Service Mesh Explained: When You Actually Need One (And When It's Just Complexity Tax)

Key Takeaways
- Service mesh solves three real problems: mutual TLS between services, fine-grained traffic control, and consistent observability. Below a certain scale, ingress and service discovery solve them well enough.
- The honest threshold for service mesh adoption is roughly 50 production services with regulated workloads. Below that line, the operational cost outweighs the benefits in most cases.
- Istio, Linkerd, and Cilium represent three philosophies. The choice matters more for operational team capacity than for raw feature comparison.
- Operational cost is the single most underestimated factor. A production mesh consumes between half and one full senior engineer per cluster, not counting upgrade cycles.
- Ripping out a mesh is harder than installing one. The decision to adopt should be made with the same rigor as a database migration, not as a platform team experiment.
Why Service Mesh Became the Most Over-Bought Infrastructure of 2021 to 2024
The Kubernetes ecosystem created an unusual market dynamic. Once a platform team had standardized on Kubernetes, the next conversation was almost always about service mesh. The pitch was compelling: zero-trust networking, retries and timeouts, deep observability, all without changing application code. Conference keynotes, vendor demos, and consulting recommendations converged on the same message. Adoption surged.
Five years later, the picture is more complicated. A meaningful share of organizations that adopted a mesh between 2020 and 2023 are now either ripping it out, scaling it back, or running it without using most of its features. The pattern is consistent enough to call out plainly. Service mesh was over-bought, and the cost of that decision is showing up now in platform team burnout, infrastructure budgets, and slow release cycles.
This article is not an argument against service mesh. The technology genuinely solves real problems for organizations at the right scale and with the right compliance requirements. The argument is for honesty about when those conditions actually apply.
What a Service Mesh Actually Does
A service mesh is a dedicated infrastructure layer that handles service-to-service communication inside a distributed system. The mesh consists of a data plane, typically a sidecar proxy running next to every service instance, and a control plane that configures the proxies. Traffic between services flows through the proxies, which apply policies for security, routing, and observability.
The three problems a mesh solves are concrete and worth understanding before any adoption discussion.
Mutual TLS Between Services
In a regulated environment, every service-to-service connection must be authenticated and encrypted. Doing this in application code means every team implements certificate management, rotation, and validation correctly, every time. A mesh handles this in the proxy layer, applying mTLS uniformly across the fleet without application changes. For organizations subject to PCI DSS, HIPAA, or similar frameworks operating across hundreds of services, this is the single strongest argument for a mesh.
Fine-Grained Traffic Shaping
Canary deployments, blue-green rollouts, header-based routing, fault injection, and traffic mirroring all become trivial with a mesh. A platform team can ship a new version to one percent of traffic, observe the impact, and roll back without changes to load balancer configuration. For teams running mature continuous delivery pipelines across many services, this capability removes a real operational burden.
Consistent Observability
A mesh produces standardized request-level telemetry: latency distributions, error rates, traffic volume, and dependency graphs. Because the proxy sees every call, the data is uniform across services regardless of language or framework. This is genuinely useful when teams use different stacks and want a single source of truth for service-level indicators.
Where Ingress and Service Discovery Are Enough
The honest comparison is not between a service mesh and nothing. The comparison is between a service mesh and a well-designed combination of ingress controllers, service discovery, and language-level libraries.
For organizations with fewer than 30 production services, where teams use one or two language stacks, and where compliance requirements stop at edge encryption, the simpler stack does most of what a mesh does at a fraction of the operational cost.
Ingress controllers handle inbound traffic, terminate TLS at the edge, and apply rate limiting and authentication. Internal service-to-service traffic uses platform DNS for discovery. Application frameworks provide retries, timeouts, and circuit breakers through libraries. Observability comes from application-level instrumentation using OpenTelemetry, exported to a centralized backend.
This stack does not give you mTLS between every internal service automatically. It does not give you the ability to mirror traffic across two versions without code changes. It does require teams to be disciplined about library upgrades and instrumentation. But it is operationally simpler by an order of magnitude, and for the workloads it is suited to, it works.
The decision is not whether to have any networking infrastructure. The decision is whether the additional capabilities of a mesh justify the additional operational cost.
The Threshold: When Service Mesh Pays Off
Three conditions, in combination, are the honest threshold for service mesh adoption. Organizations that meet all three benefit from a mesh. Organizations that meet only one or two usually do not.
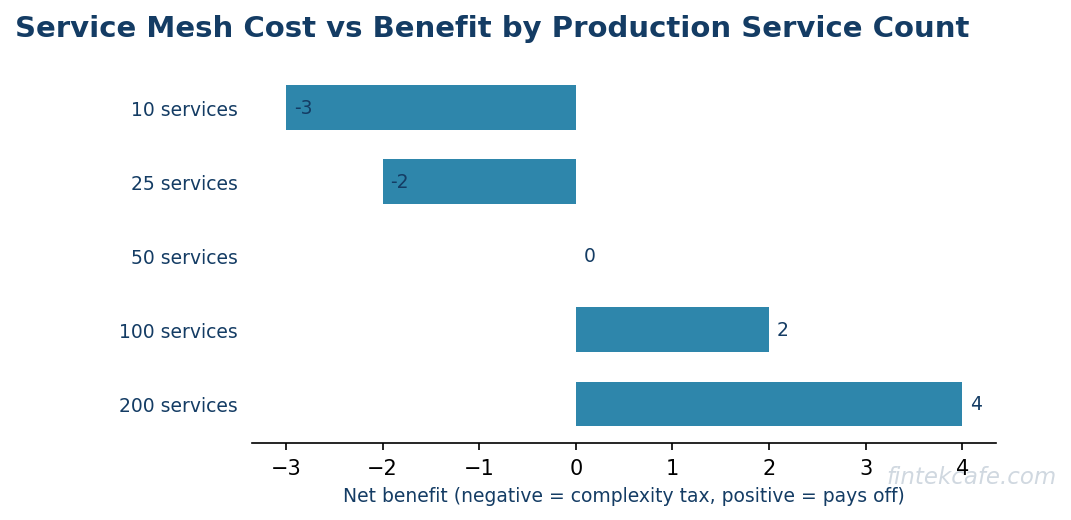
Condition One: Service Count Above 50
Below 50 services, the consistency benefits of a mesh are marginal. A platform team can keep 30 services on disciplined libraries and conventions without breaking. Above 50, especially across multiple language stacks, library drift becomes unmanageable. The mesh provides uniformity that humans cannot maintain at that scale.
Condition Two: Strict Compliance Requirements
Internal mTLS, fine-grained authorization policies, and audit logs of every service-to-service call are required for PCI DSS workloads, HIPAA workloads, financial regulator-supervised systems, and certain government deployments. Without these requirements, teams almost never use the security features of a mesh enough to justify the cost.
Condition Three: Mature Platform Team
A service mesh is platform infrastructure that requires platform engineering capacity. Two senior engineers fully owning the mesh, end to end, including upgrades and incident response, is the minimum for a single cluster. Multi-cluster deployments require more. Organizations without this capacity adopt a mesh and then suffer through years of half-working deployments and platform team turnover.
When all three conditions hold, a service mesh delivers on its promise. When any one is missing, the mesh becomes a complexity tax that pays no dividend.
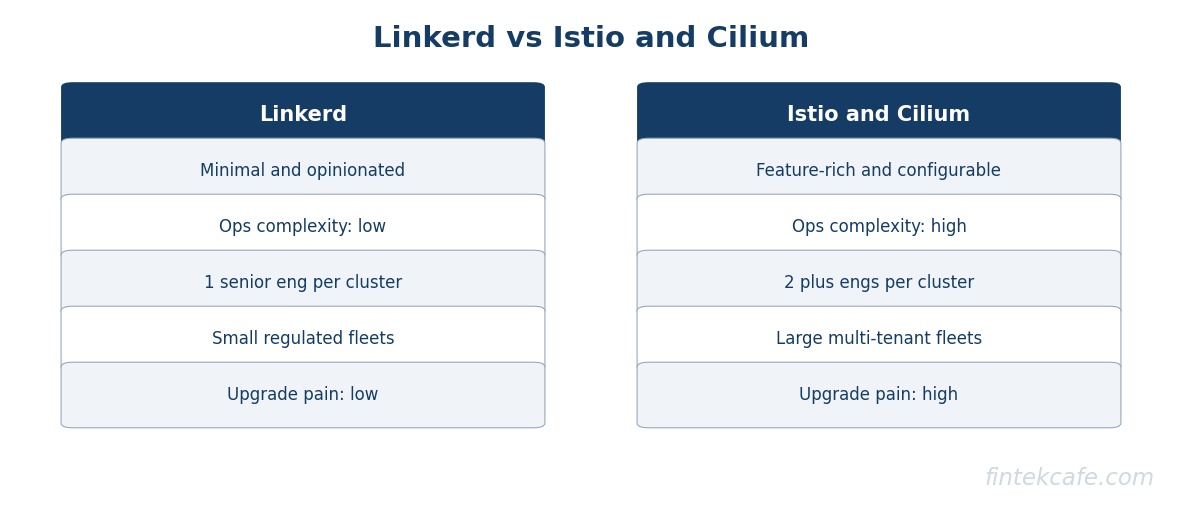
Comparing Istio, Linkerd, and Cilium
The three meshes that dominate the market in 2026 represent meaningfully different philosophies. The choice matters less for feature parity, which is closer than vendor marketing suggests, and more for the operational model your team can sustain.
Istio
Istio is the most feature-rich mesh and the most operationally demanding. It has the largest community, the deepest enterprise vendor support, and the most thorough integration with policy frameworks. It is also the most likely to bite you on upgrades. Major version upgrades have historically required careful coordination, and the configuration surface is large enough that mistakes are easy to make.
Istio is the right choice for organizations with mature platform engineering teams, complex policy requirements, and the budget to either pay a vendor for managed Istio or staff the operational burden internally.
Linkerd
Linkerd is the smallest, simplest mesh that still solves the core problems. Its proxy is built in Rust, uses a fraction of the memory of comparable proxies, and is operationally calm. Linkerd does fewer things than Istio, but the things it does, it does with less operational drama.
Linkerd is the right choice for organizations that want the core mesh benefits without committing to a heavyweight platform. It is also the right choice for teams that prioritize operational simplicity over feature breadth.
Cilium
Cilium is not strictly a service mesh in the traditional sidecar sense. It uses eBPF to implement networking, security, and observability at the kernel level, removing the per-pod sidecar entirely. The performance characteristics are excellent, and the operational model is fundamentally different from sidecar-based meshes.
Cilium is the right choice for organizations with strong Linux engineering capability that want to consolidate networking, security policy, and observability into a single layer. It is also the most forward-looking architecture in the space and likely the dominant model by the end of the decade.
Mesh Comparison Table
| Dimension | Istio | Linkerd | Cilium |
|---|---|---|---|
| Architecture | Sidecar (Envoy) or ambient | Sidecar (Linkerd-proxy) | eBPF, no sidecar |
| Operational complexity | High | Low | Medium |
| Resource overhead | Highest | Lowest among sidecars | Lowest overall |
| Feature breadth | Highest | Focused on essentials | Network plus security plus observability |
| Multi-cluster maturity | Highest | Good | Good |
| Best fit | Large platforms, deep policy needs | Teams that prioritize simplicity | Teams investing in eBPF |
| Vendor support | Many vendors | Fewer vendors | Growing vendor support |
The Operational Cost Nobody Discloses
The most under-discussed aspect of service mesh adoption is the ongoing operational cost. Vendor marketing focuses on installation and feature comparison. The honest cost shows up in the second year and beyond.
A production mesh in a single Kubernetes cluster requires a senior engineer dedicating roughly half their time on a steady state, with bursts to full time during upgrades and incidents. Multi-cluster meshes can require the equivalent of two full-time senior engineers per platform. This cost is on top of the existing platform team load for Kubernetes, ingress, DNS, and observability.
Beyond engineering time, the infrastructure overhead is non-trivial. Sidecar proxies consume CPU and memory that scale with traffic. A mesh covering 100 services with moderate traffic typically adds between 8 and 15 percent to the cluster's compute footprint. At cloud rates, this can run from tens of thousands to several hundred thousand dollars per year for a large deployment. Cilium's eBPF approach reduces this overhead substantially, which is a meaningful argument in its favor.
Upgrades are the most painful operational reality. Every major version of every mesh has had at least one upgrade cycle that required careful sequencing, configuration migration, and a rollback plan. Organizations on older versions of Istio, in particular, have learned that deferring upgrades creates a debt that compounds.
TCO Model for a Service Mesh
The total cost of ownership for a service mesh, expressed in concrete categories, is essential to the buy decision.
| Cost Category | Year 1 | Year 2 onward |
|---|---|---|
| Platform engineering (one half FTE) | High | Steady |
| Infrastructure overhead (8 to 15 percent of cluster) | Medium | Steady |
| Vendor or support contract | Medium to High | Same or higher |
| Training and onboarding | High | Low |
| Incident response time | High | Decreasing |
| Upgrade effort | Low | Medium, periodic |
A mid-sized organization with a single production cluster and a typical sidecar mesh spends roughly half a million dollars per year on the mesh once all costs are honestly accounted for. For organizations meeting the three threshold conditions, this is money well spent. For organizations that do not, it is the most expensive complexity tax in the cloud-native portfolio.
Decision Flowchart
The framework below produces a recommendation in under five questions.
Do you have more than 50 production services?
No -> Use ingress plus service discovery, no mesh
Yes -> Continue
Do you have strict compliance requirements for internal traffic (PCI, HIPAA, regulator-supervised)?
No -> Continue
Are most of your services on a single language stack?
Yes -> Library-based approach is sufficient
No -> Consider a lightweight mesh (Linkerd) for consistency
Yes -> Continue
Do you have a platform team with two or more senior engineers who can own the mesh?
No -> Defer mesh adoption until staffing is in place
Yes -> Continue
Do you have a strong Linux and eBPF engineering capability?
Yes -> Cilium
No -> Continue
Do you need maximum feature breadth and have vendor support?
Yes -> Istio
No -> Linkerd
When to Rip One Out
The harder conversation is not whether to adopt a mesh. It is what to do when you have one and it is not paying off. The signals that suggest a rip-out is worth considering are clear.
The platform team spends more time managing the mesh than enabling product teams. Engineers refer to the mesh as the most painful part of the stack. Major upgrades have been deferred multiple times because they are too risky. Most of the mesh's features are not used. Compliance requirements that originally justified adoption have changed or are now met through other controls.
A rip-out is a multi-quarter project. Application-level instrumentation must replace mesh observability. Ingress and service discovery must absorb the routing capabilities that were used. mTLS, if required, must be implemented in libraries or at the platform layer. The work is real, but the organizations that have completed rip-outs consistently report significant gains in platform team productivity and meaningful reductions in infrastructure cost.
The decision to rip out should be made with the same rigor as the original adoption: a written assessment, a clear migration plan, and executive sponsorship. The most common failure mode is rip-out by attrition, where the mesh is neither maintained nor removed, and it becomes a slow-burning operational liability.
What to Do in the Next 90 Days
Three actions cover most situations.
If your organization is currently considering a mesh, run the decision flowchart honestly. If you do not pass all three threshold conditions, do not adopt. Build the simpler stack instead. Revisit in 18 months as scale and compliance requirements evolve.
If your organization is currently running a mesh and it is working, document what you are using it for and what you are not. Concentrate the mesh's footprint on the workloads where it earns its cost. Resist the pressure to use every feature.
If your organization is currently running a mesh and it is not working, run a structured assessment. Identify which features are in use, which are not, and what the realistic alternatives look like. The decision to keep, scale back, or rip out should be made deliberately, not by drift.
Frequently Asked Questions
Is service mesh required for Kubernetes?
No. A large share of Kubernetes deployments run successfully without a service mesh. Kubernetes provides service discovery, basic load balancing, and network policies natively. A mesh adds capabilities on top, but it is an optional layer, not a requirement.
Can a service mesh replace an API gateway?
Partially, but not cleanly. API gateways handle north-south traffic with concerns like authentication, rate limiting, and developer portals that meshes do not address well. Most production architectures keep both: the gateway at the edge, the mesh inside the cluster.
How long does a typical mesh adoption take to reach steady state?
Between nine and eighteen months for a single cluster, longer for multi-cluster deployments. The first three months are installation and basic policy. The next six are migration of services and tuning. The remainder is hardening, upgrade testing, and team training. Organizations that expect a mesh to be production-ready in a quarter consistently regret the timeline.
Does sidecarless mesh (ambient mode, eBPF) eliminate the operational cost?
It reduces the resource overhead and eliminates some sidecar-specific failure modes. It does not eliminate the platform engineering capacity needed to operate the mesh. The hard problems of policy management, upgrades, and incident response remain.
What is the right way to evaluate competing meshes?
Run a structured proof of concept on representative workloads. Measure resource overhead, deployment complexity, upgrade behavior, and observability quality. Vendor benchmarks are not evidence; production telemetry is. Plan for a 60 to 90 day evaluation, not a one-week shootout.
Will eBPF make traditional service meshes obsolete?
Probably, on a long timeline. eBPF removes the sidecar overhead and unifies networking, security, and observability at the kernel level. The transition will take years, but architectural direction is clear. New deployments in 2026 should evaluate eBPF-based options seriously rather than assuming sidecars are the default.
Internal Reading
- Microservices vs Monoliths: An Executive Decision Framework
- DevOps Explained: A Guide for Business Leaders
- Cloud Computing Explained: An Executive Primer
- Infrastructure as Code: Why It Matters to the Business
- Executive Guide to Cloud Costs and FinOps
Related Articles

Legacy System Modernization: Strategies That Do Not Blow Up
A leader's guide to legacy modernization: the real triggers, the strategy ladder with honest costs, the strangler-fig default, and what AI changes.

Sovereign Cloud: The Compliance Product Hyperscalers Love to Sell
Sovereign cloud is a pricing tier more than a technology. What the offerings deliver versus imply, who needs which layer, and when the premium is worth paying.

Disaster Recovery Planning: What Technology Leaders Actually Need
Disaster recovery for technology leaders: RTO and RPO tiering, the four DR architecture patterns with honest cost multiples, testing, and cloud-era failures.