What Is a Data Lakehouse? A Decision-Maker's Guide
In 2020, Databricks introduced a term that caught on faster than most enterprise buzzwords: the data lakehouse. The pitch was simple. Data warehouses are expensive and rigid. Data lakes are cheap but chaotic. Why not build something that combines the reliability of a warehouse with the flexibility and cost structure of a lake?
Four years later, the lakehouse concept has gone from a marketing term to a genuine architectural pattern. Databricks, Snowflake, Google BigQuery, and Amazon all offer some version of it. Gartner now treats it as a recognized category. And organizations that moved early are reporting meaningful improvements in both cost and analytical capability.
But the concept remains poorly understood outside of data engineering teams. Most executives hear "lakehouse" and file it under "another thing the data team wants to buy." That is a mistake. The lakehouse decision is a strategic one, because it determines how your organization stores, governs, and derives value from its data for the next five to ten years.
This guide explains what a data lakehouse actually is, why the pattern emerged, when it makes sense, and how to evaluate whether your organization should adopt one.
The Problem the Lakehouse Solves

To understand lakehouses, you need to understand the two architectures they replace and why both fall short.
Data Warehouses: Reliable but Expensive
A data warehouse is a structured database optimized for analytical queries. Think of it as an extremely well-organized filing cabinet. Every piece of data has a defined schema (structure) before it goes in. This means queries are fast, governance is straightforward, and business intelligence tools work reliably.
The dominant players are Snowflake, Amazon Redshift, Google BigQuery, and, in older environments, Teradata and Oracle.
The problem with warehouses is cost and rigidity. Warehouses charge based on the volume of data stored and the compute power used to query it. As data volumes grow, costs scale proportionally. A mid-size company might spend 200,000 to 500,000 per year on Snowflake or Redshift. Large enterprises routinely spend millions.
The rigidity problem is more subtle. Warehouses require structured data. That works for transaction records, financial data, and CRM exports. It does not work for machine learning training data, log files, images, video, IoT sensor data, or any of the unstructured data types that modern analytics increasingly depends on. If your data science team wants to train a model on raw customer interaction logs, a warehouse forces them to transform that data into a structured format first, which is expensive, time-consuming, and often lossy.
Data Lakes: Flexible but Chaotic
A data lake is the opposite approach. It stores raw data in any format - structured, semi-structured, unstructured - at very low cost. The dominant implementation is cloud object storage: Amazon S3, Azure Data Lake Storage, or Google Cloud Storage.
The appeal is obvious. Storage costs pennies per gigabyte per month. You can dump everything in - CSV files, JSON logs, Parquet files, images, video - and figure out the structure later. Data science teams love lakes because they can access raw data without waiting for the data engineering team to transform and load it into a warehouse.
The problem is equally obvious. Without structure and governance, data lakes become data swamps. Files pile up with inconsistent naming conventions. Nobody knows which version of a dataset is current. There is no transactional consistency, meaning two people querying the same data might get different results if an update is in progress. Quality degrades. Trust erodes. Business analysts avoid the lake entirely and keep requesting warehouse access.
By 2019, a common pattern had emerged: organizations running both a data warehouse (for structured analytics and BI) and a data lake (for data science and raw storage), with an expensive and fragile ETL pipeline copying data between them. This "two-tier" architecture worked, but it meant duplicating data, maintaining two systems, and accepting that the warehouse and the lake would inevitably drift out of sync.
The Lakehouse: One System, Both Capabilities
A data lakehouse combines the low-cost, flexible storage of a data lake with the data management and query performance features of a data warehouse. Data stays in the lake (cloud object storage), but a metadata and governance layer on top provides the structure, ACID transactions, and query optimization that warehouses offer.
The key insight is that the problem with data lakes was never the storage layer. Object storage is excellent. The problem was the lack of a management layer. Lakehouses add that management layer without requiring you to move data into a separate, expensive warehouse system.
How a Data Lakehouse Actually Works
The lakehouse architecture has four core components.
1. Cloud Object Storage (The Foundation)
All data lives in cloud object storage - S3, ADLS, or GCS - in open file formats. The dominant formats are Apache Parquet for structured and semi-structured data and Delta Lake, Apache Iceberg, or Apache Hudi as table formats that add transactional capabilities on top of Parquet.
This is a critical architectural decision. Because data is stored in open formats on standard cloud storage, you are not locked into a single vendor's proprietary format. If you store data in Delta Lake format on S3, you can query it with Databricks, Spark, Trino, Dremio, or any tool that reads Delta. This is fundamentally different from a traditional warehouse, where your data lives in a proprietary format that only that vendor's engine can efficiently query.
2. Table Format Layer (The Transaction Engine)
Raw files in object storage have no concept of transactions, schema enforcement, or versioning. Table formats add these capabilities.
Delta Lake (created by Databricks) adds ACID transactions, schema enforcement, and time travel (the ability to query data as it existed at any point in the past) to data stored in Parquet files. It does this by maintaining a transaction log alongside the data files.
Apache Iceberg (created at Netflix) provides similar capabilities with a different approach to metadata management. Iceberg has gained significant momentum because it is vendor-neutral and supported by Snowflake, AWS, Google, and Dremio.
Apache Hudi (created at Uber) focuses specifically on efficient upserts and incremental processing, which is valuable for use cases like CDC (Change Data Capture) from transactional databases.
All three solve the same fundamental problem: making cloud object storage behave like a proper database for analytical workloads.
3. Query Engine (The Compute Layer)
The query engine reads data from storage, optimizes the query plan, and returns results. In a lakehouse, compute is decoupled from storage, meaning you can scale them independently. This is one of the key cost advantages.
Databricks uses Apache Spark and its proprietary Photon engine. Snowflake has extended its engine to query external tables on cloud storage. Trino (formerly PrestoSQL), Dremio, and Starburst provide open-source and commercial query engines that work across lakehouse implementations.
The separation of storage and compute means you pay for compute only when queries are running. A warehouse that sits idle overnight still costs money (or requires manual scaling). A lakehouse query engine that is not running costs nothing beyond the storage.
4. Governance and Catalog Layer (The Control Plane)
A data catalog tracks what data exists, where it lives, who owns it, and who has access. In a lakehouse, the catalog also manages table metadata, schema evolution, and access controls.
Unity Catalog (Databricks), AWS Glue Catalog, and open-source options like Apache Polaris and Nessie serve this function. The catalog is what prevents the lakehouse from degenerating into a swamp. Without it, you have a data lake with nice file formats. With it, you have a governed, queryable, trustworthy data platform.
Lakehouse vs Warehouse vs Lake: A Direct Comparison
| Capability | Data Warehouse | Data Lake | Data Lakehouse |
|---|---|---|---|
| Storage cost | High | Low | Low |
| Data types | Structured only | All types | All types |
| ACID transactions | Yes | No | Yes |
| Schema enforcement | Yes (schema-on-write) | No | Yes (flexible) |
| Query performance | Excellent | Poor to moderate | Good to excellent |
| Data governance | Built-in | Manual | Built-in |
| ML/AI support | Limited | Native | Native |
| Vendor lock-in | High | Low | Low to moderate |
| Real-time data | Limited | Good | Good |
When a Lakehouse Makes Sense

Not every organization needs a lakehouse. The pattern delivers the most value in specific situations.
You are paying for both a warehouse and a lake
If your organization maintains separate warehouse and lake infrastructure, a lakehouse consolidates them. The cost savings come from eliminating data duplication, reducing ETL pipeline complexity, and simplifying the overall architecture. Organizations that have made this consolidation report 30-50% reductions in total data infrastructure costs.
Your data science team is blocked by the data engineering team
In a traditional warehouse architecture, data scientists cannot access raw data without the engineering team first transforming and loading it. This creates a bottleneck. Lakehouse architectures let data science teams access raw data directly while still maintaining governance and quality controls.
You have growing volumes of unstructured or semi-structured data
If your analytical needs increasingly involve log files, JSON events, text data, images, or other non-tabular formats, a warehouse will not serve you well. A lakehouse handles all data types natively.
You want to avoid vendor lock-in
This is the sleeper advantage. Traditional warehouses store data in proprietary formats. Migration is expensive and painful. Lakehouses built on open table formats (Iceberg, Delta Lake) store data in vendor-neutral formats on standard cloud storage. If you decide to switch query engines or platforms, your data stays put.
When a Lakehouse Does NOT Make Sense
If your analytical needs are straightforward - BI dashboards, SQL queries on structured data, standard reporting - a modern cloud warehouse (Snowflake, BigQuery) is simpler to operate and equally cost-effective at moderate scale. The lakehouse adds architectural complexity that is not justified unless you have the data diversity, scale, or ML requirements that drive its advantages.
Similarly, if your organization is small (under 50 employees, under 1 TB of analytical data), the overhead of setting up and maintaining a lakehouse architecture is not worth it. Use a managed warehouse and revisit the decision when your data grows.
The Vendor Landscape in 2026
Databricks
Databricks coined the lakehouse term and has the most mature implementation. Its platform combines Delta Lake (table format), Apache Spark and Photon (query engines), Unity Catalog (governance), and MLflow (ML lifecycle management) into an integrated platform. Databricks is the strongest choice for organizations with significant ML and AI workloads alongside traditional analytics.
The trade-off: Databricks is an opinionated platform. It works best when you adopt its full stack. Organizations that want to pick and choose components may find Databricks less flexible than an Iceberg-based approach.
Snowflake
Snowflake started as a cloud warehouse and has been adding lakehouse capabilities aggressively. It now supports Apache Iceberg tables, external tables on cloud storage, and Snowpark for data science workloads. Snowflake's advantage is its SQL-first experience, which makes it approachable for analysts and BI teams.
The trade-off: Snowflake's lakehouse capabilities are newer and less mature than Databricks. Organizations with heavy ML workloads may find Snowflake's data science tooling less complete.
Open-Source and Multi-Vendor
Organizations that want maximum flexibility can build a lakehouse from open-source components: Apache Iceberg for the table format, Trino or Spark for query processing, and Apache Polaris or Nessie for catalog management. This approach avoids vendor lock-in but requires more engineering expertise to set up and maintain.
AWS, Google Cloud, and Microsoft Azure all offer managed services that support lakehouse patterns. AWS Lake Formation with Athena and Iceberg, Google BigLake with BigQuery, and Microsoft Fabric with OneLake each provide a cloud-native lakehouse implementation.
Cost Considerations

The most common mistake in lakehouse adoption is underestimating operational complexity while overestimating storage savings.
Storage costs will decrease. Moving from a warehouse to lakehouse storage (cloud object storage) typically reduces storage costs by 5-10x. On 10 TB of data, that might save 50,000 to 100,000 per year.
Compute costs may not decrease initially. Lakehouse query engines can be less efficient than purpose-built warehouse engines for certain workloads, particularly complex SQL joins on structured data. Optimization takes time and expertise.
Engineering costs increase in the short term. Setting up table formats, configuring catalogs, building data quality pipelines, and retraining analysts on new tools requires investment. Plan for 3-6 months of migration effort for a mid-size deployment.
Total cost of ownership typically improves over 18-24 months for organizations with diverse data types and growing data volumes. For organizations with purely structured data at moderate scale, the TCO advantage is less clear.
Implementation: A Realistic Roadmap
Phase 1: Foundation (Months 1-3)
Choose a table format (Iceberg is the safest default for vendor neutrality; Delta Lake if you are committing to Databricks). Set up cloud storage with proper access controls. Deploy a data catalog. Migrate one non-critical analytical workload to validate the architecture.
Phase 2: Migration (Months 3-9)
Move additional workloads from the existing warehouse to the lakehouse, starting with the least complex. Maintain the warehouse for production BI during migration. Build data quality checks that compare lakehouse results against warehouse results.
Phase 3: Consolidation (Months 9-18)
Once most workloads are running on the lakehouse, begin decommissioning warehouse infrastructure. Shift cost allocation from warehouse licenses to lakehouse compute. Enable data science teams to access the lakehouse directly.
Phase 4: Optimization (Ongoing)
Tune query performance. Implement data compaction and file optimization. Add real-time streaming ingestion. Expand governance policies as usage grows.
Key Takeaways

- A data lakehouse combines warehouse-grade reliability with data lake flexibility and cost, storing all data in open formats on cheap cloud storage while adding transactions, governance, and query performance on top.
- The pattern works best for organizations with diverse data types, growing volumes, ML/AI workloads, and concerns about vendor lock-in - not for every organization running SQL dashboards.
- Apache Iceberg has emerged as the leading open table format due to vendor-neutral support from Snowflake, AWS, Google, and the broader ecosystem.
- Total cost of ownership typically improves over 18-24 months, with immediate storage savings offset by short-term engineering investment.
- The biggest risk is architectural complexity - a lakehouse requires more engineering expertise than a managed warehouse, and the cost savings do not justify the complexity for small or simple workloads.
Frequently Asked Questions
What is the difference between a data lakehouse and a data warehouse?
A data warehouse stores structured data in a proprietary format optimized for SQL queries. A data lakehouse stores all data types (structured, semi-structured, unstructured) in open file formats on cloud object storage, with a metadata layer that provides warehouse-like capabilities including ACID transactions, schema enforcement, and governance. The lakehouse approach is typically cheaper at scale and more flexible, while warehouses offer simpler operations for purely structured workloads.
Is a data lakehouse just a data lake with extra features?
Functionally, yes - but the "extra features" are what matter. A data lake is raw storage with no management layer. A lakehouse adds transactional consistency (two users querying the same data get the same results), schema enforcement (data must conform to a defined structure), time travel (you can query historical versions), and governance (access controls, audit logs, lineage tracking). These capabilities are what make a lakehouse trustworthy enough for production analytics and regulatory compliance.
Should my organization switch from Snowflake to a lakehouse?
It depends on what problems you are trying to solve. If your Snowflake costs are manageable and your analytical needs are primarily structured SQL queries, switching adds complexity without clear benefit. If you are also maintaining a separate data lake, if your data science team is bottlenecked by the warehouse, or if vendor lock-in is a strategic concern, a lakehouse architecture is worth evaluating. Many organizations adopt a hybrid approach - keeping Snowflake for BI while adding Iceberg-based lakehouse capabilities for ML and unstructured data.
What is Apache Iceberg and why does it matter?
Apache Iceberg is an open table format that adds database-like capabilities to files stored in cloud object storage. It provides ACID transactions, schema evolution, partition evolution, and time travel for data stored in Parquet files. Iceberg matters because it is vendor-neutral - supported by Snowflake, Databricks, AWS, Google Cloud, Dremio, Trino, and Spark - which means your data is not locked into any single platform. This portability is the primary reason Iceberg has become the default choice for new lakehouse deployments.
How much does a data lakehouse cost compared to a traditional warehouse?
Storage costs are 5-10x cheaper in a lakehouse because data sits on cloud object storage rather than in a warehouse's managed storage. Compute costs vary by workload and optimization. Engineering costs increase in the short term due to migration and setup. Most mid-size organizations see a net positive ROI within 18-24 months. For a team processing 10-50 TB of analytical data, annual savings of 100,000 to 300,000 compared to a warehouse-only approach are realistic after the initial migration investment.
Can a lakehouse handle real-time data?
Yes. Modern lakehouse table formats support streaming ingestion. Delta Lake integrates with Spark Structured Streaming, and Iceberg works with Apache Flink and Kafka Connect. The latency is typically seconds to minutes, not the sub-second latency of purpose-built streaming databases, but sufficient for most real-time analytics, dashboarding, and ML feature engineering use cases. For true sub-second requirements (real-time fraud detection, live trading), organizations typically supplement the lakehouse with a specialized streaming layer.
Internal Link Suggestions
- Data Engineering Explained: Pipelines, Warehouses, and Why Your Data Team Is So Expensive - The foundational context on data infrastructure that makes lakehouse decisions clearer.
- Cloud Computing Explained: What Every Business Leader Needs to Know - Understanding cloud infrastructure is prerequisite to understanding where lakehouse storage lives.
- Infrastructure as Code: Why CFOs Should Care About How Software Gets Deployed - The deployment and governance practices that apply to lakehouse infrastructure management.
Related Articles

Why Your Digital Transformation Is Actually a People Problem
Digital transformation failures aren't technology failures. They're change management failures. Here's where transformations actually die — and it's not the tech.
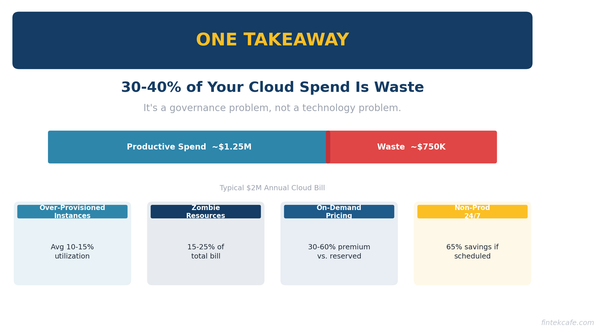
The Executive's Guide to Cloud Costs: Why Your Bill Is 40% Too High
Most companies overspend 30-40% on cloud. Learn why your bill is too high and how to fix it with this executive guide to cloud cost optimization.
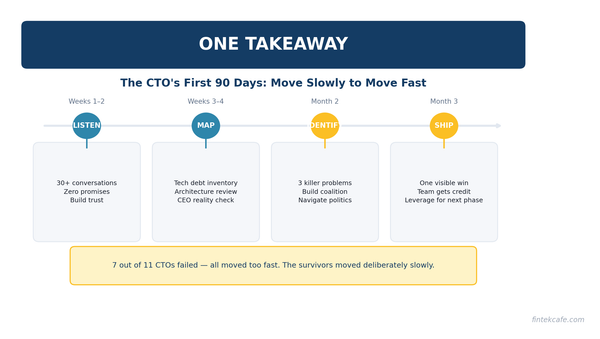
The CTO's First 90 Days: What Actually Matters
An opinionated playbook for new CTOs. Most fail because they change too much too fast. Here's the week-by-week approach that actually works.