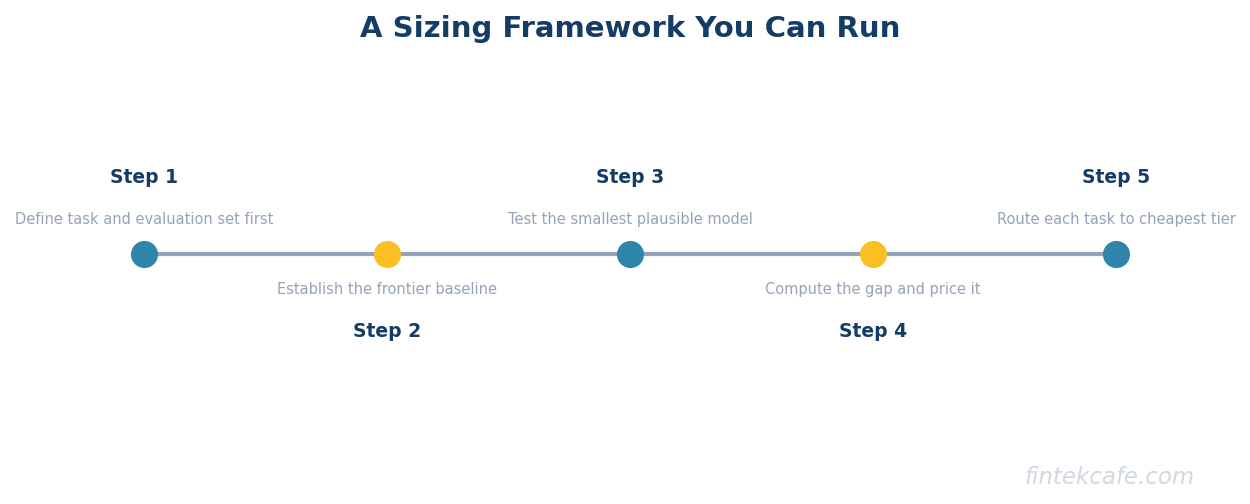
A Sizing Framework You Can Run
Translating the five axes into a decision needs a repeatable process, not a one-time argument. The following sequence works for a single workload.
- Define the task and its evaluation set first. Before choosing any model, write down what a correct output looks like and assemble a few hundred real examples with known-good answers. Without this, every downstream comparison is opinion.
- Establish the frontier baseline. Run the best available frontier model against the evaluation set and record accuracy, latency, and cost per query. This is the quality ceiling and the cost ceiling.
- Test the smallest plausible model next. Run a compact model against the same set, first as-is, then fine-tuned on a slice of the task data. Record the same three metrics.
- Compute the gap and price it. Express the accuracy difference in business terms. If the small model is two percentage points behind on classification but costs a tenth as much and answers ten times faster, the question becomes whether those two points are worth the premium at your volume. Often they are not. Sometimes, in regulated or high-stakes flows, they are.
- Decide where the data is allowed to go. If sensitivity or residency rules out the hosted option, the decision is made independent of the accuracy gap, and the work shifts to closing that gap with fine-tuning and retrieval rather than to model selection.
- Choose retrieval and fine-tuning deliberately. A small model paired with good retrieval frequently beats a larger model working blind, because the missing knowledge is supplied at query time rather than baked into parameters. The trade-offs among fine-tuning, retrieval, and long context are laid out in the decision guide on fine-tuning versus RAG versus long context, and pairing a small model with retrieval often depends on a vector database, which is worth adopting only when the use case calls for one.
The output of this framework is not a single model. It is a routing policy: which tasks go to which tier, with the frontier model reserved for the work that genuinely needs it and the small models carrying the volume.
The Economic Case, Stated Plainly
The reason this matters to executives rather than only to engineers is that model selection is now a unit-economics decision. An AI feature whose per-query cost is set by a frontier API may be unprofitable at scale even when it delights users in a demo. The same feature, served by a fine-tuned small model for the common case and escalated to a frontier model only for the hard tail, can have a cost structure that survives growth.
Organizations consistently find that the highest-leverage move is not switching everything to small models, which would sacrifice quality on the hard tasks, but building the routing layer that sends each request to the cheapest model that can handle it. That layer is where the savings live, and it is invisible to anyone looking only at model benchmarks.
The evidence from production deployments in 2026 points the same direction: the teams with healthy AI economics are the ones that stopped treating model choice as a brand decision and started treating it as a per-task optimization, measured against their own evaluation sets and their own cost and latency budgets.
Key Takeaways for Decision-Makers
The frontier model is not the safe default. It is the expensive default, and it is the right choice only for the subset of work that is open-ended, long-context, or genuinely unpredictable. For the large remainder, the narrow, high-volume, latency-sensitive, privacy-bound work that makes up most request traffic, a smaller model is frequently faster, cheaper, more private, and accurate enough. The organizations that win on AI economics in 2026 are the ones that measure both and route accordingly.
Frequently Asked Questions
What counts as a small language model in 2026?
There is no official cutoff, but the practical definition is a model small enough to run cost-effectively on a single accelerator, a CPU, or an edge device while still handling a defined task at acceptable accuracy. In practice that spans roughly a few hundred million to about fifteen billion parameters, whether the model is open-weight and fine-tuned in-house or a compact hosted tier.
When should an organization choose a small model over a frontier model?
Choose the smaller model when the task is bounded and checkable, the volume is high enough that per-query cost matters, the latency budget is tight, or the data cannot leave the organization's trust boundary. Choose the frontier model when the task is open-ended, requires long-context synthesis, or runs over genuinely unpredictable inputs where a fine-tuned model would degrade silently.
Do small models actually match frontier accuracy?
On narrow, well-defined tasks such as classification, extraction, and routing, a small model fine-tuned on the organization's own data routinely reaches accuracy within a point or two of a frontier model, and sometimes matches it. On open-ended reasoning and long-context work the gap remains wide. The only reliable way to know is to test both against a real evaluation set rather than trusting a vendor benchmark.
How much can small models actually save at scale?
The saving is most visible at high volume. A fine-tuned small model on owned or reserved infrastructure can cut per-query cost by an order of magnitude or more relative to a frontier API at millions of calls per month. The largest gains usually come from a routing layer that sends only the hard tail of requests to the frontier model and serves the common case cheaply.
What is the most common mistake teams make here?
Reaching for the frontier model by reflex. The cheaper, faster, more private option is frequently good enough, and defaulting to the largest model leaves cost, latency, and privacy advantages on the table. The fix is to treat model selection as a per-task measurement rather than a single brand decision.
Related Articles

The AI Headcount Illusion: What Agents Actually Do to the Org Chart
Agents rarely shrink payrolls. They convert doing-work into checking-work, and winning org charts are redesigned around that conversion, not headcount.
The Total Cost of AI: A Framework for Pricing an AI Initiative End to End
An eight-line total cost of ownership framework for enterprise AI, with a worked example, realistic cost shares, and a build-buy-wait decision table.

AI Governance: How to Build an AI Policy That Actually Gets Followed
Why AI policies fail as documents and work as controls: a three-tier governance model, ownership patterns, EU AI Act duties, and metrics that matter.