Prompt Engineering for Business: A Practical Guide for Non-Engineers
The difference between a mediocre AI output and an exceptional one is almost never the model. It is the prompt.
An operations manager who writes "summarize this report" and an operations manager who writes "extract the three most important operational risks from this report, rank them by potential revenue impact, and suggest one mitigation action for each" are using the same technology. They are getting dramatically different results.
This gap is prompt engineering: the skill of giving AI models clear, structured instructions that produce useful output. And despite the name, it is not engineering at all. It is closer to writing a good brief for a consultant - specifying what you want, providing relevant context, and defining what "good" looks like.
This guide covers the practical techniques that produce the best results for business tasks. No code required. Every example uses plain English. The techniques apply to Claude, ChatGPT, Gemini, and any large language model (LLM) you are likely to use.
Why Prompt Engineering Matters for Business
Large language models are probabilistic. They generate the most likely continuation of your input based on their training data. A vague input produces a vague output. A specific, well-structured input produces a specific, well-structured output.
The business implication is significant. Organizations deploying AI for analysis, content creation, customer support, or operational tasks see wildly different results based on how prompts are written. Accenture's 2025 analysis of enterprise AI deployments found that prompt quality was the single largest variable in output quality - more impactful than model choice, fine-tuning, or data quality.
The good news: prompt engineering is a learnable skill, and the core techniques can be applied by anyone who can write clearly. The learning curve is days, not months.
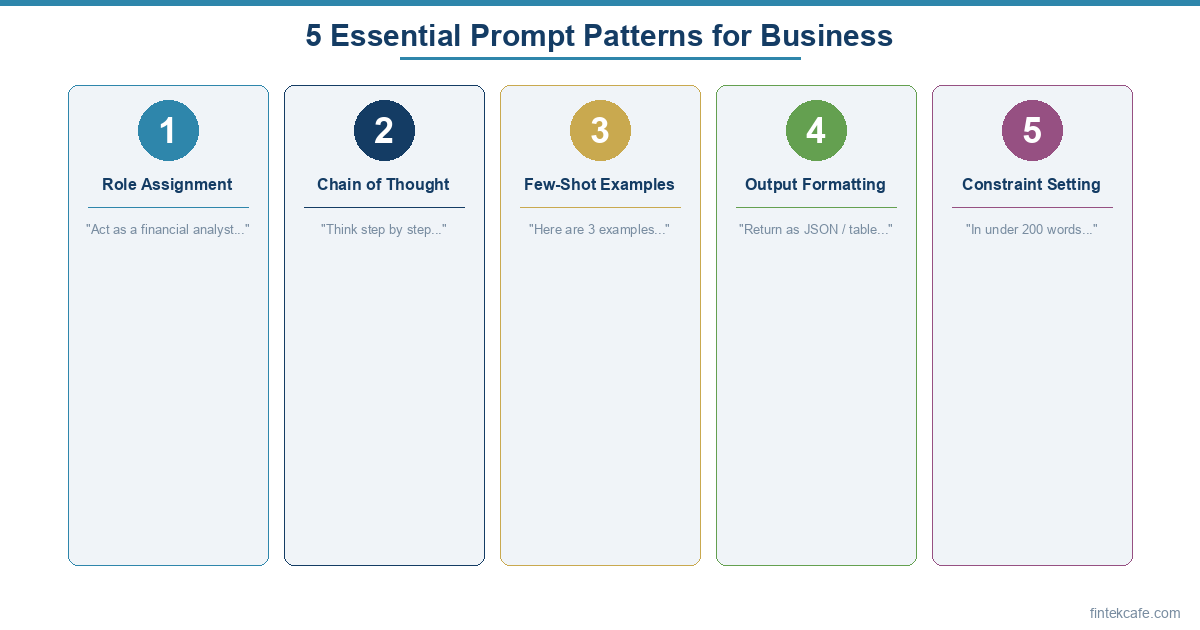
The Five Core Techniques
1. Be Specific About What You Want
The most common prompting mistake is ambiguity. "Analyze this data" is ambiguous. The model does not know what kind of analysis you want, what format, what depth, or what your goals are.
Weak prompt:
Analyze our Q1 sales data.
Strong prompt:
Analyze our Q1 2026 sales data (attached). Specifically:
- Identify the top 3 product categories by revenue growth rate (not absolute revenue).
- Flag any category where growth decelerated compared to Q4 2025.
- For each flagged category, suggest one hypothesis for the deceleration.
Present the results as a table with columns: Category, Q4 Growth Rate, Q1 Growth Rate, Delta, Hypothesis.
The strong prompt specifies the analysis type, the comparison period, the output format, and the number of items. The model knows exactly what to deliver.
The rule: If you could give the same prompt to two different analysts and get substantially different outputs, your prompt is too vague.
2. Assign a Role
Telling the model who it is changes how it responds. A "financial analyst" produces different analysis than a "marketing strategist" even when given the same data. Role assignment activates relevant domain knowledge and communication patterns.
Without role:
What should we consider before launching in Japan?
With role:
You are a market entry strategist with deep experience in Asia-Pacific expansion for SaaS companies. We are a B2B fintech company (100 employees, 15M annual revenue) considering launching in Japan. What are the top 5 considerations we should evaluate before committing, ranked by risk level? For each, include a one-sentence explanation of why it matters specifically for fintech in Japan.
The role provides context that shapes the entire response. The model draws on different knowledge when acting as a market entry strategist versus a general assistant.
Effective roles for business use:
- "You are a CFO reviewing this budget for hidden risks"
- "You are an operations consultant identifying process bottlenecks"
- "You are a competitive intelligence analyst evaluating a market entrant"
- "You are a technical writer creating documentation for a non-technical audience"
- "You are a regulatory compliance officer reviewing this product feature"
3. Provide Context and Constraints
Models perform best when they understand the background, the audience, and the boundaries. Context is the raw material that separates a generic answer from a useful one.
Essential context to include:
- Background: What is the situation? What decisions need to be made?
- Audience: Who will read the output? What is their expertise level?
- Constraints: What should the model avoid? What length, format, or tone?
- Examples: What does a good output look like?
Weak prompt:
Write a summary of our product for the website.
Strong prompt:
Write a product summary for our website homepage. Context:
- Product: Cloud-based accounts payable automation for mid-market companies (200-2,000 employees)
- Key differentiator: We process invoices 4x faster than competitors because of our proprietary OCR plus human verification workflow
- Target audience: CFOs and controllers who are frustrated with manual AP processes
- Tone: Professional but not corporate. Confident but not salesy.
- Length: 150-200 words
- Must mention: time savings, accuracy, and integration with major ERPs (SAP, Oracle, NetSuite)
- Must NOT mention: pricing, specific customer names, or competitor comparisons
Every constraint eliminates an axis of ambiguity. The model does not have to guess; it can focus on quality within the defined parameters.
4. Use Chain-of-Thought Prompting
Chain-of-thought (CoT) prompting asks the model to think through a problem step by step before providing an answer. This technique dramatically improves accuracy on complex reasoning tasks.
Without chain-of-thought:
Should we raise prices by 10%?
With chain-of-thought:
We are considering raising prices by 10% across our SaaS product line. Before recommending whether to proceed:
- First, list the direct financial effects (revenue per customer, potential churn).
- Then, analyze the competitive implications (how are competitors priced?).
- Next, consider customer segment differences (which segments are price-sensitive vs. value-driven?).
- Finally, provide a recommendation with the specific conditions under which a 10% increase is advisable and conditions under which it is not.
The step-by-step structure forces the model to consider multiple dimensions before reaching a conclusion. Without it, the model tends to jump to an answer that may be confident but shallow.
When to use chain-of-thought:
- Financial analysis with multiple variables
- Strategic decisions with trade-offs
- Diagnosing root causes of problems
- Comparing options with different strengths
- Any task where "it depends" is the honest first answer
5. Use Few-Shot Examples
Showing the model examples of the desired output is one of the most effective techniques. Instead of describing what you want, demonstrate it.
Without examples:
Categorize these customer support tickets by urgency.
With few-shot examples:
Categorize each customer support ticket as HIGH, MEDIUM, or LOW urgency using these definitions and examples:
HIGH: Service is down or data is at risk. Customer cannot use the product.
Example: "Our dashboard has been showing a blank screen for all users since 9am. We can't access any reports."MEDIUM: Feature is degraded but workaround exists. Customer is inconvenienced.
Example: "The export to CSV function keeps timing out on large datasets. We can export smaller batches but it takes much longer."LOW: Question, feature request, or cosmetic issue. No impact on core functionality.
Example: "Is there a way to change the color scheme of the dashboard? The default is hard to read."Now categorize these tickets:
[tickets]
Few-shot examples calibrate the model's judgment. Without them, "urgency" is subjective. With them, the model applies your organization's specific definition of urgency consistently.
Advanced Techniques for Business Users
Structured Output Formatting
Requesting specific output formats makes results immediately usable. Models can produce tables, bullet points, JSON, numbered lists, and multi-section documents on request.
For a competitive analysis:
Compare these three vendors using the following table format:
Criteria Vendor A Vendor B Vendor C Winner Include these criteria: pricing, integration options, customer support quality, scalability, and security certifications. For each cell, provide a 1-2 sentence assessment.
For a meeting summary:
Summarize this meeting transcript in the following structure:
Decisions Made: (numbered list)
Action Items: (who, what, by when)
Open Questions: (issues that need follow-up)
Key Discussion Points: (3-5 bullet points)
Structured formatting is not just cosmetic. It forces the model to organize information into the categories you care about rather than producing an unstructured narrative you need to parse.
Iterative Refinement
The best outputs often come from multi-turn conversations, not single prompts. Use follow-up prompts to refine.
Initial prompt: "Draft a project proposal for migrating our CRM from Salesforce to HubSpot."
Refinement 1: "Good structure. Now add a risk section that covers data migration risks, user adoption risks, and integration risks with our existing tools."
Refinement 2: "The timeline section is too optimistic. Revise it assuming the data migration will take 3x longer than initially estimated, based on the data quality issues we discussed."
Refinement 3: "Rewrite the executive summary to lead with the cost savings rather than the feature comparison. The CFO is our primary audience for approval."
Each refinement builds on the previous output without starting over. This is more efficient than trying to craft a perfect single prompt.
Prompt Templates for Recurring Tasks
If you perform the same type of analysis regularly, create a prompt template. Templates standardize quality and save time.
Weekly competitive monitoring template:
You are a competitive intelligence analyst. Analyze the following developments from the past week for [COMPETITOR NAME]:
[PASTE NEWS/UPDATES]
Provide:
- What happened: One-paragraph factual summary
- Why it matters to us: Impact on our market position (1-3 sentences)
- Recommended response: What, if anything, should we do? (specific action or "no action needed")
- Confidence level: How certain is this assessment? (high/medium/low and why)
Customer feedback analysis template:
Analyze the following batch of customer feedback. Categorize each piece into:
- Feature Request (something we don't offer)
- Bug Report (something broken)
- Churn Risk (expressing frustration or mentioning competitors)
- Positive Signal (expressing satisfaction or recommending us)
For each category, identify the top 3 themes by frequency. For Churn Risk items, flag any that mention a specific competitor by name.
[PASTE FEEDBACK]
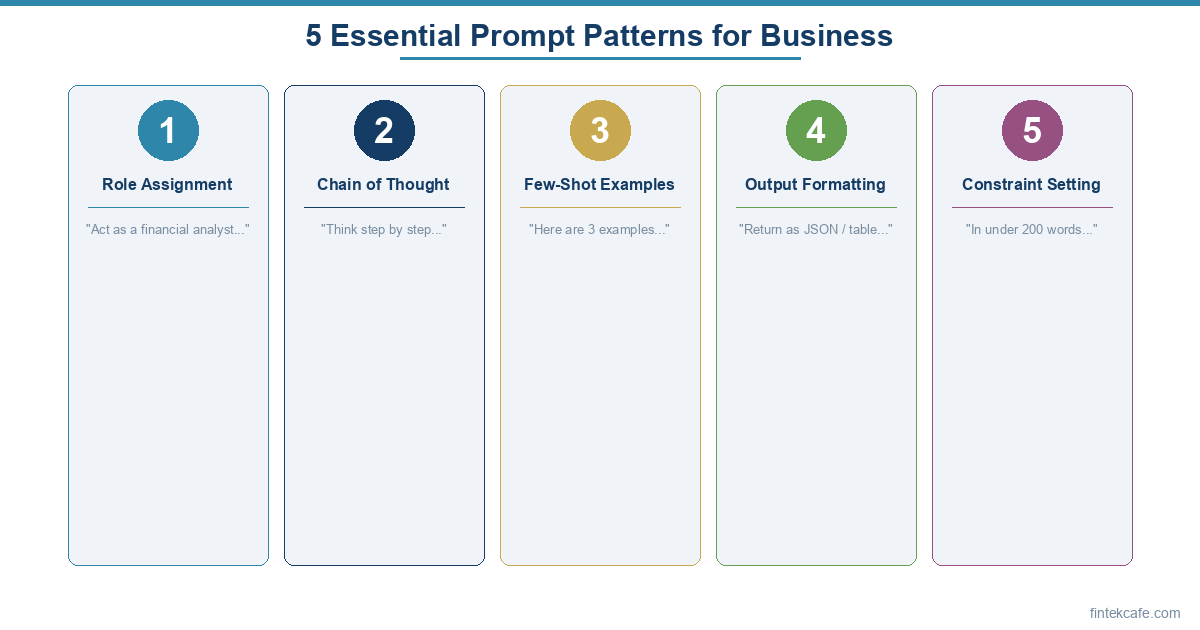
Common Mistakes and How to Avoid Them

Mistake 1: Treating AI Output as Final
AI output is a first draft, not a finished product. Models can produce confident-sounding text that contains factual errors, outdated information, or reasoning gaps. Every output should be reviewed by someone with domain knowledge before being used in decisions, shared externally, or presented to stakeholders.
The best mental model: treat AI output like work from a talented junior hire. Fast, often impressive, but requires review and judgment from someone who understands the context.
Mistake 2: Overloading a Single Prompt
Asking a model to do too many things at once degrades quality on each sub-task. If you need a market analysis, a competitive comparison, and a financial projection, run them as three separate prompts rather than one mega-prompt. Each will be stronger individually.
Rule of thumb: If your prompt has more than three distinct objectives, split it into multiple prompts.
Mistake 3: Not Providing Enough Context
Models do not know what you know. They do not know your company's strategy, your competitive landscape, your constraints, or your priorities unless you tell them. The more relevant context you provide, the better the output.
A common pattern: users provide raw data and ask for analysis but do not explain what they are trying to decide. Adding "We are trying to decide whether to expand into Europe or double down on the US market" transforms a generic analysis into a decision-oriented one.
Mistake 4: Asking for Opinions Instead of Analysis
"What should we do?" often produces generic advice. "What are the arguments for and against each option, and what data would help us decide?" produces analytical frameworks you can apply to your specific situation.
Models are most useful as analytical tools, not decision-makers. Ask them to structure information, identify trade-offs, and surface considerations you might have missed. Keep the decision with humans.
Mistake 5: Ignoring Model Limitations
Models have knowledge cutoffs and may not have current information. They cannot access your internal systems unless you provide the data. They may confidently present incorrect information. They perform better on well-documented topics than niche or proprietary domains.
Always tell the model what year it is and what it does not know. "Note: the model's training data may not include developments after [date]. Flag any claims that depend on very recent information."
Practical Use Cases by Business Function
Finance and Accounting
- Variance analysis (provide actuals vs. budget data, ask for explanations of significant variances)
- Financial memo drafting (board presentations, investment cases)
- Policy review (compare a contract against standard terms, flag deviations)
- Scenario modeling narratives (describe the assumptions and have the model articulate the implications)
Marketing
- Competitive positioning analysis (provide competitor messaging, ask for differentiation opportunities)
- Content brief creation (define audience, objectives, and constraints for writers)
- Campaign performance analysis (provide metrics, ask for insights and optimization recommendations)
- Customer persona development (provide survey data or interview notes, ask for structured personas)
Operations
- Process documentation (describe a workflow, have the model create an SOP)
- Root cause analysis (describe an incident, ask for structured RCA using the 5 Whys framework)
- Vendor evaluation (provide RFP responses, ask for a structured comparison matrix)
- Meeting preparation (provide agenda and background docs, ask for key questions to raise)
Human Resources
- Job description drafting (provide role requirements, company culture, and compensation context)
- Interview question development (provide role requirements, ask for behavioral and technical questions)
- Policy comparison (provide two policies, ask for a structured diff highlighting material differences)
- Employee communication drafting (provide context and key messages, ask for audience-appropriate language)
Strategy and Executive
- Board memo drafting (provide the situation, recommendation, and evidence)
- Market sizing (provide assumptions and data points, ask for a bottom-up market size estimate)
- Risk assessment (describe a strategic initiative, ask for a structured risk register)
- Decision framework creation (describe a decision, ask for evaluation criteria and a scoring method)
Building Prompt Competency Across Your Organization
Prompt engineering is not a specialist skill. It is a communication skill that every knowledge worker should develop. Organizations that invest in prompt literacy across their teams see compounding returns as more people use AI tools effectively.
Start with a prompt library
Create a shared repository of tested prompts for common tasks in your organization. When someone develops a prompt that consistently produces good results, document it. A simple shared document or wiki page works. Label each prompt with the task it serves, the context it requires, and example outputs.
Establish quality standards
Define what "good" looks like for AI-assisted work in your organization. Some teams require that any AI-generated analysis include a "verification needed" section flagging claims that should be fact-checked. Others require that AI drafts be reviewed by a domain expert before sharing externally. Whatever the standard, make it explicit.
Measure the impact
Track time savings and quality improvements. If a financial analyst spends 4 hours building a market analysis and can produce a comparable analysis in 45 minutes with AI assistance (including review time), that is a measurable productivity gain. Aggregate these gains to build the business case for further AI investment.
Key Takeaways
- Prompt quality is the single largest variable in AI output quality - more impactful than model choice or fine-tuning for most business tasks.
- Five core techniques cover 90% of business use cases: be specific, assign a role, provide context, use chain-of-thought reasoning, and give examples.
- Structured output formatting makes results immediately actionable - request tables, categorized lists, and multi-section formats rather than narrative text.
- Iterative refinement beats the perfect first prompt - treat AI interaction as a conversation where each turn improves the output.
- AI output is a first draft, not a finished product - always review with domain expertise before acting on or sharing results.
- Prompt competency is an organizational capability - invest in shared prompt libraries, quality standards, and training to compound returns across teams.
Frequently Asked Questions

Do I need to learn to code to use prompt engineering effectively?
No. The techniques described in this guide use plain English and work across all major language models (Claude, ChatGPT, Gemini). Prompt engineering for business tasks is a communication skill, not a programming skill. Some advanced applications - like building automated prompt pipelines or integrating AI into software products - do require coding, but those are software engineering tasks, not everyday business use.
Which AI model is best for business prompt engineering?
The differences between top-tier models (Claude, GPT-4, Gemini) are smaller than the differences between a well-crafted prompt and a poorly crafted one. For most business tasks - analysis, writing, summarization, categorization - any of the leading models will produce good results with good prompts. Choose based on your organization's existing tools, data privacy requirements, and pricing. Claude and GPT-4 tend to perform well on nuanced analysis. Gemini integrates deeply with Google Workspace.
How do you handle confidential data in prompts?
This is a legitimate concern. Enterprise versions of AI tools (Claude for Enterprise, ChatGPT Enterprise, Azure OpenAI) provide contractual guarantees that user data is not used for model training. For highly sensitive data, consider on-premises or virtual private cloud deployments. As a practical matter: do not paste customer personal data, financial records, or trade secrets into consumer-tier AI tools. Use enterprise-grade tools with appropriate data handling agreements.
How long should a prompt be?
As long as it needs to be. A simple question might need 2-3 sentences. A complex analysis prompt with role assignment, context, constraints, examples, and output format might be 500-800 words. Longer prompts are not wasteful if every sentence adds useful context or constraints. The cost of a verbose prompt (a few extra cents in API tokens) is trivial compared to the cost of re-doing work because the output missed the mark.
Can prompt engineering replace domain expertise?
No. Prompt engineering makes domain expertise more productive but does not substitute for it. A financial analyst who uses AI to accelerate variance analysis still needs to know what variances are meaningful and what the numbers mean in business context. A marketing strategist who uses AI to draft competitive positioning still needs to understand the market deeply enough to evaluate whether the output is accurate. AI amplifies expertise; it does not create it.
How quickly does prompt engineering skill develop?
Most business professionals see significant improvement within a few hours of deliberate practice. The core concepts - specificity, role assignment, context, chain-of-thought, and examples - can be learned in a single sitting. The refinement comes from practice with real tasks. After two to three weeks of regular use, most users develop an intuition for what prompts will work well and what needs revision. Creating a personal library of effective prompts accelerates the learning process.
Internal Link Suggestions
- What Are AI Agents? A Complete Guide for Business Leaders - Prompt engineering is the foundation for working with AI agents, which take prompts and execute multi-step tasks autonomously.
- How to Build an AI Strategy: A Step-by-Step Framework - Prompt competency across your organization is a key component of any AI strategy implementation.
- How to Present an AI Strategy to Your Board of Directors - The prompt engineering techniques in this guide can help prepare board-ready AI analysis and presentations.
Related Articles
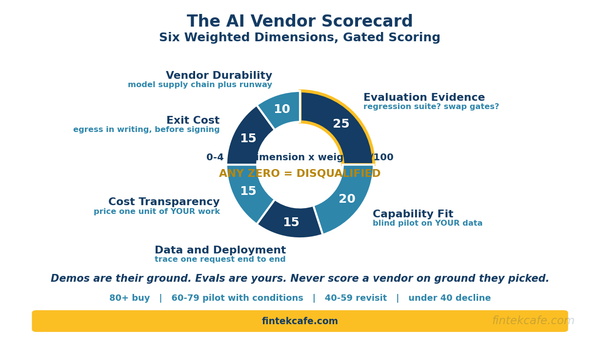
The AI Vendor Evaluation Framework: How to Score AI Products Before You Buy
A six-dimension scoring framework for evaluating AI vendors, with weights, pass/fail gate questions, and a matrix a buyer can apply in a live meeting.

LLM Observability: How to Monitor AI Systems in Production
Why classic APM misses LLM failures, the four signal layers of LLM observability, what to alert on, and how production traces feed the evaluation loop.

Evals Are the Moat: Why AI Products Defend on Evaluation, Not Models
The durable moat in applied AI is not the model. It is the eval suite: the one asset competitors cannot rent, and the one due diligence should price.