Event-Driven Architecture: When Async Messaging Is Worth the Complexity

Key Takeaways
- Event-driven architecture trades the simplicity of a direct request-and-response call for the flexibility of asynchronous messaging through a broker. The trade is real and it cuts both ways: decoupling, load buffering, replayable history, and fan-out on one side, and eventual consistency, harder debugging, schema evolution, and the operational weight of a broker on the other.
- Most teams that adopt event-driven architecture inherit a distributed-systems tax they did not price in. The pattern is sold as the default for scale, so teams reach for it before they have the problems it solves, and end up paying the complexity cost without collecting the benefit.
- The patterns are not interchangeable. Event notification, event-carried state transfer, event sourcing, and CQRS sit on a ladder of increasing power and increasing cost, and choosing a heavier pattern than the problem requires is the most common and most expensive mistake in this space.
- For a large share of systems, a request-response service or a single durable queue is the better answer, and reaching for a full event-streaming platform is premature. The question is not whether events are modern. It is whether the workload has the specific shape, many independent consumers, spiky load, a need for replayable history, that the architecture is built for.
- Readiness is organizational as much as technical. Event-driven systems demand schema governance, distributed-tracing observability, and teams comfortable reasoning about eventual consistency. An organization without those capabilities will build a fragile system regardless of how good the broker is.
The Default That Is Usually the Wrong Default
Walk into almost any architecture discussion about scaling a system and someone will propose going event-driven. The pattern has become the reflexive answer to growth, the assumed endpoint of any serious architecture, the thing mature systems are supposed to do. Conference talks celebrate it, vendors sell platforms for it, and engineers reach for it as a signal of sophistication. And a large fraction of the teams that adopt it end up with a system that is harder to build, harder to debug, and harder to operate than the one they replaced, without the benefits that were supposed to justify the change.
The problem is not that event-driven architecture is bad. It is excellent for the workloads it fits. The problem is that it is sold as a default rather than as a trade, and defaults get adopted without anyone pricing the cost. Asynchronous messaging through a broker is a genuine architectural commitment that introduces eventual consistency, distributed debugging, schema-evolution problems, and a piece of critical infrastructure that has to be operated around the clock. Teams that adopt it to handle a load they do not yet have, or to decouple services that were not actually coupled, pay all of that cost and collect none of the benefit.
This article separates the real wins from the real costs, lays out the core patterns on the ladder from lightest to heaviest, identifies when a request-response service or a simple queue is the better answer, works through the broker choice between a full streaming platform and a lighter message queue, and names the organizational signals that indicate a team is actually ready. A decision matrix maps workload shape to the right pattern, so the choice is made on the shape of the problem rather than on the prestige of the architecture.

What Event-Driven Architecture Actually Is
Event-driven architecture is a design where services communicate by producing and consuming events through a message broker, rather than by calling each other directly. A service that does something publishes an event, a statement that something happened, to the broker, and any service that cares subscribes and reacts. The producer does not know or wait for the consumers. That decoupling is the entire point, and every benefit and every cost flows from it.
The contrast is with request-response, where a service calls another service directly and waits for the answer. In request-response, the caller knows the callee, the interaction is synchronous, and consistency is immediate: when the call returns, the work is done. In event-driven, the producer fires an event and moves on, the consumers process it whenever they get to it, and the system is eventually consistent: the work will be done, but not necessarily by the time the producer continues.
The broker is the piece of infrastructure in the middle, and it is not free. It receives events, stores them, and delivers them to consumers, and it must be highly available, because if the broker is down, the services that depend on it cannot communicate. Adopting event-driven architecture means adopting the broker as a critical system that has to be sized, monitored, secured, and operated, which is a standing operational commitment many teams underestimate when they focus on the elegant decoupling and ignore the infrastructure that enables it.
The Real Wins
Event-driven architecture earns its complexity in four specific situations, and naming them precisely is what keeps the pattern from being adopted for the wrong reasons.
Decoupling many consumers from one producer. When a single event, an order placed, a user signed up, needs to trigger many independent reactions, send a confirmation, update inventory, notify analytics, start fulfillment, doing that with direct calls means the producer has to know about and call every consumer, and adding a new reaction means changing the producer. With events, the producer publishes once and any number of consumers subscribe independently. New consumers are added without touching the producer. This fan-out is the cleanest win.
Buffering load spikes. A broker absorbs bursts. When traffic spikes faster than consumers can process it, the events queue in the broker and consumers work through them at their own pace, instead of the spike overwhelming a synchronous service and cascading into failures. For workloads with uneven, bursty load, this buffering is a genuine resilience benefit that request-response cannot match.
Replayable history. A streaming platform that retains events lets consumers replay the history: a new consumer can process everything that ever happened, and a consumer that had a bug can be fixed and re-run over the past events. This turns the event log into a durable record of what occurred, which is powerful for analytics, auditing, and recovery, and impossible in a pure request-response system where the interactions leave no replayable trace.
Independent scaling and deployment. Because producers and consumers are decoupled, they scale and deploy independently. A slow consumer can be scaled up without touching the producer, and a consumer can be deployed without coordinating with the rest of the system. This is the same independence that justifies a microservices split in the first place, and the trade-offs are the same ones laid out in the comparison of microservices versus monoliths: real benefits that are only worth their cost above a certain scale and organizational size.
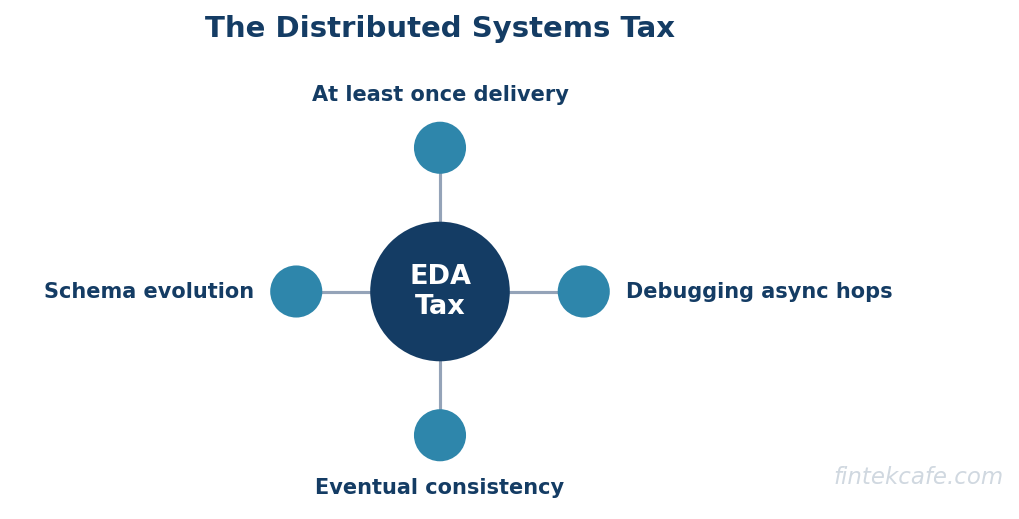
The Distributed-Systems Tax
Every one of those wins is paid for, and the bill is the distributed-systems tax. Teams that adopt event-driven architecture without budgeting for these costs are the ones who regret it.
Eventual consistency. Because consumers process events asynchronously, the system is not immediately consistent. After an order is placed, there is a window where the order exists but the inventory has not yet been decremented and the confirmation has not yet been sent. The application has to be designed to tolerate that window, and the user experience has to account for it. Teams accustomed to immediate consistency frequently underestimate how much logic this complicates, from showing a user the current state to preventing double-processing.
Debugging across async hops. In request-response, a request has a single call stack you can follow. In event-driven, a single business action becomes a chain of events hopping between services with no shared call stack, and tracing what happened requires correlating events across multiple systems and time. Without distributed tracing, debugging an event-driven system is archaeology. This observability requirement is not optional, and it is a standing cost.
The exactly-once delusion. A persistent source of pain is the belief that the broker delivers each event exactly once. In practice, distributed messaging delivers at-least-once, meaning consumers will sometimes see the same event twice, and the application must be designed to handle duplicates safely through idempotent processing. Teams that assume exactly-once delivery build systems that double-charge, double-ship, and double-count under failure conditions, and they discover it in production.
Schema evolution. Events are a contract between producers and consumers, and that contract changes over time. When a producer changes the shape of an event, every consumer that reads it is affected, and because the consumers are decoupled and deployed independently, they cannot all be updated at once. Managing this requires schema governance, versioning, and compatibility rules, and a team without that discipline will break consumers every time an event changes.
Operational weight. The broker is critical infrastructure that has to be run. A full streaming platform in particular is a substantial operational commitment: it must be sized, partitioned, monitored, secured, and recovered, and getting that wrong takes down every service that depends on it. This operational burden is exactly the kind of platform responsibility that pushes organizations toward dedicated internal platform capabilities, the subject of the analysis of platform engineering and internal developer platforms.
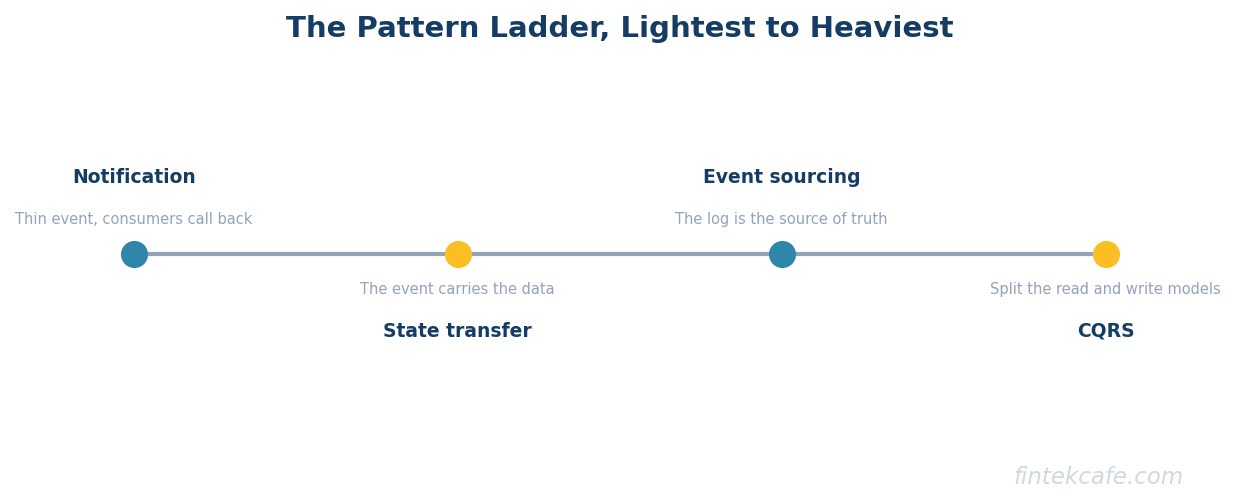
The Core Patterns, Lightest to Heaviest
Event-driven architecture is not one pattern. It is a ladder of patterns with increasing power and increasing cost, and the central skill is climbing only as high as the problem requires.
Event notification is the lightest. A service publishes a thin event that says something happened, a simple announcement with an identifier, and consumers that care call back to get the details they need. It is simple and keeps events small, at the cost of those callback calls. This handles a large share of real decoupling needs.
Event-carried state transfer puts the relevant data inside the event itself, so consumers do not need to call back. This removes the callback dependency and lets consumers be fully autonomous, at the cost of larger events and data duplication across consumers. It fits when consumers need to operate without depending on the producer being available.
Event sourcing is heavier. Instead of storing current state and emitting events about changes, the system stores the sequence of events as the source of truth and derives current state by replaying them. This gives a complete, replayable audit trail of everything that ever happened, at the substantial cost of complexity: rebuilding state, handling schema changes across the entire history, and reasoning about a system whose truth is a log rather than a table. It is powerful and frequently over-adopted.
CQRS, command-query responsibility segregation, separates the write model from the read model, often pairing with event sourcing so writes append events and reads come from separately maintained views. It fits when read and write patterns are so different that one model cannot serve both well, and it adds the cost of maintaining and synchronizing two models with the eventual-consistency gap between them.
The discipline is to recognize that each rung up the ladder solves a harder problem and charges more for it. Most systems need event notification or event-carried state transfer. Event sourcing and CQRS are specialized tools for specific problems, and adopting them because they sound advanced is how teams manufacture complexity they then have to maintain forever.
When a Monolith or a Simple Queue Wins
The most useful question is often not which event pattern to use, but whether to use one at all. Two simpler answers beat event-driven architecture for a large share of systems.
A request-response service, including a well-structured monolith, wins when the interactions are naturally synchronous, consistency needs to be immediate, and the system does not have many independent consumers of the same events. If a user action needs an immediate, consistent answer and only one thing needs to happen as a result, a direct call is simpler, faster to build, far easier to debug, and immediately consistent. Reaching for events here adds eventual consistency and distributed debugging to a problem that had neither, and the modern reality that a capable relational database can carry far more load than teams assume, the argument that Postgres is quietly eating the database stack, removes much of the scaling pressure that used to justify going distributed early.
A single durable message queue, rather than a full streaming platform, wins when the need is simply to process work asynchronously, send this email, resize this image, without the producer waiting, and there is one logical consumer of each message. A queue gives asynchronous processing and load buffering with a fraction of the operational weight of a streaming platform. Many teams adopt a heavy event-streaming platform when a simple queue would have met the actual requirement at a small fraction of the complexity, paying for replayable multi-consumer streaming they never use.
The signal that you have outgrown these simpler answers is concrete: you have multiple independent consumers that need the same events, you need to buffer genuinely spiky load, or you need a replayable history for audit or recovery. Absent those, the simpler architecture is not a compromise. It is the correct choice.
Kafka or a Lighter Broker
When events are genuinely the right model, the next decision is what broker to run, and it usually comes down to a full streaming platform versus a lighter message queue or broker. The distinction that matters is whether you need a durable, replayable log of events or just reliable delivery of messages.
A streaming platform retains events in an ordered, partitioned log that consumers read at their own pace and can replay from any point. This is what you need for replayable history, many consumers reading the same stream independently, and high-throughput event streaming. It is also the heavier operational commitment: partitions, retention, consumer-group management, and the expertise to run it reliably.
A lighter message broker or queue focuses on delivering messages to consumers and removing them once processed. It is simpler to operate and entirely sufficient when you need asynchronous work distribution and do not need to retain or replay a log of events. Choosing the streaming platform when you only need a queue means taking on the heavier operational burden for capabilities you will not use, and choosing the queue when you genuinely need replay and multi-consumer streaming means hitting a wall later. The honest version of this decision matches the broker to the requirement rather than to the broker's popularity, the same discipline that governs whether you actually need heavier infrastructure like a service mesh or whether it is complexity bought ahead of need.
Decision Matrix by Workload
The choice resolves cleanly when framed by workload shape rather than by which architecture sounds most modern.
| Workload shape | Best fit | Why |
|---|---|---|
| Synchronous action needing an immediate, consistent answer | Request-response service | Simpler, immediately consistent, easy to debug |
| Async work with one consumer per message | Single durable queue | Async and buffered without streaming weight |
| One event, many independent reactions | Event notification | Clean fan-out, producer stays unaware of consumers |
| Consumers must operate without calling back | Event-carried state transfer | Autonomy at the cost of larger events |
| Full audit trail and replay of all changes | Event sourcing | Replayable log as source of truth, high complexity |
| Read and write patterns fundamentally different | CQRS | Separate models, accept eventual consistency |
| Many consumers, spiky load, replay needed | Streaming platform | The workload the platform is actually built for |
The pattern is that the lighter the workload's coupling and consistency needs, the lighter the right architecture. The matrix climbs from request-response at the simple end to a streaming platform at the demanding end, and the cost climbs with it. The mistake is starting at the demanding end because it is where the prestige is, rather than at the end the workload actually occupies.
Organizational Readiness
Event-driven architecture is as much an organizational commitment as a technical one, and the readiness signals are concrete. An organization is ready when it has schema governance in place, because events are contracts and uncontrolled schema changes break consumers. It is ready when it has distributed-tracing observability, because debugging async flows without it is intractable. It is ready when its engineers are comfortable reasoning about eventual consistency, idempotency, and at-least-once delivery, because the architecture demands that reasoning everywhere. And it is ready when it has the platform capacity to operate a broker as critical infrastructure rather than treating it as something that runs itself.
An organization missing those capabilities will build a fragile event-driven system no matter how good the broker is, because the fragility comes from the gaps in governance, observability, and operational maturity, not from the technology. The evidence consistently shows that the teams who succeed with event-driven architecture are the ones who adopted it to solve a problem they actually had, climbed only as high up the pattern ladder as that problem required, and had the organizational discipline to manage schemas, trace flows, and operate the broker. The teams who struggle are the ones who adopted it because it was the default, and discovered the distributed-systems tax only after the bill came due.
FAQ
What is event-driven architecture?
Event-driven architecture is a design where services communicate by producing and consuming events through a message broker rather than calling each other directly. A service publishes an event stating that something happened, and any service that cares subscribes and reacts independently, without the producer waiting. This decouples producers from consumers and enables fan-out, load buffering, and replayable history, at the cost of eventual consistency, harder debugging, and the operational weight of running a broker.
When should you use Kafka versus a simpler message queue?
Use a streaming platform like Kafka when you need a durable, replayable log of events, when many independent consumers read the same stream, or when you have high-throughput event streaming. Use a lighter message queue when you simply need to process work asynchronously with one consumer per message and do not need to retain or replay events. Choosing a streaming platform when a queue would do means taking on heavy operational burden for capabilities you will not use.
What is the difference between event sourcing and CQRS?
Event sourcing stores the sequence of events as the source of truth and derives current state by replaying them, giving a complete replayable audit trail. CQRS, command-query responsibility segregation, separates the write model from the read model so each can be optimized independently. They are often paired, with writes appending events and reads served from separately maintained views, but they solve different problems and each adds significant complexity, so neither should be adopted unless the specific problem it addresses is actually present.
Why is exactly-once delivery a myth in event-driven systems?
Distributed messaging systems deliver at-least-once, meaning a consumer will sometimes receive the same event more than once under failure and retry conditions. True exactly-once delivery across distributed systems is generally not achievable, so the practical approach is to make consumers idempotent, designing them so processing the same event twice has the same effect as processing it once. Teams that assume exactly-once delivery build systems that double-charge or double-ship when duplicates inevitably occur.
When is a monolith or simple queue better than event-driven architecture?
A request-response service or well-structured monolith is better when interactions are naturally synchronous, consistency must be immediate, and there are not many independent consumers of the same events. A single durable queue is better when you just need asynchronous processing with one consumer per message. Event-driven architecture only earns its complexity when you have multiple independent consumers of the same events, genuinely spiky load to buffer, or a need for replayable history; absent those, the simpler choice is the correct one.
Related reading on FinTekCafe
Related Articles

Legacy System Modernization: Strategies That Do Not Blow Up
A leader's guide to legacy modernization: the real triggers, the strategy ladder with honest costs, the strangler-fig default, and what AI changes.

Sovereign Cloud: The Compliance Product Hyperscalers Love to Sell
Sovereign cloud is a pricing tier more than a technology. What the offerings deliver versus imply, who needs which layer, and when the premium is worth paying.

Disaster Recovery Planning: What Technology Leaders Actually Need
Disaster recovery for technology leaders: RTO and RPO tiering, the four DR architecture patterns with honest cost multiples, testing, and cloud-era failures.