What Is Vector Search? How Embeddings Power Modern AI Retrieval

Vector search is the per-query operation that turns a piece of text, an image, or a structured prompt into a point in high-dimensional space and finds the closest other points already stored in an index. It is the underlying machinery of every "chat with your documents" feature, every retrieval-augmented generation (RAG) pipeline, and most of the "similar to this" recommendations shipped by modern AI products. The technology is not new (Facebook's FAISS library is from 2017) but its 2023 to 2026 adoption inside the enterprise has produced a vendor market, a procurement pattern, and a set of misconceptions worth correcting.
This article explains what vector search actually is, how the underlying nearest-neighbor algorithms work, where vector search beats keyword search and where it loses, the 2026 vendor landscape, the hybrid-search pattern most production systems converge on, and a decision framework for picking the right starting architecture.
What Vector Search Is, in Plain English
Vector search is similarity search over numerical representations of content. An embedding model takes some input (a sentence, a paragraph, a code snippet, an image) and produces a fixed-length vector of floating-point numbers, often 384, 768, 1024, or 1536 dimensions in modern models. Two inputs that mean similar things produce vectors that are mathematically close (measured by cosine similarity, dot product, or Euclidean distance). At query time, the query is embedded with the same model and the index returns the K nearest stored vectors. Those K results are the "search results."
The reason vector search matters is that it captures semantic similarity rather than lexical overlap. A user query phrased as "cancel a subscription" can match a stored document titled "ending your paid plan" with zero shared keywords, because the embedding model has learned that those phrases occupy similar regions of vector space. Traditional BM25 keyword search would miss this match unless the document or the query contained the right synonyms.
The cost of that capability is real. Vector search adds an embedding step at write time, an embedding step at query time, a much larger index footprint than an inverted index, and a class of failure modes (relevance drift, embedding-model versioning) that keyword search does not have.

How Embeddings Turn Content Into Points in Space
Embeddings come from a neural network trained to compress meaning into geometry. The training procedure that produced OpenAI's text-embedding-3-large, Cohere's embed-multilingual-v3, Voyage AI's voyage-3, and the open-source BGE and E5 families used contrastive learning: the model is shown pairs of related and unrelated content and pushed to place related content close together and unrelated content far apart. After billions of training pairs the model has internalized a geometry of meaning that is good enough for production retrieval.
A few facts that matter operationally:
Dimensions are not free. A 1536-dimensional embedding takes 6 kilobytes per vector at float32, or 1.5 kilobytes at int8 quantization. A 100 million vector corpus at 1536 dimensions is on the order of 600 GB raw, before any index structures. Modern vendors compress aggressively (scalar and product quantization can reach 4 to 8 bits per dimension with limited recall loss), but the cost line items are real.
Different embedding models produce incompatible vector spaces. Cosine similarity between an OpenAI vector and a Cohere vector is meaningless. Switching embedding models means re-embedding the entire corpus.
Embedding models have a context window. Most production embedding models take 512 to 8192 tokens. Documents longer than the window must be chunked, and the chunking strategy meaningfully affects retrieval quality.
Embeddings drift. A 2023 embedding model trained before a regulatory term existed will not encode that term well. Domain-specific fine-tuned embeddings (financial, legal, medical) routinely beat general-purpose ones on in-domain queries by 10 to 30 percent on retrieval benchmarks.
How Nearest-Neighbor Search Actually Works
A brute-force nearest-neighbor search compares the query vector to every stored vector. For 10,000 vectors this is fine. For 10 million it is not. Modern vector databases use approximate nearest neighbor (ANN) algorithms that trade a small amount of recall for one to three orders of magnitude better latency.
Three algorithm families dominate the 2026 landscape:
HNSW (Hierarchical Navigable Small World)
HNSW builds a multi-layer graph where each node is a vector and edges connect each vector to a small number of its nearest neighbors. Queries traverse the graph from the top layer down, following edges that get progressively closer to the query. HNSW typically delivers 95 to 99 percent recall at sub-millisecond latency for corpora up to roughly 100 million vectors per shard.
HNSW is the default for Pinecone, Weaviate, Qdrant, Milvus, and pgvector (since the 0.5 release in 2023). The trade-off is memory: the graph structure itself adds 20 to 40 percent on top of the raw vector storage, and HNSW is hard to update efficiently for write-heavy workloads.
IVF (Inverted File Index)
IVF partitions the vector space into clusters (typically a few thousand) using k-means and stores each vector in its assigned cluster. Queries find the closest clusters first, then search within them. IVF is more memory-efficient than HNSW and updates more cheaply, at the cost of lower recall for the same speed budget.
IVF is the workhorse for very large corpora (multi-billion-vector deployments) and is the basis for FAISS configurations like IVF-PQ (inverted file with product quantization).
ScaNN and DiskANN
Google's ScaNN and Microsoft's DiskANN target the workloads HNSW cannot serve cost-effectively: billion-vector corpora that must run on disk rather than in memory. DiskANN in particular delivers competitive recall at latencies in the 10 to 50 millisecond range while keeping the index on SSD, which makes the per-vector cost roughly an order of magnitude lower than in-memory HNSW. Turbopuffer's serverless vector search is built on this pattern.
The Recall-Latency-Cost Triangle
Every ANN deployment picks two of: high recall, low latency, low cost. A typical operational target is 95 percent recall at 50 milliseconds at moderate cost; chasing 99 percent recall pushes latency or cost up by 2x to 5x. Treating any of the three as a free variable produces deployments that work in the demo and fail under load.
Where Vector Search Beats Keyword Search, and Where It Loses
Vector search beats keyword search when the user query expresses intent rather than exact terms. "Documents about regulatory compliance burdens after the 2024 reform" is a query that vector search can answer even if no document uses those exact words. "Show me posts that critique microservices" is answerable because critique-of-microservices content occupies a coherent region of embedding space even when the author never used the word "critique."
Keyword search beats vector search when the query contains identifiers, codes, or precise terms. A query of "MT103" should match documents containing "MT103," not documents about "international wire formats." A query of a CVE number, a SKU, a customer ID, or an error code is a keyword problem and pure vector search degrades it. Embeddings tend to over-generalize identifiers, treating "MT103" and "MT202" as nearly identical when they refer to entirely different SWIFT messages.
Keyword search also wins on legal and compliance retrieval where the user expects exact-phrase matching, on internal-search workloads with strong title-and-tag metadata, and on very small corpora where the embedding step adds cost without benefit.
| Workload | Best fit | Why |
|---|---|---|
| Open-ended Q&A over documents | Vector or hybrid | Intent-based queries; vague phrasing |
| Code search by intent | Vector | "Function that retries failed payments" |
| Code search by symbol name | Keyword | "PaymentProcessor.retry" |
| Product catalog ("blue running shoes") | Vector | Captures color, type, use |
| Product catalog by SKU | Keyword | Exact identifier match |
| Regulatory text retrieval | Hybrid, keyword-first | Exact-phrase tolerance is required |
| Image similarity | Vector | Embeddings are the only option |
| Log search by error code | Keyword | Codes degrade in embedding space |
| Long-tail FAQ matching | Hybrid | Combines synonym tolerance and term precision |
Hybrid Search: The Pattern Most Production Systems Converge On
Hybrid search runs both vector search and BM25 keyword search in parallel and fuses the two ranked lists, usually with reciprocal rank fusion (RRF) or a learned reranker on top. The hybrid pattern delivers measurably better quality than either approach alone on most enterprise workloads. Benchmarks published by Elastic, Weaviate, OpenSearch, and Microsoft Research over 2023 to 2025 consistently show hybrid retrieval beating pure-vector retrieval by 5 to 20 percent on standard relevance metrics (NDCG@10, MRR), with the gain biggest on queries that contain identifiers or proper nouns alongside intent words.
Hybrid search also reduces operational risk. A pure-vector deployment is one bad embedding-model upgrade away from a quality regression. A hybrid deployment degrades gracefully because the BM25 component continues to work even if the vector component drifts.
The production pattern is converging on:
- Index both the raw text (BM25) and the embedding (vector ANN).
- Retrieve top K from each (typically K of 50 to 200).
- Fuse the two lists using RRF or a small learned model.
- Optionally rerank the top 10 to 20 with a cross-encoder reranker like bge-reranker-v2-m3, Cohere Rerank, or Voyage rerank-2.
The reranker step is where most of the quality gains in 2025 to 2026 production deployments are coming from. Cross-encoder rerankers see the query and each candidate document together and score them in context, which captures relevance signals that bi-encoder embeddings cannot.
The 2026 Vector Search Vendor Landscape
The vendor market sorted itself out across 2024 and 2025. By 2026 the practical choices are:
| Vendor / Stack | Strength | Where it fits |
|---|---|---|
| pgvector (Postgres extension) | Runs in your existing database, transactional, free | Less than 10 to 50 million vectors, where Postgres is already the system of record |
| Pinecone | Managed, serverless, mature operations | Mid-market and enterprise, low ops burden |
| Weaviate | Open-source, strong hybrid search, schema support | Teams that want SQL-like control with hybrid built in |
| Qdrant | Open-source, payload filtering, performant | Self-host or managed, strong on filtered queries |
| Milvus / Zilliz | Multi-billion vector scale, GPU acceleration | Workloads beyond 100 million vectors |
| OpenSearch / Elastic k-NN | Hybrid search in the same engine as logs and BM25 | Teams already on OpenSearch or Elastic |
| Turbopuffer | Serverless DiskANN, very low cost per vector | Cost-sensitive at scale, willing to accept higher P99 |
| Vespa | Mature ranking, hybrid, real-time updates | Search-as-a-product, high-stakes ranking |
| Couchbase / MongoDB Atlas Vector | Bundled with existing document database | Already on the platform, simpler operational story |
The most common 2026 mistake is over-engineering the procurement. Most enterprise pilots have fewer than 10 million vectors, which means pgvector on managed Postgres (RDS, Aurora, Neon, Supabase) is the right starting answer, and the engineering capacity that would have gone into operating a separate vector database goes into building the retrieval and reranking pipeline that actually drives quality.
The case for a dedicated vector database in 2026 is: you have crossed roughly 50 to 100 million vectors per index, your query throughput exceeds Postgres-on-IOPS limits (a few hundred queries per second sustained), you need multi-region replication for read latency, or your team has the operational budget to run a second specialized data store.
A Decision Framework: Vector DB vs Hybrid Postgres
The decision tree below captures the choice for most enterprise AI teams in 2026:
- Is the corpus under 10 million vectors and stable? Start with pgvector on managed Postgres. Add BM25 via Postgres full-text search and combine with RRF.
- Is the corpus 10 to 100 million vectors with moderate write rate? pgvector with HNSW indexes is still viable up to roughly 50 million vectors per table; beyond that, evaluate Qdrant, Weaviate, or Pinecone.
- Is the corpus over 100 million vectors, or do you need GPU-accelerated search? Milvus, Vespa, or Turbopuffer become the right answer.
- Do you need strong filtering on metadata at query time (tenant ID, date ranges, ACLs)? Qdrant's payload filtering and Pinecone's metadata filtering are stronger than pgvector here, though pgvector with proper indexes can handle a meaningful subset.
- Do you need search and analytics in the same engine? OpenSearch or Elastic, accepting the operational complexity.
The most common failure mode in 2026 is teams skipping step 1 and procuring a specialized vector database for a 2 million vector pilot, then spending six months building the operational capability that pgvector would have given them for free.
The Cost-Per-Million-Vectors Reality
Approximate 2026 cost ranges, normalized to one million vectors at 1536 dimensions with HNSW or equivalent, including replication and modest query load. Source: vendor public pricing pages, May 2026, with regional and reserved-instance discounts not applied.
| Stack | Monthly storage cost per million vectors | Notes |
|---|---|---|
| pgvector on managed Postgres | USD 5 to USD 20 | Storage cheap; compute is the constraint at scale |
| Pinecone serverless | USD 20 to USD 80 | Pay-per-use, low ops |
| Qdrant Cloud | USD 25 to USD 60 | Strong filtering, similar to Pinecone |
| Weaviate Cloud Services | USD 30 to USD 90 | Hybrid built in |
| Milvus / Zilliz Cloud | USD 30 to USD 100 | Scales much further |
| Turbopuffer | USD 1 to USD 10 | DiskANN, higher P99 |
| OpenSearch Service (k-NN) | USD 40 to USD 120 | Bundled with logs and BM25 |
Query cost is a separate axis (usually billed per million queries or per query unit) and tends to dominate the bill for read-heavy workloads. Cost is not the most important variable below 10 million vectors. Above that scale, the choice meaningfully affects monthly run-rate.
Common Failure Modes
Chunking strategy ignored. The single largest determinant of retrieval quality in production RAG systems is the chunking strategy, not the embedding model or the database. Fixed-size 512-token chunks are a starting point; semantic chunking (sentence boundaries, structural boundaries) consistently outperforms.
No reranker. A surprising share of 2025 to 2026 production pilots ship without a reranker. Adding one is the highest-leverage quality intervention available.
Pure-vector for everything. Identifiers, codes, and proper nouns belong in keyword search. Pure-vector systems regress on these queries.
Embedding-model upgrade with no re-embed budget. New embedding models ship every six to twelve months. Teams that have not budgeted re-embedding cost for the corpus discover late that they are locked into a 2024 model with worse recall than 2026 alternatives.
No evaluation harness. Teams that ship vector search without a labeled evaluation set cannot tell whether a configuration change made retrieval better or worse. The lack of an eval harness is the strongest predictor of project regression over the following twelve months.
Frequently Asked Questions
Is vector search the same as semantic search?
In practice yes, with one nuance. Semantic search is the user-facing capability of retrieving content by intent rather than exact term match. Vector search is one implementation of that capability and the dominant implementation in 2026. Some semantic search systems use other approaches (knowledge graphs, structured rule sets, query rewriting with LLMs), but when a vendor says "semantic search" in 2026 they almost always mean vector search underneath.
Do you still need keyword search if you have vector search?
Yes, for production-grade retrieval. Pure-vector systems regress on queries that contain identifiers, codes, proper nouns, or exact phrases. The dominant production pattern is hybrid: run both vector and BM25 in parallel and fuse the results. The hybrid pattern is what underlies the hybrid retrieval architecture we covered in our vector database guide and what most enterprise RAG systems converge on.
How big does the corpus need to be before a dedicated vector database is worth it?
The practical threshold in 2026 is roughly 10 to 50 million vectors. Below that, pgvector on managed Postgres is the right starting answer for most teams because it removes an operational burden without meaningfully compromising quality. Above 50 to 100 million vectors per index, the recall, latency, and cost characteristics of a purpose-built vector database become hard to replicate in Postgres.
What is the difference between HNSW and IVF?
HNSW (Hierarchical Navigable Small World) is a graph-based index that delivers high recall at very low latency, at the cost of higher memory usage and slower updates. IVF (Inverted File Index) partitions the vector space into clusters and is more memory-efficient and update-friendly, at the cost of lower recall for the same speed. HNSW dominates the in-memory enterprise deployments below roughly 100 million vectors per shard; IVF and its variants dominate at multi-billion-vector scale and in disk-resident configurations like DiskANN.
How often do embedding models need to be updated?
Embedding models from major vendors release new versions every six to twelve months, and the new version is typically 5 to 15 percent better on standard retrieval benchmarks. Most production teams update on a 12 to 18 month cycle, batching the re-embedding cost. Re-embedding a 50 million document corpus with a modern model costs in the low thousands of dollars at 2026 API pricing and takes a few days end-to-end; the cost is not the constraint, the operational migration is.
Key Takeaways
- Vector search is similarity search over numerical embeddings. An embedding model converts text or images into points in high-dimensional space, and the index returns the closest stored points to a query vector. The capability that matters operationally is matching by intent rather than by exact term.
- HNSW is the default ANN algorithm for in-memory deployments under 100 million vectors; IVF and DiskANN dominate at larger scale and disk-resident configurations. Every deployment trades among recall, latency, and cost; treating any of the three as free produces deployments that work in the demo and fail under load.
- Hybrid search beats pure-vector search on most production workloads. Combine BM25 and vector retrieval, fuse with reciprocal rank fusion, and add a cross-encoder reranker on the top 10 to 20 candidates. This pattern is the highest-leverage quality intervention available in 2026.
- pgvector on managed Postgres is the right starting point for most 2026 enterprise pilots. A dedicated vector database becomes the right answer at roughly 10 to 50 million vectors and beyond, or when filtering, multi-region, or GPU-accelerated workloads enter the picture.
- The most common failure modes are operational, not algorithmic. Bad chunking strategy, no reranker, no evaluation harness, and no budget for the next embedding-model upgrade collectively account for the majority of vector-search regressions in production.
Related reading on FinTekCafe
- Vector Databases: When You Actually Need One: sister article focused on the procurement decision
- What Are AI Evals? An Executive Guide: why every retrieval system needs an evaluation harness
- What Is a Data Lakehouse? A Decision-Maker's Guide: where vector indexes sit in the modern data stack
- The Real Cost of AI Infrastructure: the budget framing for compute, storage, and inference
- Prompt Engineering for Business: A Practical Guide: the prompting layer that consumes retrieval output
Related Articles

The AI Headcount Illusion: What Agents Actually Do to the Org Chart
Agents rarely shrink payrolls. They convert doing-work into checking-work, and winning org charts are redesigned around that conversion, not headcount.
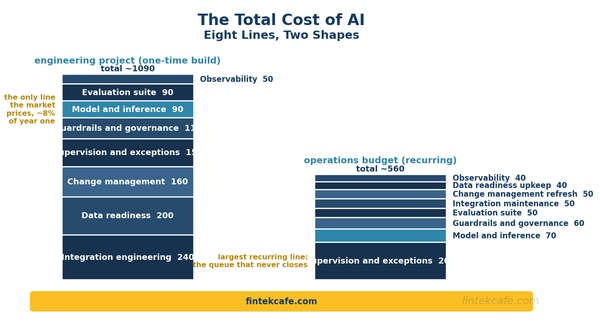
The Total Cost of AI: A Framework for Pricing an AI Initiative End to End
An eight-line total cost of ownership framework for enterprise AI, with a worked example, realistic cost shares, and a build-buy-wait decision table.

AI Governance: How to Build an AI Policy That Actually Gets Followed
Why AI policies fail as documents and work as controls: a three-tier governance model, ownership patterns, EU AI Act duties, and metrics that matter.