Edge Computing for Financial Services: When Low Latency Actually Justifies the Premium

Edge computing is the most pitched and least adopted infrastructure pattern in financial services. The vendor narrative since roughly 2021 has been that latency-sensitive workloads belong "at the edge" rather than in regional cloud, and that running compute at hundreds of points of presence rather than at a handful of cloud regions delivers a step-change in user experience. The narrative is half-right and is producing a procurement pattern in 2026 where most edge deployments do not deliver the cost-justified benefit the slide deck promised, and a small number do.
This article separates the two cases. It walks through what edge actually is in 2026, the three workloads in financial services where the latency math genuinely justifies the cost premium, the Cloudflare Workers versus AWS Wavelength versus Akamai EdgeWorkers comparison most architects need, the cost reality, a worked BNPL fraud-decisioning example at fifty milliseconds versus two hundred milliseconds, and a decision tree any infrastructure leader can apply.
What Edge Computing Actually Is in 2026
Edge computing is the execution of application logic at points of presence (PoPs) closer to the end user than the cloud region. A regional cloud deployment puts compute in one to three data centers per continent. An edge deployment puts compute in fifty to three hundred PoPs globally. The distance between the user and the compute, measured in milliseconds of network round trip, drops from the eighty to two hundred millisecond range typical of regional cloud to the ten to forty millisecond range typical of edge PoPs.
Three categories of edge platform dominate the 2026 landscape:
Edge runtime platforms (Cloudflare Workers, Vercel Edge Functions, Akamai EdgeWorkers, Fastly Compute@Edge, AWS CloudFront Functions and Lambda@Edge). Stateless or lightly-stateful JavaScript or WebAssembly runtimes that execute small functions at every PoP. The execution model is a milliseconds-long handler per request, with cold-start latency that the vendors have spent years compressing toward zero.
Edge zones from hyperscalers (AWS Wavelength, Azure Edge Zones, Google Distributed Cloud Edge). Cloud-region-equivalent compute and storage deployed inside or adjacent to telecom carrier networks. These give you full virtual machines and managed services, not just stateless functions, at PoPs in major metros.
Self-managed edge (Kubernetes at PoPs, MEC deployments inside telco infrastructure, on-premise compute at the branch). Used by the small number of organizations whose workload truly cannot be served by a managed edge platform.
The economic and operational reality differs by category. Edge runtime platforms are pay-per-invocation and operationally cheap to adopt. Hyperscaler edge zones are pay-per-hour at a meaningful premium over regional cloud (typically two to five times higher per equivalent capacity) with the same operational model. Self-managed edge carries the highest operational burden and is justified only by workloads that the managed options cannot serve.
The Latency Math: When It Actually Pays Back
The reason to pay the edge premium is to compress a specific latency component in a user journey, and the question that decides whether the spend is justified is whether that compression changes a measurable business outcome.
The three components of end-to-end latency on a typical financial-services request are network round trip from user to compute (twenty to two hundred milliseconds depending on geography and rail), compute time inside the application (single milliseconds for a fast path, hundreds of milliseconds for slow paths involving database reads or model inference), and network round trip back. Edge compresses the network component; it does not improve compute time.
For latency-bound workloads where the application is fast and the network is the dominant component, the edge gain is large. A request that took one hundred eighty milliseconds end-to-end at regional cloud, with one hundred sixty milliseconds in the two network legs and twenty in compute, can complete in sixty milliseconds at the edge. The user-perceptible improvement is real.
For compute-bound workloads where the application takes hundreds of milliseconds inside, the network compression is invisible to the user. A request that took eight hundred milliseconds because the application made three database calls and ran an ML inference saves twenty or thirty milliseconds by moving to edge, which a user cannot perceive.
The first filter on any edge proposal is whether the workload is latency-bound or compute-bound. Most enterprise workloads in 2026 are compute-bound. The case for edge is concentrated in the workloads where the compute itself is already milliseconds-fast and the network round trip is the visible cost.
The Three Financial-Services Workloads Where Edge Genuinely Justifies the Cost
1. Fraud Decisioning at the Point of Sale and Point of API
A card authorization, a BNPL approval, or a real-time payment must approve or decline in a small number of hundred milliseconds end-to-end. The card network's authorization round trip is typically under two seconds total; the issuer-side fraud decision inside that round trip has roughly two hundred to four hundred milliseconds of budget. A fraud decisioning system that adds another one hundred fifty milliseconds of network round trip on top of a hundred-millisecond model inference makes the budget tight and pushes the system into either accepting more fraud (by simplifying the model) or accepting more declines (by hitting the time budget).
Moving the fraud decisioning engine to edge PoPs collapses the network round-trip component. The model inference still costs what it costs, but the geographic budget pressure goes away. Fraud teams running this configuration report meaningful improvements in approval rates without raising fraud losses, because the model can be richer without exceeding the latency budget.
This is the highest-ROI edge use case in 2026 financial services. The latency budget is real, the business impact of pushing into the budget is measurable (approval rate, false-decline rate, fraud loss rate), and the edge premium is a small fraction of the value of incremental approved transactions on a high-volume payment business.
2. High-Frequency Trading Order Routing
The HFT use case is the canonical low-latency story and is the one that pre-dates the marketing term "edge." Trading firms have co-located servers next to exchange matching engines for two decades. The 2026 picture is that the well-funded firms run their own physical infrastructure inside exchange data centers, the managed cloud edge offerings cannot meet their latency targets, and the term "edge computing" in this context refers to a much more specialized practice than the consumer-facing edge runtime story.
For the broader institutional trading audience, including mid-tier asset managers and crypto exchanges, the managed cloud edge offerings (AWS Wavelength, in particular) are credible for execution algorithms that need single-digit-millisecond latency to a specific market but cannot justify physical co-location. This audience is small but the per-deployment economics are strong.
3. In-Game, Streaming, and Mobile-Embedded Payments
A payment inside a mobile game, a streaming subscription upsell, or an in-app micro-transaction lives under a latency budget the user perceives directly. A purchase flow that hesitates for half a second after the user taps "buy" produces a measurable conversion drop. Game studios, streaming platforms, and creator-economy companies care about this metric in a way that traditional retail merchants do not, because the user is in a flow state that the wait visibly disrupts.
Edge runtime functions are the right fit for this workload. The compute itself (charge a token, validate entitlement, return a receipt) is fast; the latency was the network. Cloudflare Workers, Vercel Edge, and similar platforms run the receipt and entitlement check at the user's nearest PoP and the rest of the payment stack (settlement, ledger, fraud) runs in the cloud region behind it.
The cost premium is small (edge function invocations are inexpensive at this volume) and the conversion lift is measurable. This is the second-strongest edge case in 2026.
Cloudflare Workers vs AWS Wavelength vs Akamai EdgeWorkers: The Comparison Architects Need
The three platforms in the title represent different points on the edge spectrum and target different workloads. The comparison below captures the practical 2026 picture.
| Dimension | Cloudflare Workers | AWS Wavelength | Akamai EdgeWorkers |
|---|---|---|---|
| Architecture | V8 isolates, JavaScript and WebAssembly | Full virtual machines and managed services inside telco metros | V8 isolates, JavaScript on the Akamai CDN |
| PoP count (2026) | 300+ locations | 30+ metro zones across major carrier networks | 4,000+ edge servers |
| Best fit | Lightweight per-request logic at global scale | Workloads needing full cloud services with low latency to telco-network users | CDN-adjacent edge logic for existing Akamai customers |
| Cold start | Sub-millisecond isolates | Same as regional cloud for VMs | Sub-millisecond isolates |
| State | Durable Objects, KV, D1, R2 | Full AWS services available in the zone | KV store, EdgeKV |
| Pricing model | Pay-per-request, very low per-invocation cost | Pay-per-hour at 2x to 5x regional cloud rates | Bundled with Akamai contract |
| Where it wins | Highest-volume low-latency reads and writes | Workloads requiring full cloud feature parity at edge | Akamai-native customers with CDN already in place |
| Where it loses | Long-running compute, stateful workloads needing full DB | Cost at large scale; limited geography vs Cloudflare | New customers without existing Akamai relationship |
A few practitioner notes. Cloudflare Workers wins the volume game on cost-per-request for stateless logic; if the workload fits the V8-isolate model it is hard to beat economically. AWS Wavelength is the right answer when you genuinely need a full AWS region's surface area at metro-level latency, which is a narrower use case than the marketing suggests. Akamai EdgeWorkers is competitive when you are already an Akamai CDN customer and the edge compute is a small extension of existing spend.
Vercel Edge Functions and Fastly Compute@Edge are also serious contenders that did not make the three-way table but should be in any short list. Vercel Edge runs on Cloudflare infrastructure under the hood and is the right answer when you are already deeply integrated with Vercel's deployment platform. Fastly Compute@Edge is a strong WASM-native option for teams that want WebAssembly as a first-class runtime rather than a feature retrofit.
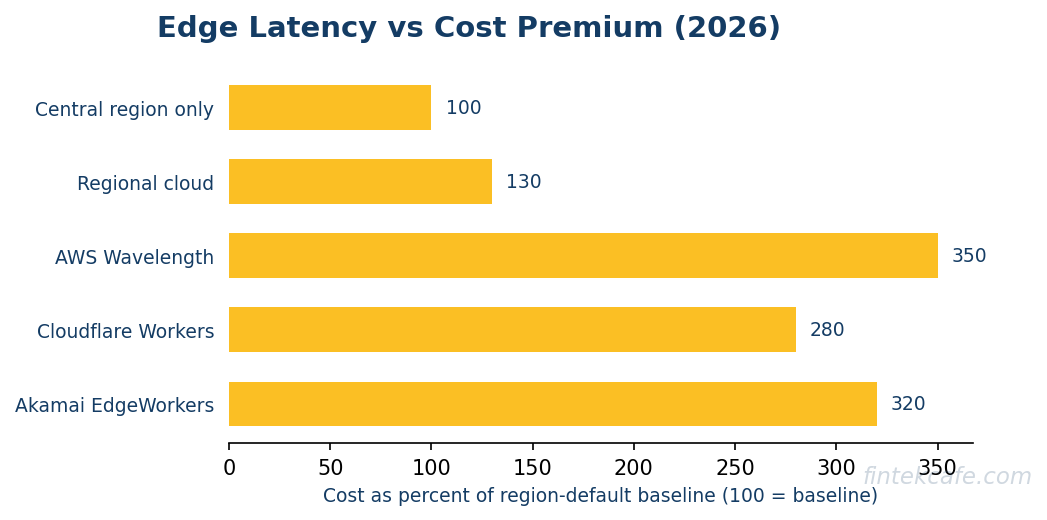
The Cost Premium, Quantified
A useful 2026 anchor: equivalent stateless API logic that costs roughly USD 100 per month to run on regional AWS Lambda or Cloud Functions will typically cost USD 30 to USD 80 per month on Cloudflare Workers for low-to-moderate request volumes, and USD 200 to USD 500 per month on AWS Wavelength for the equivalent feature set. The reason Cloudflare can undercut regional cloud on stateless workloads is the V8-isolate model, which packs orders of magnitude more handlers into the same infrastructure than a Lambda container model.
The pricing inversion holds for stateless, lightweight, request-response workloads. For stateful or heavy-compute workloads, the regional-cloud baseline is cheaper than any edge option.
Total cost of ownership for an edge deployment includes the platform cost (the variable above), the operational complexity (deploying and observing logic at hundreds of PoPs rather than three regions), and the data egress and synchronization cost between edge and origin (often the line item that surprises new edge customers). A realistic 2026 budget allocates fifteen to thirty percent operational overhead on top of platform cost for any meaningful edge deployment. We covered the broader infrastructure cost framing in our analysis of the real cost of AI infrastructure.
A Worked Example: BNPL Fraud Decisioning at 50ms vs 200ms
Consider a BNPL provider authorizing a transaction at checkout. The total latency budget for the approval flow is roughly five hundred milliseconds before the merchant's checkout page perceives a hang. The decomposition:
- Merchant integration round trip to BNPL API: 100 milliseconds
- BNPL API to fraud-decisioning engine: variable, the lever this analysis turns
- Fraud-decisioning compute: 80 milliseconds (model inference)
- BNPL API to issuing-bank or underwriting backend: 100 milliseconds
- Return to merchant: 100 milliseconds
In the regional-cloud configuration with the fraud engine in a single region, users far from that region see the API-to-fraud round trip at 150 to 200 milliseconds. End-to-end latency lands at 530 to 580 milliseconds, which is above budget for a meaningful share of geographic traffic. The operational response is to simplify the fraud model so it returns in 30 milliseconds, which accepts more fraud, or to time-box the call so it returns "approve" when slow, which also accepts more fraud.
In the edge configuration with the fraud engine deployed at PoPs near the user, the API-to-fraud round trip drops to 20 to 40 milliseconds. End-to-end latency lands at 400 to 420 milliseconds, comfortably under budget. The fraud model can be richer at no incremental latency cost, which moves both the approval rate up and the fraud-loss rate down.
Quantifying the impact on a hypothetical BNPL provider doing one million transactions per month at an average ticket of USD 120: a one-percentage-point improvement in approval rate (the typical range observed when latency budgets stop forcing model simplification) is twelve thousand approved transactions per month worth USD 1.44 million in transacted volume. The BNPL take rate on that volume is roughly USD 60,000 per month. The edge infrastructure spend that delivers the latency budget is on the order of USD 5,000 to USD 15,000 per month. The ROI is two orders of magnitude.
This is the worked-out version of "fraud decisioning at the point of API." It is also the cleanest worked example of when the edge premium is unambiguously worth paying.
The Decision Tree: Do You Actually Need This?
The questions below capture the choice the way infrastructure leaders are running it in 2026:
- Is the workload latency-bound or compute-bound? If end-to-end latency is dominated by the application's compute (database calls, model inference, complex business logic), edge does not help. Optimize the compute first.
- Is the latency budget tight enough that current performance is a measurable business problem? A measurable problem is a quantified conversion drop, a quantified approval-rate drop, a quantified user-experience score drop. A theoretical problem is "users would prefer it faster."
- Does the workload fit the stateless or lightly-stateful model? Edge runtime platforms are excellent at stateless request handling and at lightly-stateful workloads with eventually-consistent state. They are poor at heavy-stateful workloads, long-running compute, and complex multi-step transactions.
- What is the geographic distribution of the user base? Edge wins where users are far from the cloud region. Edge is roughly neutral where users are concentrated near the cloud region.
- Is the operational team prepared for edge observability? Debugging a function that runs at three hundred PoPs is operationally different from debugging a regional deployment. Teams without edge observability tooling discover the gap painfully.
If the answer to question 1 is "compute-bound" or to question 2 is "no measurable business problem," the edge proposal almost certainly does not justify the spend. We covered the broader cloud-vs-on-premise decision framework in our executive guide to cloud computing.
Common Failure Modes
Procuring edge as a marketing line item. The CEO returns from a conference convinced the company needs edge, and infrastructure ships an edge function that does not change any user-visible metric. The procurement is real and the value is not.
Skipping the compute-bound check. Teams deploy to edge before profiling the application and discover that the bottleneck was the database query, not the network. The edge spend is wasted.
Ignoring data-egress cost. A typical edge function reads or writes to an origin store on every request. The data transfer cost between edge and origin frequently dominates the function-invocation cost and is the line item that surprises teams in month two.
Over-investing in self-managed edge. A small number of organizations have built Kubernetes deployments at PoPs to "own the stack." The operational cost of running global Kubernetes is high enough that almost every team in 2026 is better served by a managed runtime platform.
Treating edge as a latency-only story. Edge is also a regulatory data-residency story (keeping EU user data inside EU PoPs), a fail-over story (when the cloud region goes down, edge PoPs continue serving cached responses), and a DDoS-mitigation story (edge platforms absorb traffic that would have melted regional load balancers). Teams that frame edge purely on latency miss the secondary benefits that often justify the spend even when the primary latency case is borderline.
Frequently Asked Questions
Is edge computing the same as a CDN?
Closely related but not identical. A content delivery network caches static assets at PoPs. Edge computing runs application logic at PoPs. The same vendors (Cloudflare, Akamai, Fastly) operate both, and the modern offerings blur the distinction. The operational difference that matters is that CDN content is identical for all users and edge function output is computed per request, which makes edge compute the right tool when the response depends on the user, the geography, or the request parameters.
Does edge work for AI inference?
Conditionally. Lightweight model inference (small embedding models, rules-based decisioning, traditional ML models under a few hundred megabytes of weights) runs well at edge PoPs. Large language model inference does not; the model weights are too large and the GPU footprint is too expensive to replicate at three hundred PoPs. The 2026 pattern is small models at the edge for fast decisioning and large models in the cloud region behind them, often with the edge function calling the regional model only when the edge model is uncertain.
How does edge interact with data-residency regulations?
Edge can be either a data-residency solution or a data-residency problem, depending on routing controls. A platform that routes EU user requests only to EU PoPs and stores EU data only in EU PoPs is a clean GDPR posture. A platform that routes globally without geographic controls is a regulatory problem. The major edge runtime platforms now offer explicit geographic routing controls and data-locality guarantees for regulated customers; the contract terms matter and should be reviewed by counsel.
What is the realistic latency improvement from edge?
For users far from the cloud region the improvement is typically eighty to one hundred fifty milliseconds of network round-trip reduction. For users near the cloud region the improvement is twenty to forty milliseconds. The aggregate user-experience impact depends on the geographic distribution; a U.S.-only product with users near East Coast or West Coast cloud regions sees modest improvement, while a globally-distributed product sees substantial improvement on the long tail of the user base.
Is the edge premium going to come down?
Cloudflare Workers, Vercel Edge, and similar platforms have been steadily reducing per-invocation pricing for several years. AWS Wavelength and similar hyperscaler-edge offerings have been roughly flat. The economic gravity is toward stateless-runtime edge becoming cheaper and toward hyperscaler-edge zones holding their premium. The 2027 to 2028 expectation is that the runtime-platform edge becomes cheaper than regional Lambda for stateless workloads, while hyperscaler edge zones stay at a meaningful premium because the underlying infrastructure cost is real.
Key Takeaways
- Edge computing is the execution of application logic at points of presence closer to the user than the cloud region. The economic gain is in network round-trip compression. It does not help compute-bound workloads, which describe most enterprise applications in 2026.
- Three financial-services workloads justify the edge premium today: fraud decisioning at the point of API, high-frequency trading order routing, and in-game or in-stream micro-payments. Each has a measurable latency budget that the regional-cloud baseline pushes against.
- Cloudflare Workers wins the stateless high-volume game on cost and reach; AWS Wavelength wins the workloads that need full cloud feature parity at metro-level latency; Akamai EdgeWorkers wins the existing-Akamai-customer extension case. Self-managed edge is rarely justified in 2026 outside HFT.
- Total cost of ownership includes platform cost, operational complexity, and data-egress between edge and origin. Teams that budget only the platform line item discover the operational and egress costs in month two.
- The decision tree starts with latency-bound versus compute-bound, then measurable business impact, then statefulness fit, then geographic distribution, then operational readiness. Skipping any of the five steps produces an edge deployment that does not change a user-visible metric.
Related reading on FinTekCafe
Related Articles

Legacy System Modernization: Strategies That Do Not Blow Up
A leader's guide to legacy modernization: the real triggers, the strategy ladder with honest costs, the strangler-fig default, and what AI changes.

Sovereign Cloud: The Compliance Product Hyperscalers Love to Sell
Sovereign cloud is a pricing tier more than a technology. What the offerings deliver versus imply, who needs which layer, and when the premium is worth paying.

Disaster Recovery Planning: What Technology Leaders Actually Need
Disaster recovery for technology leaders: RTO and RPO tiering, the four DR architecture patterns with honest cost multiples, testing, and cloud-era failures.